前言:
终于把难度三整理完了,好多盲水印,然后难度中等,还有些需要特定应用解开
文件下载
通过网盘分享的文件:攻防世界MISC难度三.zip
链接: https://pan.baidu.com/s/1Ez-eMbAiE-gz4YAAvuP_Jw?pwd=6180 提取码: 6180 1.不确定,再看看
1.不确定,再看看
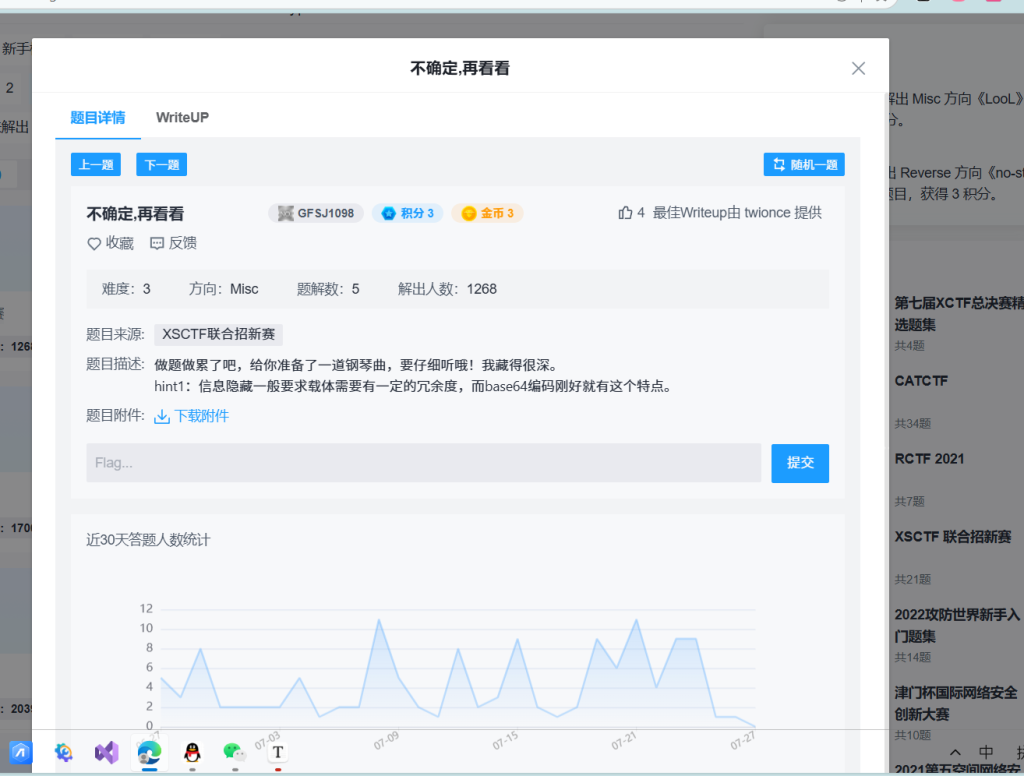
根据题目描述base64
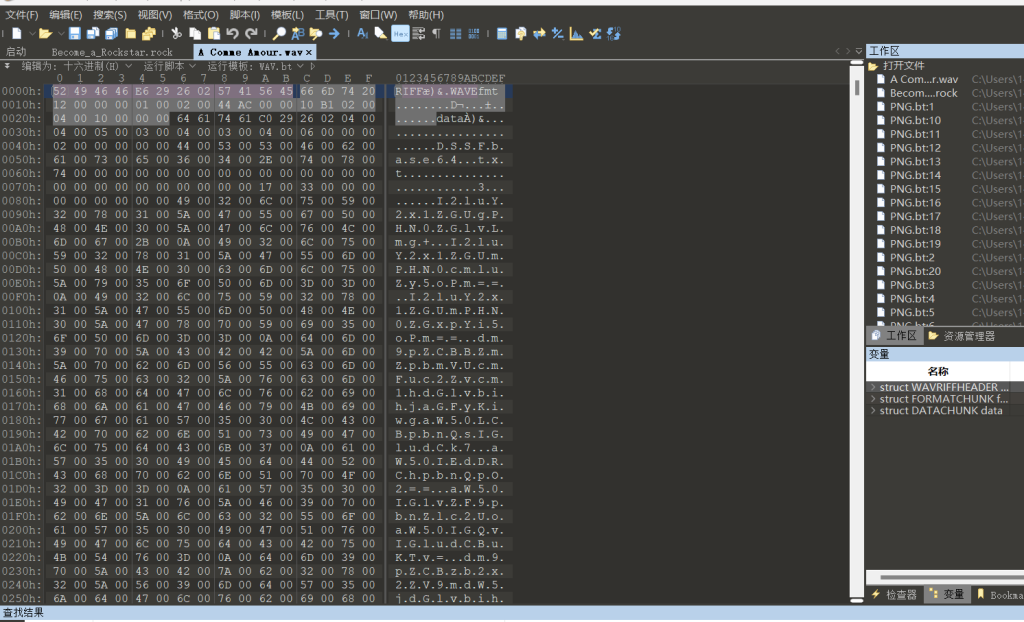
在我文件里面发现base64
提取base64
py3代码:
with open("A Comme Amour.wav", "rb") as f:
data = f.read()[0x86:0x2eea]
for i in range(0, len(data), 2):
print(chr(data[i]), end="")
I2luY2x1ZGUgPHN0ZGlvLmg+
I2luY2x1ZGUmPHN0cmluZy5oPm==
I2luY2x1ZGUmPHN0ZGxpYi5oPm==
dm9pZCBBZmZpbmVUcmFuc2Zvcm1hdGlvbihjaGFyKiwgaW50LCBpbnQsIGludCk7
aW50IEdDRChpbnQpO2==
aW50IG1vZF9pbnZlc2UoaW50IGQvIGludCBuKTv=
dm9pZCBzb2x2ZV9mdW5jdGlvbihjaGFyKik7
aW50IG1haW4odm9pZCk=
e2==
CXByaW50ZigiXG4qKioqKiphZmZpbmUgdHJhbnNmb3JtYXRpb24qKioqKipcbiIpOx==
CXdoaWxlICgxKW==
CXt=
CQl9cmludGYoIlxuUGxlYXNlIGVudGVyIHRoZSBmdW5jdGlvbiBzZXJpYW9gbnVtYmVyOlxuMC5FbmNyeXB0aW9uXG4xLkRlY3J5cHRpb25cbjIuU29sdXRpb24gZnVuY3Rpb25cbjMuRXhpdFxuUGxlYXNlIGNob29zZSBmdW5jdGlvbiIpO9==
CQlpbnQgZnVuY3Rpb247
CQlpbnQgYSA9IDA7
CQlpbnQgYiA9IDA7
CQljaGFyIHhbNF0gPSAiXDAiO+==
CQljaGFyIGNoWzEwMDBdID0gIlwwIjv=
CQljaGFyIHNvbHZlWzEwMDBdID0gIlwwIjt=
CQlzY2FuZl9zKCIlZCIsICZmdW5jdGlvbik7
CYlzd2l0Y2ggKGZ1bmN0aW9uKY==
CQl7
CQljYXNlIDA6
CQkJcHJpbnRmKCJQbGVhc2UgZW50ZXIgdGhlIGtleSB1c2VkIGZvciBlbmNyeXB0aW9uOigwPD1hLGI8PTI1KVxuIik7
CQkJc2NhbmZfcygiJWQsJWQiLCAmYS5gJmIpO5==
CYkJd2hpbGUgKEdDRChhKSAhPSAxKY==
CQkJe0==
CQkJCXByaW50ZigiUGxlYXNlIHJlIC1lbnRlciB0aGUga2V5OlxuIik7
CQkJCXByaW50ZigiUGxlYXNlIGVudGVyIHRoZSBrZXkgdXNlZCBmb3IgZW5jcnlwdGlvbjooMDw9YTw9MjUpXG4iKTv=
CQkJCXNjYW5mX3MoIiVkIi1gJmEpO1==
CWkJfW==
CQkJZmZtdXNoKHN0ZGluKTt=
CQkJcHJpbnRmKCJQbGVhc2UgZW50ZXIgdGhlIHBtYWludGV4dDoiKTt=
CQkJZ2V0c19zKGNoKTs=
CQkJQWZmaW5lVHJhbnNmb3JtYXRpb24oY2gvIGEvIGIvIGZ1bmN0aW9uKTv=
CQkJYnJlYWs7
CQljYXNlIDE6
CQkJcHJpbnRmKCJQbGVhc2UgZW50ZXIgdGhlIGtleSB1c2VkIGZvciBkZWNyeXB0aW9uOigwPD1hLGI8PTI1KVxuIik7
CQkJc2NhbmZfcygiJWQsJWQiLCAmYS2gJmIpO2==
CTkJd2hpbGUgKEdDRChhKSAhPSAxKT==
CQkJe0==
CQkJCXByaW50ZigiUGxlYXNlIHJlIC1lbnRlciB0aGUga2V5OlxuIik7
CQkJCXByaW50ZigiUGxlYXNlIGVudGVyIHRoZSBrZXkgdXNlZCBmb3IgZGVjcnlwdGlvbjooMDw9YTw9MjUpXG4iKTt=
CQkJCXNjYW5mX3MoIiVkIi3gJmEpO3==
CdkJfd==
CQkJZmZudXNoKHN0ZGluKTu=
CQkJcHJpbnRmKCJQbGVhc2UgZW50ZXIgdG8gYmUgZGVjcnl4dGVkOiIpO4==
CQkJZ2V0c19zKHNvbHZlKTt=
CQkJQWZmaW5lVHJhbnNmb3JtYXRpb24oc29udmUuIGEuIGIuIGZ1bmN0aW9uKTu=
CQkJYnJlYWs7
CQljYXNlIDI6
CQkJcHJpbnRmKCJQbGVhc2UgZW50ZXIgdGhlIGVxdWF0aW9uIGNvZWZmaWNpZW50OiB4LHksbSxuOlxuIik7
CQkJZmZudXNoKHN0ZGluKTu=
CQkJZ2V0c19zKHgpO1==
CQkJc29sdmVfZnVuY3Rpb24oeCk7
CQkJYnJlYWs7
CQljYXNlIDM6
CQkJcmV0dXJuIDA7
CQkJYnJlYWs7
CQlkZWZhdWx0Op==
CQkJcHJpbnRmKCJQbGVhc2UgZW50ZXIgdGhlIGNvcnJlY3QgbnVtYmVyIik7
CQkJYnJlYWs7
CQl9
CX0=
fW==
dm9pZCBBZmZpbmVUcmFuc2Zvcm1hdGlvbihjaGFyIGNoW10sIGludCBhLCBpbnZgYiwgaW50IGZ1bmN0aW9uKZ==
e2==
CWludCBpID0gMDv=
CWlmIChmdW5jdGlvbiA9PSAwKZ==
CXu=
CQl3aGlsZSAoY2hbaV0gIT0gJ1wwJyl=
CQl7
CdkJaWYgKChjaFtpXSA+PSAnYScpICYmIChjaFtpXSA8PSAneicpKd==
CQkJe3==
CQkJCWNoW2ldID0gJ2EnICsgKCgoY2hbaV0gLSAnYScpICogYSArIGIpICUgMjYpO8==
CckJfc==
CVkJaWYgKChjaFtpXSA+PSAnVScpICYmIChjaFtpXSA8PSAnWicpKV==
CQkJe8==
CQkJCWNoW2ldID0gJ0EnICsgKCgoY2hbaV0gLSAnQScpICogYSArIGIpICUgMjYpO9==
CXkJfX==
CQkJaSsrO9==
CQl9
CQlwcmludGYoImNpcGhlcnRleHTvvJolcyIvIGNoKTv=
CX0=
CWVsc2UgaWYgKGZ1bmN0aW9uID09IDEp
CXv=
CQl3aGlsZSAoY2hbaV0gIT0gJ1wwJyk=
CQl7
CckJaWYgKChjaFtpXSA+PSAnYScpICYmIChjaFtpXSA8PSAneicpKc==
CQkJex==
CQkJCWlmICgoY2hbaV0gLSAnYScgLSBiKSA8IDAp
CQkJCQljaFtpXSA9ICdhJyArICgoY2hbaV0gLSAnYScgLSBiKSAqIG1vZF9pbnZlc2UoYSwgMjYpKSAlIDI2ICsgMjY7Ly/orqHnrpfmnLogbiVtPW4tbShuL20pOyjotJ/mlbDml7blkJHkuIrlj5bmlbQp
CQkJCWVsc2V=
CQkJCQljaFtpXSA9ICdhJyArICgoY2hbaV0gLSAnYScgLSBiKSAqIG1vZF9pbnZlc2UoYS/gMjYpKSAlIDI2O/==
CWkJfW==
CZkJaWYgKChjaFtpXSA+PSAnZScpICYmIChjaFtpXSA8PSAnWicpKZ==
CQkJe2==
CQkJCWlmICgoY2hbaV0gLSAnQScgLSBiKSA8IDAp
CQkJCQljaFtpXSA9ICdBJyArICgoY2hbaV0gLSAnQScgLSBiKSAqIG1vZF9pbnZlc2UoYSwgMjYpKSAlIDI2ICsgMjY7
CQkJCWVsc2X=
CQkJCQljaFtpXSA9ICdBJyArICgoY2hbaV0gLSAnQScgLSBiKSAqIG1vZF9pbnZlc2UoYS4gMjYpKSAlIDI2O4==
CdkJfd==
CQkJaSsrO9==
CQl9
CQlwcmludGYoInBsYWludGV4dCA6JXMiLCBjaCk7
CX2=
fV==
aW50IEdDRChpbnQgYSl=
e8==
CWludCBudW1iZXIgPSAyNju=
CWludCByID0gYSAlIG51bWJlcjt=
CWludCBmbGFnID0gMDu=
CXdoaWxlIChyICE9IDAp
CXt=
CQlhID0gbnVtYmVyO1==
CQludW1iZXIgPSByO8==
CQlyID0gYSAlIG51bWJlcjv=
CX1=
CWlmIChudW1iZXIgIT0gMSn=
CXt=
CQlyZXR1cm4gZmxhZzs=
CX0=
CWVsc2X=
CXs=
CQlyZXR1cm4gZmxhZyArIDE7
CX1=
fW==
aW50IG1vZF9pbnZlc2UoaW50IGesIGludCBuKe==
e2==
CWludCBhO3==
CWludCBiOy==
CWludCBxOx==
CWludCByO3==
CWludCB1ID0gMDv=
CWludCB2ID0gMTt=
CWludCB0Ow==
CWEgPSBuOw==
CWIgPSAoZCA+PSAwKSA/IChkICUgbikgOiAtKGQgJSBuKTs=
CXdoaWxlIChiICE9IDAp
CXs=
CQlxID0gKGludClhIC8gYjs=
CQlyID0gYSAtIGIgKiBxOw==
CQlhID0gYjs=
CQliID0gcjs=
CQl0ID0gdjs=
CQl2ID0gdSAtIHEgKiB2Ow==
CQl1ID0gdDs=
CX0=
CWlmIChhICE9IDEpIHJldHVybiAwOw==
CXJldHVybigodSA8IDApID8gdSArIG4gOiB1KTs=
fQ==
dm9pZCBzb2x2ZV9mdW5jdGlvbihjaGFyIHhbXSk=
ew==
CWludCBpLCBqOw==
CWludCBhLCBiOyA=
CWludCBmbGFnID0gMDs=
CWludCB0aW1lID0gMTs=
CWludCBrXzEgPSAwLCBrXzIgPSAwOw==
CWludCBsZW5ndGg7
CWxlbmd0aCA9IHN0cmxlbih4KTs=
CWludCB2YXJ5WzEwMF07
CW1lbXNldCh2YXJ5LCAwLCBzaXplb2YodmFyeSkpOw==
CWZvciAoaSA9IDA7IGkgPCBsZW5ndGg7IGkrKyk=
CXs=
CQlpZiAoeFtpXSA+PSAnYScgJiYgeFtpXSA8PSAneicp
CQl7
CQkJdmFyeVtpXSA9IHhbaV0gLSAnYSc7
CQl9
CQlpZiAoeFtpXSA+PSAnQScgJiYgeFtpXSA8PSAnWicp
CQl7
CQkJdmFyeVtpXSA9IHhbaV0gLSAnQSc7
CQl9
CX0=
CXdoaWxlIChmbGFnICE9IDIp
CXs=
CQlrXzEgPSAwOw==
CQlmb3IgKGkgPSAwOyBpIDwgdGltZTsgaSsrKQ==
CQl7
CQkJa18yID0gMDs=
CQkJZm9yIChqID0gMDsgaiA8IHRpbWU7IGorKyk=
CQkJew==
CQkJCWtfMisrOw==
CQkJCWlmICgoKHZhcnlbMl0gKyAyNiAqIGtfMSAtIHZhcnlbM10gLSAyNiAqIGtfMikgJSAodmFyeVswXSAtIHZhcnlbMV0pKSA9PSAwKQ==
CQkJCQlmbGFnKys7
CQkJCWlmICgoKHZhcnlbMV0gKiAodmFyeVsyXSArIDI2ICoga18xKSAtIHZhcnlbMF0gKiAodmFyeVszXSArIDI2ICoga18yKSkgJSAodmFyeVsxXSAtIHZhcnlbMF0pKSA9PSAwKQ==
CQkJCQlmbGFnKys7
CQkJCWlmIChmbGFnID09IDIp
CQkJCQlicmVhazs=
CQkJfQ==
CQkJa18xKys7
CQl9
CQl0aW1lKys7
CX0=
CWEgPSAoKHZhcnlbMl0gKyAyNiAqIGtfMSAtIHZhcnlbM10gLSAyNiAqIGtfMikgLyAodmFyeVswXSAtIHZhcnlbMV0pKTs=
CWIgPSAoKHZhcnlbMV0gKiAodmFyeVsyXSArIDI2ICoga18xKSAtIHZhcnlbMF0gKiAodmFyeVszXSArIDI2ICoga18yKSkgLyAodmFyeVsxXSAtIHZhcnlbMF0pKTs=
CXdoaWxlIChiIDwgMCk=
CXs=
CQliID0gYiArIDI2Ow==
CX0=
CS8vIGIgPSBiICUgMjY7
CS8vIGEgPSBhICsgMjY7
CXByaW50ZigiazE9JWRcbiIsIGtfMSk7
CXByaW50ZigiazI9JWRcbiIsIGtfMik7
CXByaW50Zigic2VjcmV0IGtleSBhID0gJWRcbiIsIGEpOw==
CXByaW50Zigic2VjcmV0IGtleSBiID0gJWRcbiIsIGIpOw==
fQ==
Ly8geHR3c3tmbmlrX2lrX3h3eWNfeHR3c190ZWV5X3J3a2MhfQ==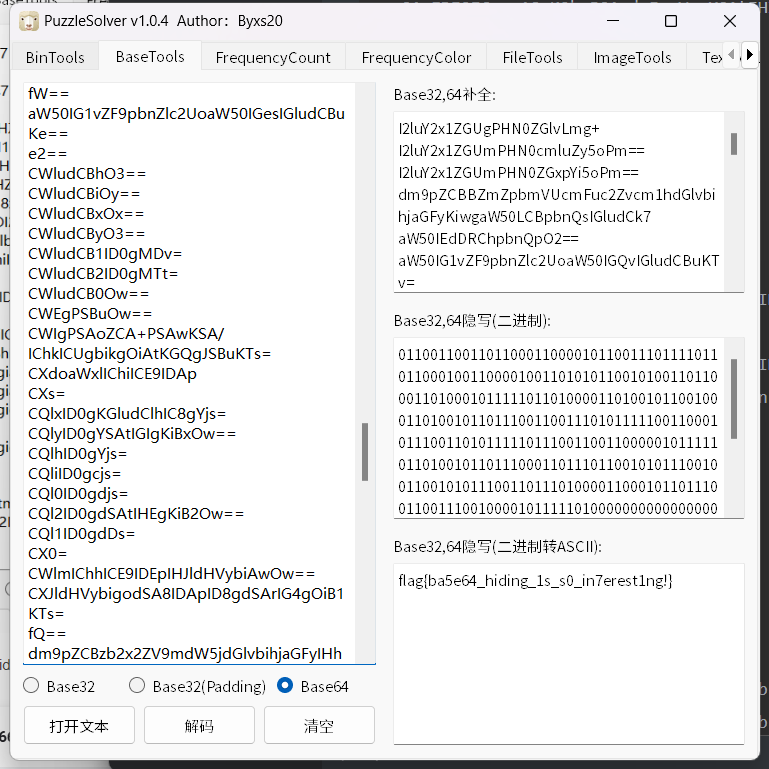
flag{ba5e64_hiding_1s_s0_in7erest1ng!}2.[中等] QR1
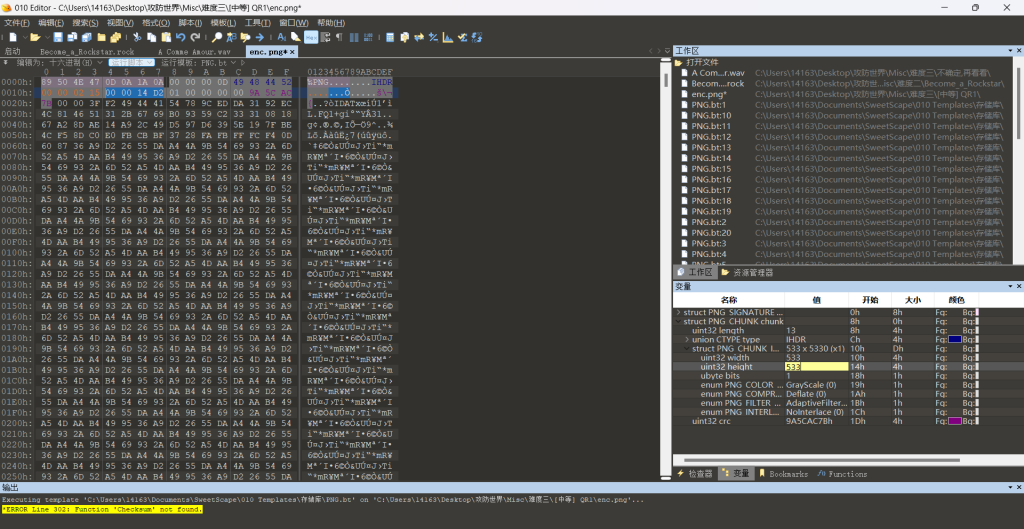
图片放大发现二维码

图片太大了调小一点
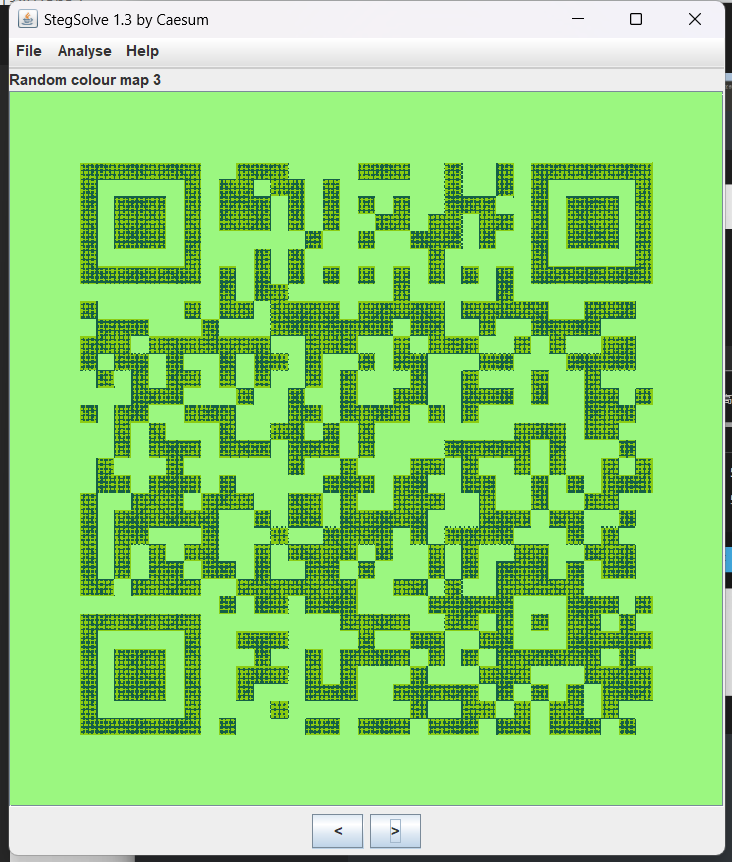
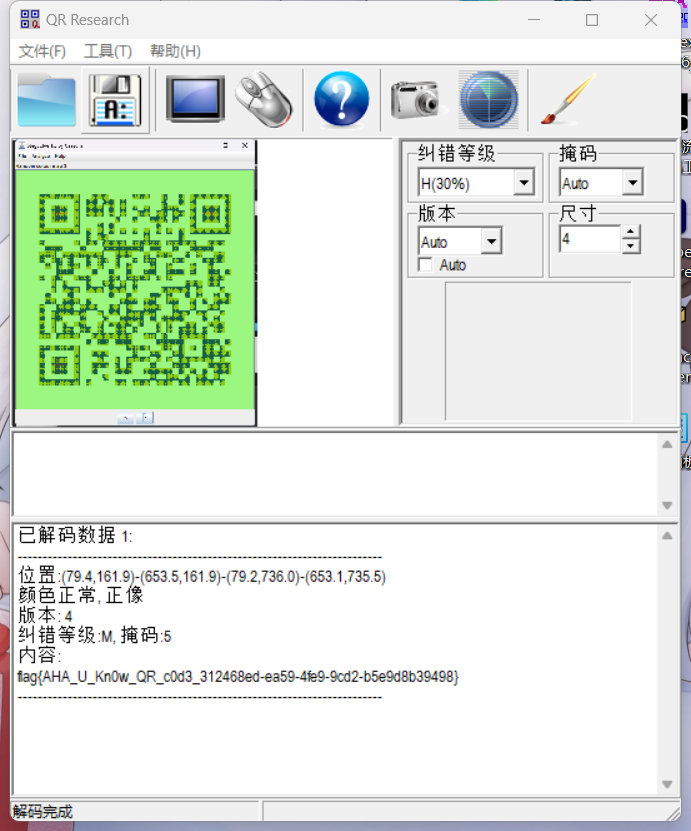
flag{AHA_U_Kn0w_QR_c0d3_312468ed-ea59-4fe9-9cd2-b5e9d8b39498}3.Misc文件类型
题目:
3436455341425F554573444242514141
41414941416C64434658714F7737634B
4141414143594141414149414141415A
6D78685A7935306548524C79306C4D72
7A5A49536B303253457778546B6B304D
6A5130546A593353445531534573784E
544D3054374A494E552B7A7241554155
45734241685141464141414141674143
56304956656F374474776F414141414A
674141414167414A4141414141414141
414167414141414141414141475A7359
57637564486830436741674141414141
41414241426741477845666B39697132
41456245522B54324B725941514A462B
34725971746742554573464267414141
41414241414541576741414145344141
4141414141是个十六进制
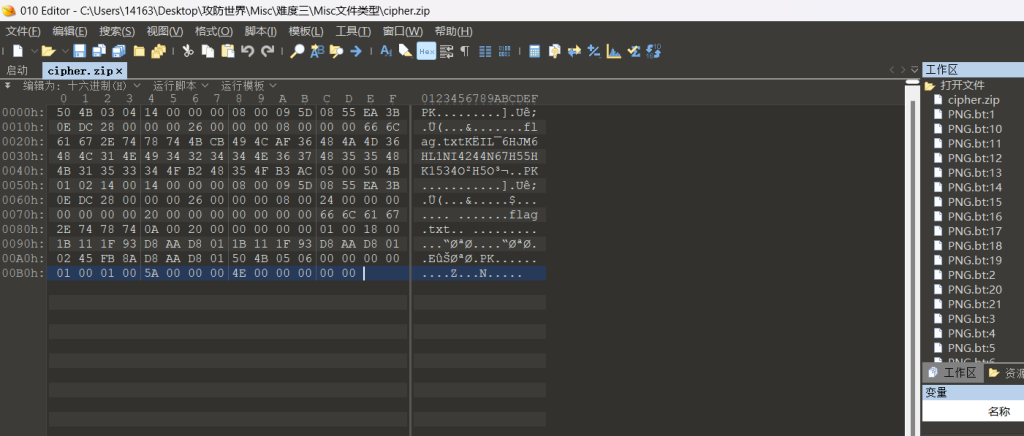
010导入十六进制
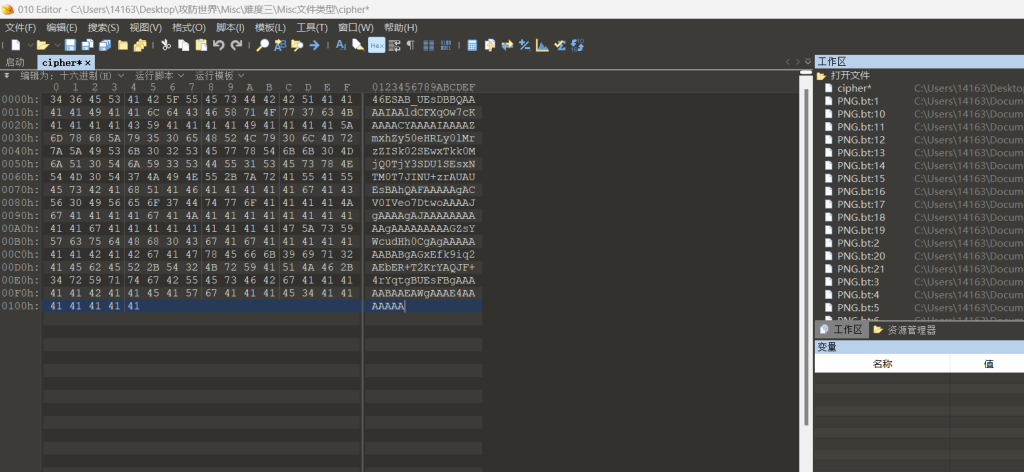
46ESAB
将这个反转得到
BASE64
UEsDBBQAAAAIAAldCFXqOw7cKAAAACYAAAAIAAAAZmxhZy50eHRLy0lMrzZISk02SEwxTkk0MjQ0TjY3SDU1SEsxNTM0T7JINU+zrAUAUEsBAhQAFAAAAAgACV0IVeo7DtwoAAAAJgAAAAgAJAAAAAAAAAAgAAAAAAAAAGZsYWcudHh0CgAgAAAAAAABABgAGxEfk9iq2AEbER+T2KrYAQJF+4rYqtgBUEsFBgAAAAABAAEAWgAAAE4AAAAAAA==后面要两个等号
base解码为hex为十六进制(Hex)
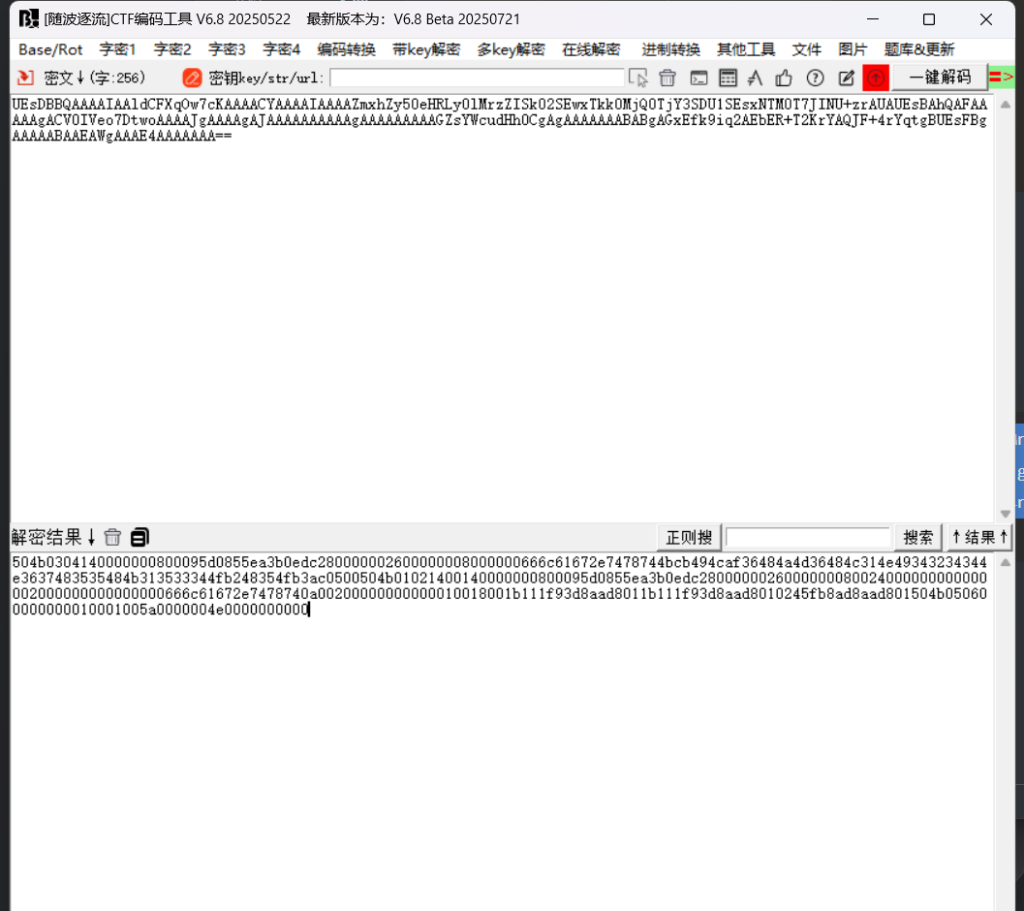
504b0304140000000800095d0855ea3b0edc280000002600000008000000666c61672e7478744bcb494caf36484a4d36484c314e49343234344e3637483535484b313533344fb248354fb3ac0500504b01021400140000000800095d0855ea3b0edc2800000026000000080024000000000000002000000000000000666c61672e7478740a00200000000000010018001b111f93d8aad8011b111f93d8aad8010245fb8ad8aad801504b050600000000010001005a0000004e0000000000
保存zip文件就行
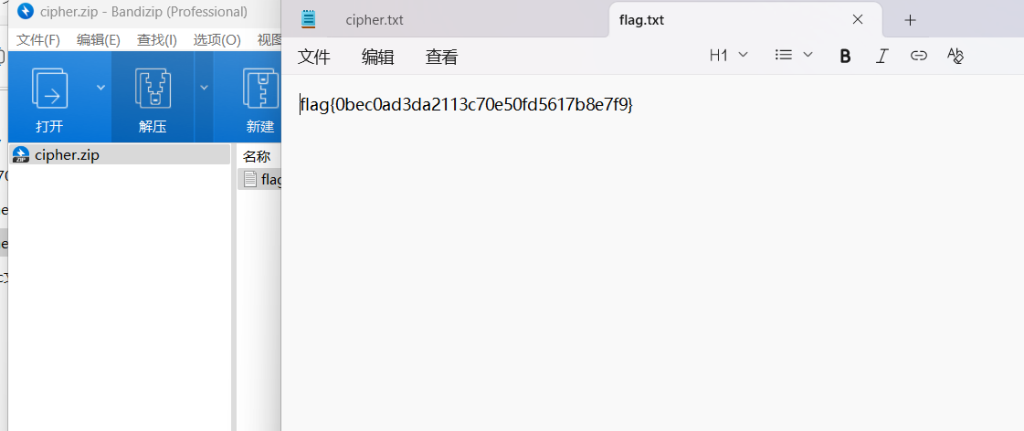
flag{0bec0ad3da2113c70e50fd5617b8e7f9}4.打开电动车
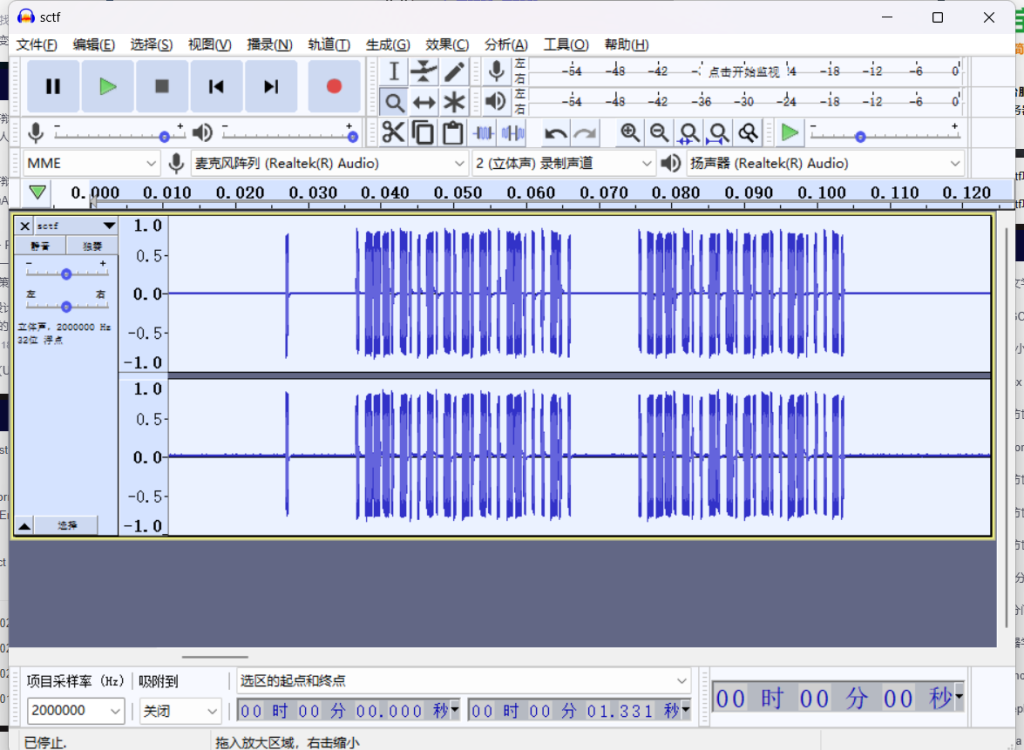
根据细宽可以判断为0和1
00111010010101010011000100011101001010101001100010不对
注意上图中框出来的这段音频,一共有 25 个明显的起伏,你再对比一下无线遥控模块发出的信号。一下子就能看出这是 PT224X 格式的(20 位地址位 + 4 位数据位 + 1 个停止码)。
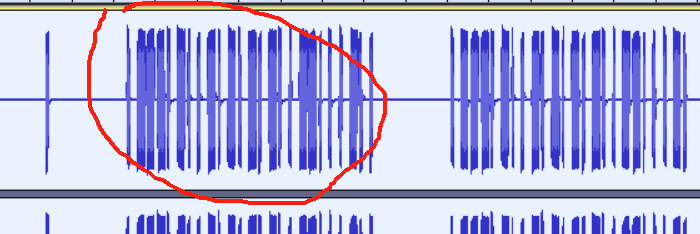
01110100101010100110然后结合音频文件 flag 为:
sctf{01110100101010100110}5.Py-Py-Py
.pyc
直接反编译
#!/usr/bin/env python
# visit https://tool.lu/pyc/ for more information
import sys
import os
import hashlib
import time
import base64
fllag = '9474yeUMWODKruX7OFzD9oekO28+EqYCZHrUjWNm92NSU+eYXOPsRPEFrNMs7J+4qautoqOrvq28pLU='
def crypto(string, op, public_key, expirytime = ('encode', 'ddd', 0)):
ckey_lenth = 4
if not public_key or public_key:
pass
public_key = ''
key = hashlib.md5(public_key).hexdigest()
keya = hashlib.md5(key[0:16]).hexdigest()
keyb = hashlib.md5(key[16:32]).hexdigest()
if ckey_lenth:
if not (op == 'decode' or string[0:ckey_lenth]) and hashlib.md5(str(time.time())).hexdigest()[32 - ckey_lenth:32]:
pass
keyc = ''
cryptkey = keya + hashlib.md5(keya + keyc).hexdigest()
key_lenth = len(cryptkey)
if not op == 'decode' or base64.b64decode(string[4:]):
pass
string = '0000000000' + hashlib.md5(string + keyb).hexdigest()[0:16] + string
string_lenth = len(string)
result = ''
box = list(range(256))
randkey = []
for i in xrange(255):
randkey.append(ord(cryptkey[i % key_lenth]))
for i in xrange(255):
j = 0
j = (j + box[i] + randkey[i]) % 256
tmp = box[i]
box[i] = box[j]
box[j] = tmp
for i in xrange(string_lenth):
a = j = 0
a = (a + 1) % 256
j = (j + box[a]) % 256
tmp = box[a]
box[a] = box[j]
box[j] = tmp
result += chr(ord(string[i]) ^ box[(box[a] + box[j]) % 256])
if op == 'decode':
if (result[0:10] == '0000000000' or int(result[0:10]) - int(time.time()) > 0) and result[10:26] == hashlib.md5(result[26:] + keyb).hexdigest()[0:16]:
return result[26:]
return None
return keyc + base64.b64encode(result)
if __name__ == '__main__':
while None:
flag = raw_input('Please input your flag:')
if flag == crypto(fllag, 'decode'):
print('Success')
break
continue
continue
return None
解不出
修改代码
py3:
import hashlib
import time
import base64
fllag = "9474yeUMWODKruX7OFzD9oekO28+EqYCZHrUjWNm92NSU+eYXOPsRPEFrNMs7J+4qautoqOrvq28pLU="
def crypto(string, op='encode', public_key='ddd', expirytime=0):
ckey_lenth = 4
public_key = public_key and public_key or ""
key = hashlib.md5(public_key.encode()).hexdigest()
keya = hashlib.md5(key[0:16].encode()).hexdigest()
keyb = hashlib.md5(key[16:32].encode()).hexdigest()
keyc = ckey_lenth and (
op == "decode" and string[0:ckey_lenth] or hashlib.md5(str(time.time()).encode()).hexdigest()[
32 - ckey_lenth:32]) or ""
cryptkey = keya + hashlib.md5((keya + keyc).encode()).hexdigest()
key_lenth = len(cryptkey)
if op == "decode":
# 解码时直接使用字节数据
string = base64.b64decode(string[4:])
else:
# 编码时生成字符串
string = "0000000000" + hashlib.md5((string + keyb).encode()).hexdigest()[0:16] + string
string = string.encode() # 转换为字节数据
string_lenth = len(string)
result = b"" if op == "decode" else ""
box = list(range(256))
randkey = []
for i in range(255):
randkey.append(ord(cryptkey[i % key_lenth]))
for i in range(255):
j = 0
j = (j + box[i] + randkey[i]) % 256
tmp = box[i]
box[i] = box[j]
box[j] = tmp
for i in range(string_lenth):
a = j = 0
a = (a + 1) % 256
j = (j + box[a]) % 256
tmp = box[a]
box[a] = box[j]
box[j] = tmp
if op == "decode":
result += bytes([string[i] ^ box[(box[a] + box[j]) % 256]])
else:
result += chr(string[i] ^ box[(box[a] + box[j]) % 256])
if op == "decode":
if result[0:10] == b"0000000000" or int(result[0:10]) - int(time.time()) > 0:
if result[10:26] == hashlib.md5(result[26:] + keyb.encode()).hexdigest()[0:16].encode():
return result[26:].decode()
return
else:
return keyc + base64.b64encode(result.encode()).decode()
if __name__ == "__main__":
decrypted_flag = crypto(fllag, "decode")
print("Decrypted flag:", decrypted_flag)
提示Steganography隐写
工具下载地址
AngelKitty/stegosaurus: A steganography tool for embedding payloads within Python bytecode.
我的py版本太高了,所有基本就是这样

所以你要下载一个低版本的py,我就不下载了
Flag{HiD3_Pal0ad_1n_Python}6.肥宅快乐题
是个游戏不想下载 flashplayer
使用看看wp
直接配图
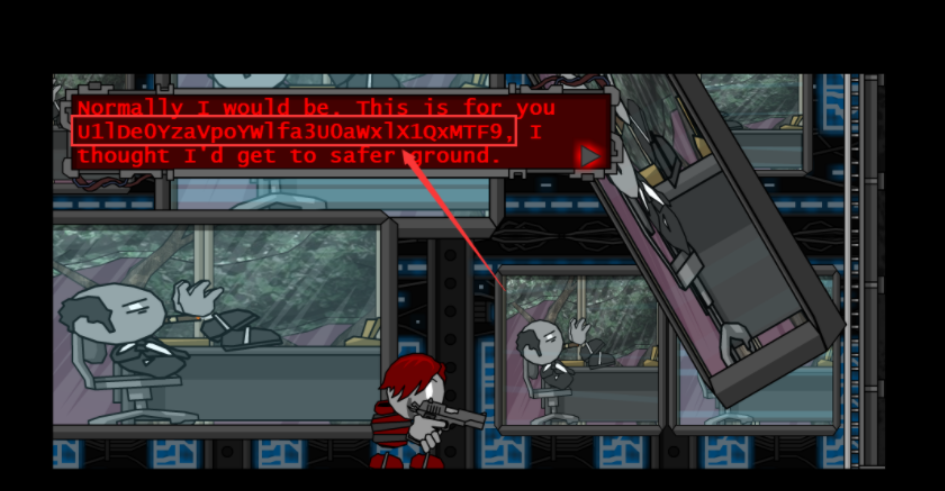
注意他的提示,npc的对话
于是我们逐帧分析(到第57帧)
U1lDe0YzaVpoYWlfa3U0aWxlX1QxMTF9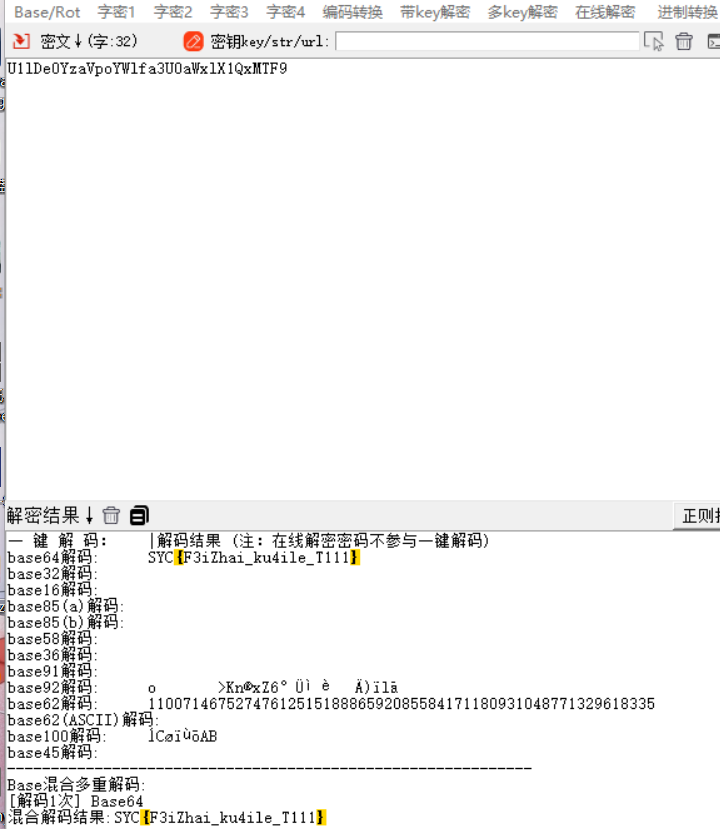
SYC{F3iZhai_ku4ile_T111}7.3-1
010看就是一个rar压缩包
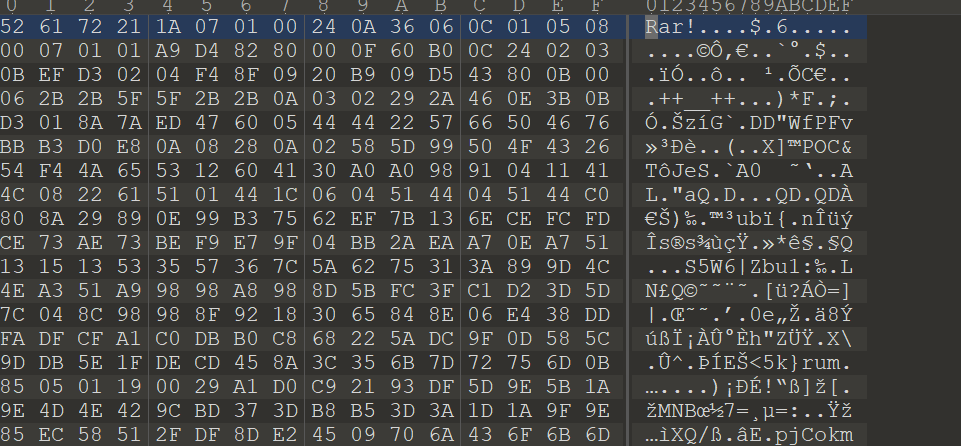
7-zip打开
改一下后缀
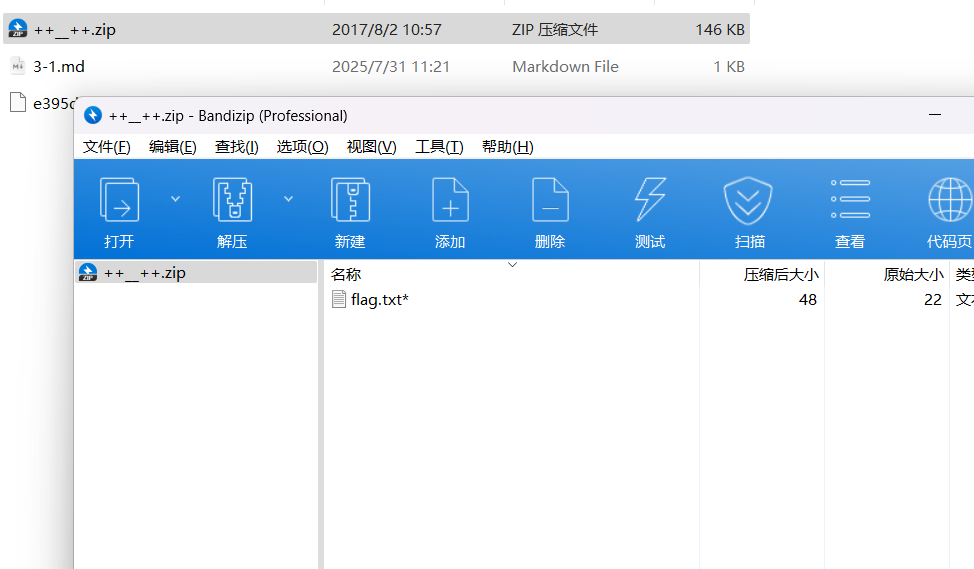
有密码
然后不加文件头看看
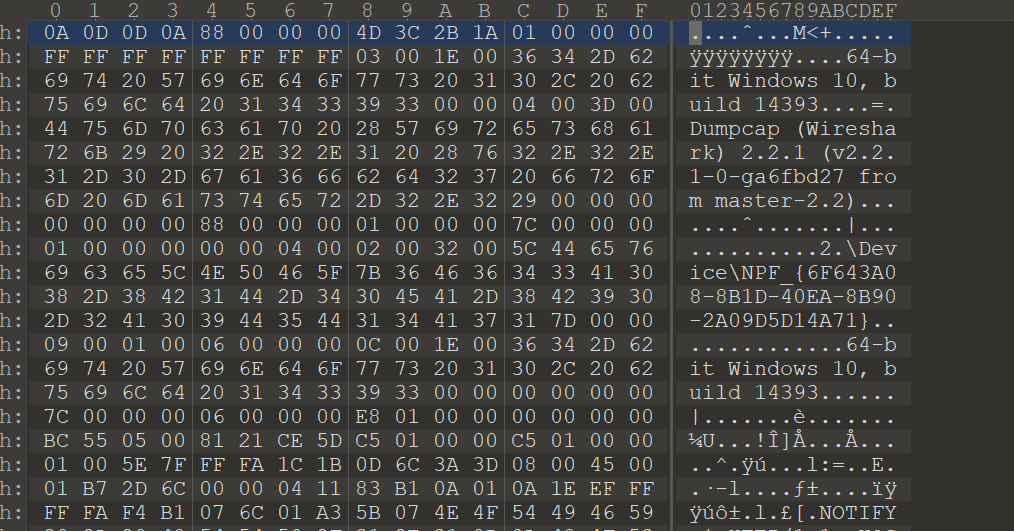
发现是一个流量包
加后缀.pcap
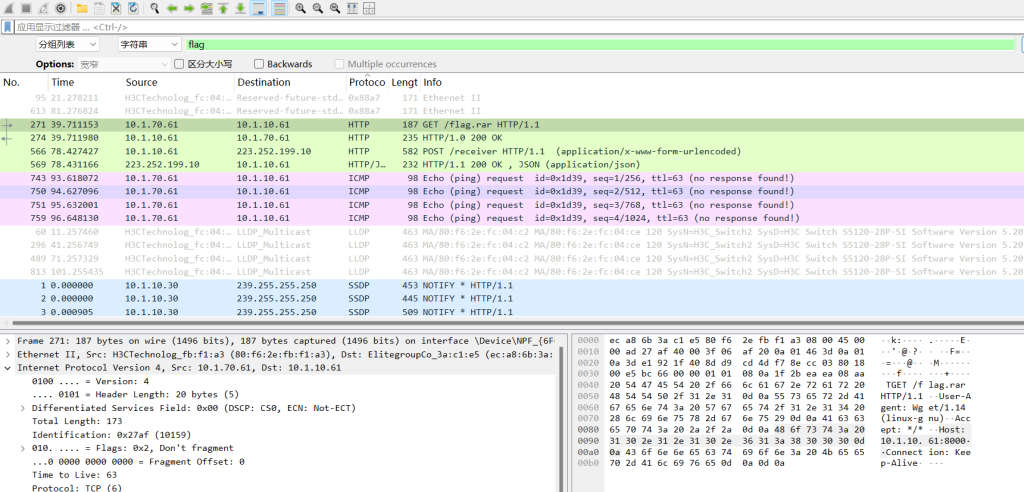
可以发现flag.rar
其实上面我们添加一个.zip就可以出来
但是要找到密码,应该在流量包里面
TCP流第六个流量包可以看到加密的数据
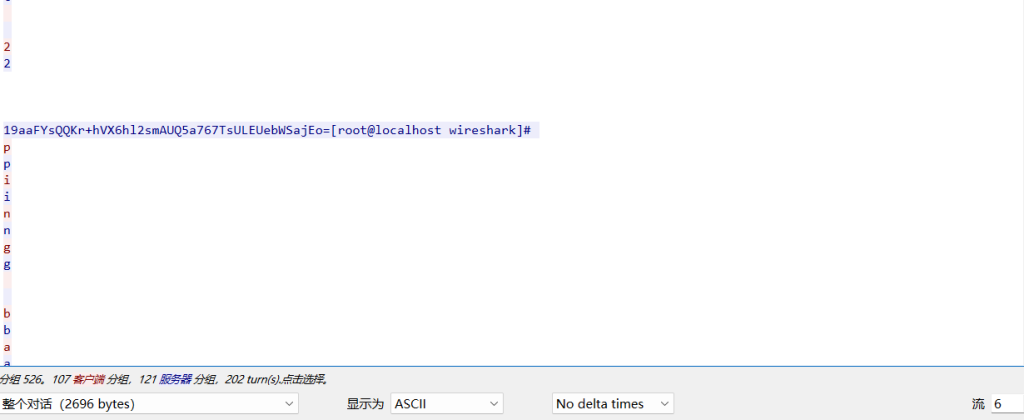
加密和解密都使用相同的IV Key和偏移量是:QWERTYUIOPASDFGH CBC模式 长度为16字节,符合AES-128的要求。
19aaFYsQQKr+hVX6hl2smAUQ5a767TsULEUebWSajEo=
解密步骤:
创建AES-CBC解密器
执行解密
去除填充的null字节
字节解码为字符串
原始数据: "hello" → 字节: b'hello'
↓
填充: b'hellox0bx0b...' (PKCS#7填充)
↓
AES加密 + IV → 加密数据
↓
Base64编码 → 最终密文
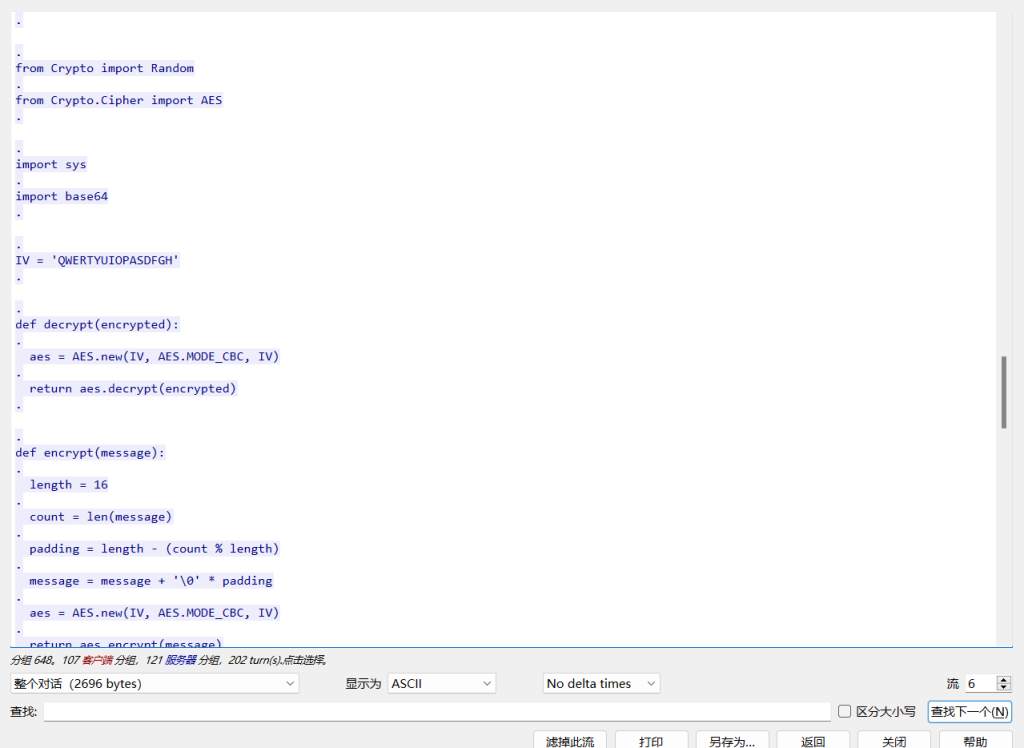
解密py3:
# coding:utf-8
from Crypto import Random
from Crypto.Cipher import AES
import sys
import base64
IV = b'QWERTYUIOPASDFGH' # 注意:在Python3中需要转换为bytes
def decrypt(encrypted):
aes = AES.new(IV, AES.MODE_CBC, IV)
decrypted = aes.decrypt(encrypted)
# 去除填充的null字符
return decrypted.rstrip(b'x00').decode('utf-8')
def encrypt(message):
length = 16
# 在Python3中,需要将字符串转换为bytes
message = message.encode('utf-8')
count = len(message)
padding = length - (count % length)
message = message + b'' * padding
aes = AES.new(IV, AES.MODE_CBC, IV)
return aes.encrypt(message)
# 提供的base64编码的密文
encrypted_base64 = '19aaFYsQQKr+hVX6hl2smAUQ5a767TsULEUebWSajEo='
# 解码base64并解密
encrypted_data = base64.b64decode(encrypted_base64)
decrypted_text = decrypt(encrypted_data)
print("解密结果:", decrypted_text)
# 测试加密解密功能
if __name__ == '__main__':
test_str = 'this is a test'
print("原始字符串:", test_str)
encrypted_example = encrypt(test_str)
encrypted_b64 = base64.b64encode(encrypted_example).decode('utf-8')
print("加密后(base64):", encrypted_b64)
decrypted_example = decrypt(encrypted_example)
print("解密后:", decrypted_example)解密步骤:
- 创建AES-CBC解密器
- 执行解密
- 去除填充的null字节
- 字节解码为字符串
Base64密文 → Base64解码
↓
分离IV和加密数据
↓
AES解密 → 带填充的数据
↓
去除填充 → 原始字节
↓
解码 → 原始字符串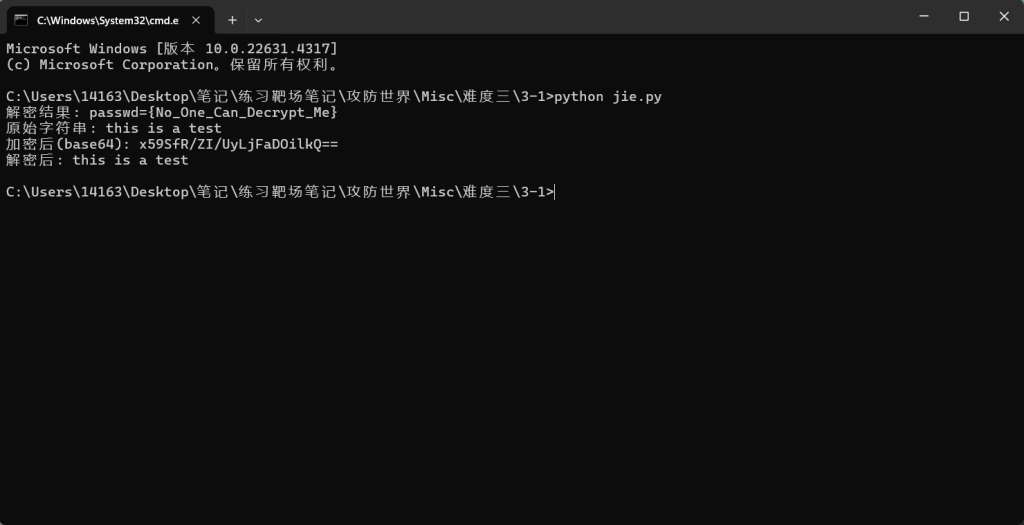
密码:No_One_Can_Decrypt_Me

WDCTF{Seclab_CTF_2017}8.4-1
一张图片
直接binwalk
有一个压缩包
lsb zsteg等不管用可能是盲水印stgesolve混合没有什么东,所以是盲水印
chishaxie/BlindWaterMark: 盲水印 by python 下载地址

bwm.py是py2的环境 bwmforpy3.py是py3的环境
python bwmforpy3.py decode --oldseed day1.png day2.png day3.png
image<day1.png> + image(encoded)<day2.png> -> watermark<day3.png>
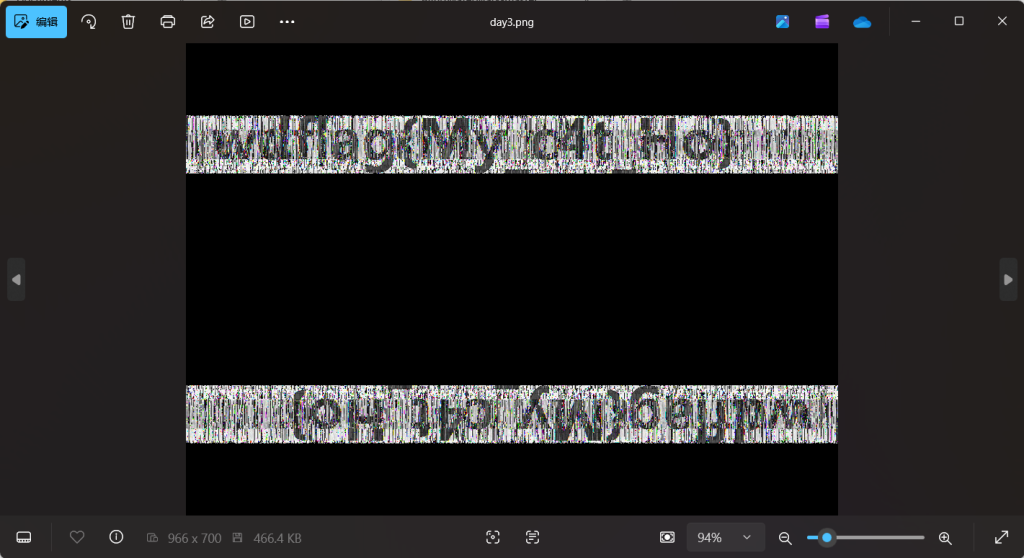
wdflag{My_c4t_Ho}9.5-1
010看了不知道是什么文件,
binwalk什么也没有
file命令识别文件类型的工具

也不知道是什么,看看wp
发现整体文件异或了某个密钥
需要下载下载xortool
pip install xortool
hellman/xortool: A tool to analyze multi-byte xor cipher下载链接
xortool.py
一个用于进行异或分析的工具:
- 猜测密钥长度(基于相等字符数数)
- 猜关键(基于最常见角色的知识)
官方文档
无论是开发还是构建这个仓库,都需要诗歌。
poetry build
pip install dist/xortool*.whl用法
xortool
A tool to do some xor analysis:
- guess the key length (based on count of equal chars)
- guess the key (base on knowledge of most frequent char)
Usage:
xortool [-x] [-m MAX-LEN] [-f] [-t CHARSET] [FILE]
xortool [-x] [-l LEN] [-c CHAR | -b | -o] [-f] [-t CHARSET] [-p PLAIN] [-r PERCENT] [FILE]
xortool [-x] [-m MAX-LEN| -l LEN] [-c CHAR | -b | -o] [-f] [-t CHARSET] [-p PLAIN] [-r PERCENT] [FILE]
xortool [-h | --help]
xortool --version
Options:
-x --hex input is hex-encoded str
-l LEN, --key-length=LEN length of the key
-m MAX-LEN, --max-keylen=MAX-LEN maximum key length to probe [default: 65]
-c CHAR, --char=CHAR most frequent char (one char or hex code)
-b --brute-chars brute force all possible most frequent chars
-o --brute-printable same as -b but will only check printable chars
-f --filter-output filter outputs based on the charset
-t CHARSET --text-charset=CHARSET target text character set [default: printable]
-p PLAIN --known-plaintext=PLAIN use known plaintext for decoding
-r PERCENT, --threshold=PERCENT threshold validity percentage [default: 95]
-h --help show this help
Notes:
Text character set:
* Pre-defined sets: printable, base32, base64
* Custom sets:
- a: lowercase chars
- A: uppercase chars
- 1: digits
- !: special chars
- *: printable chars
Examples:
xortool file.bin
xortool -l 11 -c 20 file.bin
xortool -x -c ' ' file.hex
xortool -b -f -l 23 -t base64 message.enc
xortool -b -p "xctf{" message.enc
xortool -r 80 -p "flag{" -c ' ' message.enc示例1
# xor is xortool/xortool-xor
tests $ xor -f /bin/ls -s "secret_key" > binary_xored
tests $ xortool binary_xored
The most probable key lengths:
2: 5.0%
5: 8.7%
8: 4.9%
10: 15.4%
12: 4.8%
15: 8.5%
18: 4.8%
20: 15.1%
25: 8.4%
30: 14.9%
Key-length can be 5*n
Most possible char is needed to guess the key!
# 00 is the most frequent byte in binaries
tests $ xortool binary_xored -l 10 -c 00
...
1 possible key(s) of length 10:
secret_key
# decrypted ciphertexts are placed in ./xortool_out/Number_<key repr>
# ( have no better idea )
tests $ md5sum xortool_out/0_secret_key /bin/ls
29942e290876703169e1b614d0b4340a xortool_out/0_secret_key
29942e290876703169e1b614d0b4340a /bin/ls最常见的用法是只传递加密文件和最常用字符(通常为二进制文件为00,文本文件为20)——长度会自动选择:
tests $ xortool tool_xored -c 20
The most probable key lengths:
2: 5.6%
5: 7.8%
8: 6.0%
10: 11.7%
12: 5.6%
15: 7.6%
20: 19.8%
25: 7.8%
28: 5.7%
30: 11.4%
Key-length can be 5*n
1 possible key(s) of length 20:
an0ther s3cret xdd key这里,密钥长度超过了默认的32个限制:
tests $ xortool ls_xored -c 00 -m 64
The most probable key lengths:
3: 3.3%
6: 3.3%
9: 3.3%
11: 7.0%
22: 6.9%
24: 3.3%
27: 3.2%
33: 18.4%
44: 6.8%
55: 6.7%
Key-length can be 3*n
1 possible key(s) of length 33:
really long s3cr3t k3y... PADDING所以,如果自动解密失败,你可以校准:
- (
-m)尝试更长键的最大长度 - (
-l)选择长度以观察一些有趣的键 - (
-c)是产生右明文的最常见字符
示例2
我们收到一条用Base64编码并用未知密钥进行异或的消息。
# xortool message.enc
The most probable key lengths:
2: 12.3%
4: 13.8%
6: 10.5%
8: 11.5%
10: 8.6%
12: 9.4%
14: 7.1%
16: 7.8%
23: 10.4%
46: 8.7%
Key-length can be 4*n
Most possible char is needed to guess the key!我们现在可以在过滤输出时测试密钥长度,使得只保留持有 Base64 字符集的明文。尝试了几段长度后,我们找到了正确的明文,只有一个明文,有效字符比例高于默认阈值95%。
$ xortool message.enc -b -f -l 23 -t base64
256 possible key(s) of length 23:
x01=x121#"0x17x13tx7f ,&/x12sx114ux170#
x00<x130"#1x16x12x08~!-'.x13rx105tx161"
x03?x103! 2x15x11x0b}".$-x10qx136wx152!
x02>x112 !3x14x10n|#/%,x11px127vx143
x059x165'&4x13x17r{$("+x16wx150qx134'
...
Found 1 plaintexts with 95.0%+ valid characters
See files filename-key.csv, filename-char_used-perc_valid.csv通过在 Base64 字符集上过滤输出,我们直接保留了唯一的解。
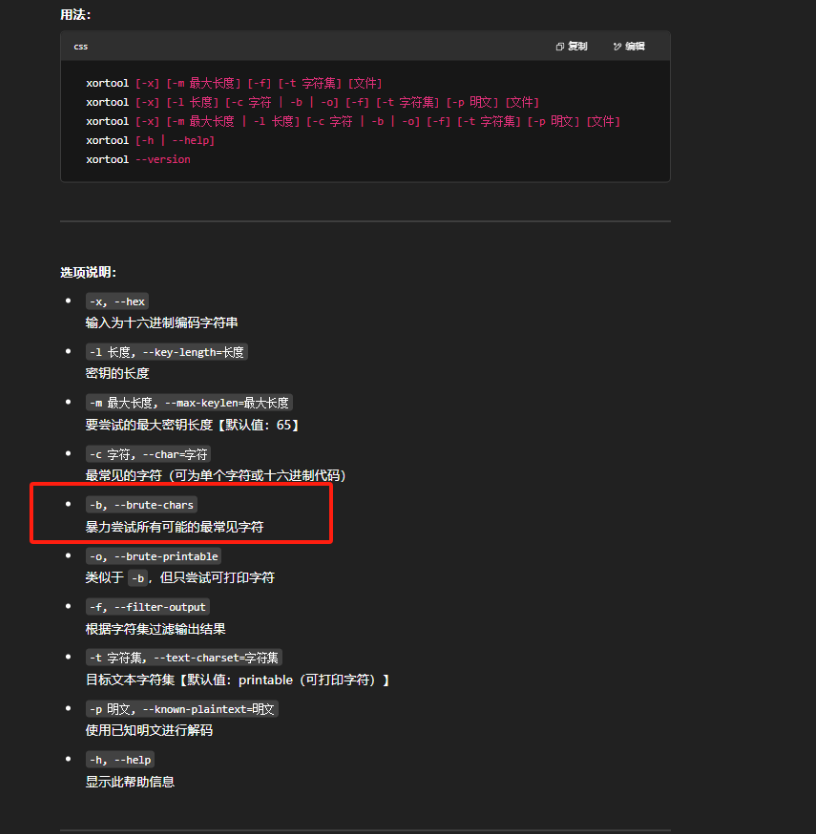

13长度的密钥 22.2% 所以直接暴力破解

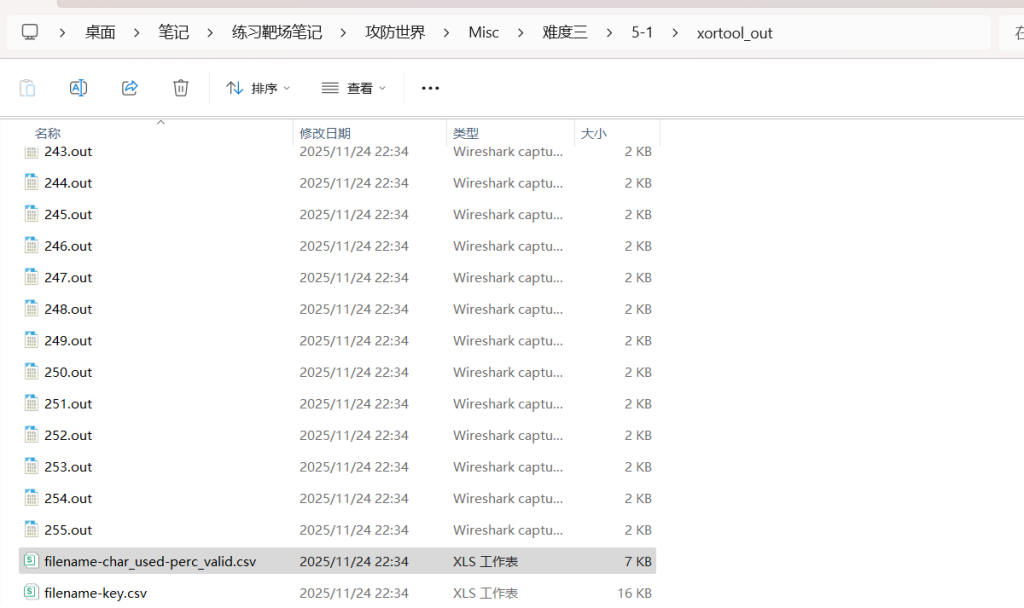
查看CSV文件

发现一个有效密钥
GoodLuckToYou对文件和密钥做xor
py3代码
# 定义加密密钥
Key = "GoodLuckToYou"
# 以二进制读取模式打开输入文件
with open("badd3e0621ff43de8cf802545bbd3ed0", "rb") as f:
# 以写入模式打开输出文件,忽略编码错误
with open("result.txt", "w", errors="ignore") as fp:
index = 0 # 初始化密钥索引
# 读取第一个字节
data = f.read(1)
# 循环读取文件直到结束
while data:
# 调试信息:打印当前处理字节的位置
print(f"Processing byte at position: {index}")
# 将字节数据转换为整数,与密钥对应字符进行异或操作
# 然后将结果转换为字符写入文件
decrypted_char = chr(data[0] ^ ord(Key[index]))
fp.write(decrypted_char)
# 读取下一个字节
data = f.read(1)
# 更新密钥索引,循环使用密钥(密钥长度为13)
index = (index + 1) % len(Key)
print("File decryption completed!")密钥Key = “GoodLuckToYou”,长度为13。
我们以二进制模式打开一个文件”badd3e0621ff43de8cf802545bbd3ed0″,然后逐字节读取。
同时,我们以写入模式打开(或创建)一个文本文件”result.txt”,忽略编码错误。
我们使用一个索引index,从0开始,每处理一个字节就增加1,然后对13取模,以便循环使用密钥中的字符。
对于每个读取的字节,我们将其与密钥中对应位置的字符进行异或操作,然后将结果(一个整数)转换为字符写入到输出文件中。
解密过程:
- 逐字节读取加密文件
- 对每个字节执行异或(XOR)操作:
- 将字节转换为整数
- 与密钥中对应位置的字符ASCII码进行异或
- 将异或结果转换回字符写入输出文件
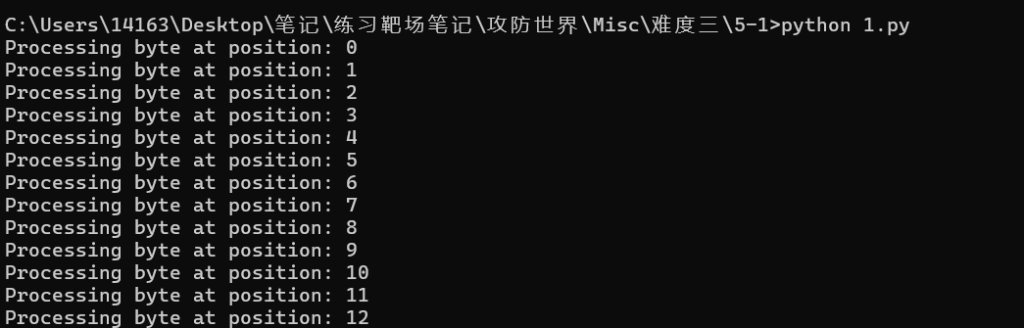

wdflag{You Are Very Smart}10.latlong
foremost提取发现是一个音频,wav

其实不用foremost直接010


或者file命令
传输已接收 根据题目描述 与传输相关,声音很短也没有拨号声音特有案件声音,很有可能是无线电,简单看了wp
AX.25协议
AX.25协议是国际业余无线电联盟(ARRL)基于X.25协议制定的数据链路层通信协议,补充了HDLC和OSI模型对无线信道分组网的规定。该协议在OS!模型框架下扩展了地址域定义,新增无标号信息帧类型,形成包含信息帧、监视帧与无编号帧等10种帧结构,支持无线信道下的全双工和半双工通信,允许设备间建立多个平等链路连接
20世纪80年代初,美国开始构建分组无线网(PRN),至1985年已覆盖全国主要地区,应用于电子邮件、银行业务等领域。该网络采用遵循AX.25协议的通信控制器,协议定义了16种链路状态机制,通过四个控制变量(V(S)、N(S)、V(R)、N(R)实现链路状态转移。虽然最初由业余无线电联盟制定,但由于美军及商业厂商广泛采用,该协议已发展成为通用国际标准后期研发的AX.25高速终端节点控制器(TNC)采用GMSK调制技术,数据传输速率达到9.6kbits AX.25(Amateur X.25)是数据链路层协议套件,旨在供业余无线电运营商使用 AX.25协议在物理层使用BFS
K调制EliasOenal/multimon-ng 这个工具可以解
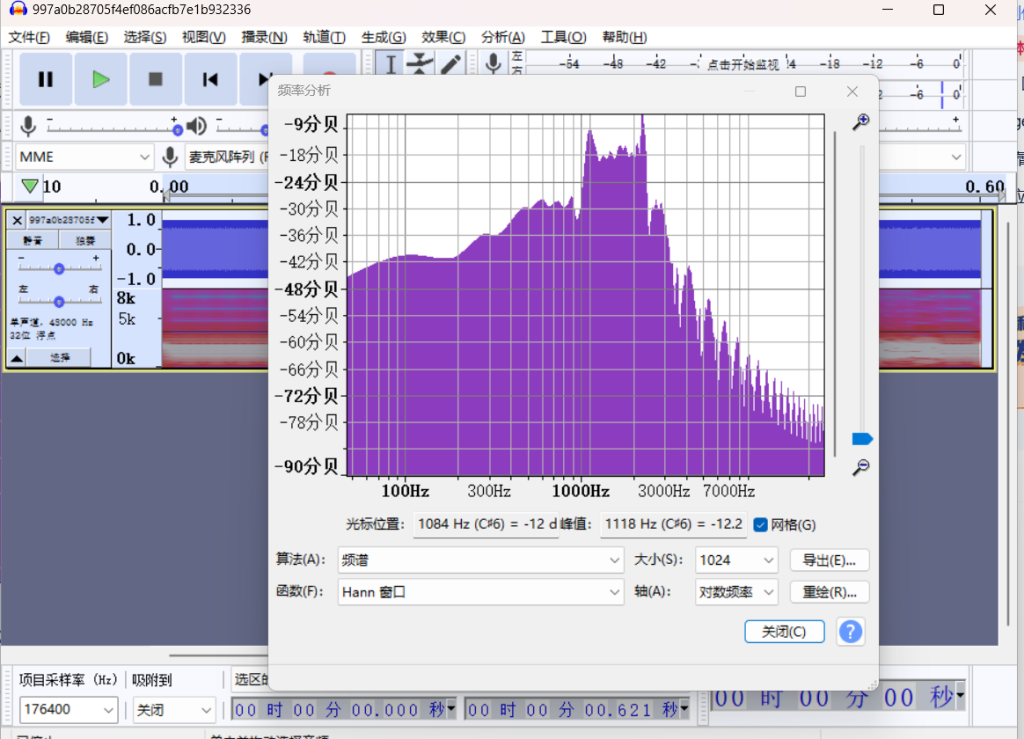
在1100 Hz和2200 Hz处有两个峰值,这是AX.25的BFSK中使用的两个音调
kali直接安装就行
multimon-ng
apt install multimon-ng然后先进行转码 sox 转成RAW调整采样率和采样位数 因为multimon-ng对原始音频数据(RAW)有特定的格式要求
下载
sudo apt install sox --fix-missing- WAV文件:包含文件头(采样率、位深度、声道数等元数据)+ 音频数据
- RAW文件:只包含纯音频数据,没有文件头
multimon-ng的要求
multimon-ng设计用于处理纯音频采样数据,它需要:
- 特定的采样率(通常是22050Hz)
- 特定的位深度(16位有符号整数)
- 单声道音频
- 没有文件头的纯数据
┌──(root㉿kali)-[~/桌面]
└─# sox -t wav 123.wav -esigned-integer -b16 -r 22050 -t raw 123.raw
┌──(root㉿kali)-[~/桌面]
└─# multimon-ng -t raw -a AFSK1200 123.raw
multimon-ng 1.3.1
(C) 1996/1997 by Tom Sailer HB9JNX/AE4WA
(C) 2012-2024 by Elias Oenal
Available demodulators: POCSAG512 POCSAG1200 POCSAG2400 FLEX FLEX_NEXT EAS UFSK1200 CLIPFSK FMSFSK AFSK1200 AFSK2400 AFSK2400_2 AFSK2400_3 HAPN4800 FSK9600 DTMF ZVEI1 ZVEI2 ZVEI3 DZVEI PZVEI EEA EIA CCIR MORSE_CW DUMPCSV X10 SCOPE
Enabled demodulators: AFSK1200
AFSK1200: fm WDPX01-0 to APRS-0 UI pid=F0
!/;E'q/Sz'O /A=000000flag{f4ils4f3c0mms}
┌──(root㉿kali)-[~/桌面]
└─# sox -t wav 123.wav -esigned-integer -b16 -r 22050 -t raw 123.raw参数解释:
sox:音频处理工具-t wav:输入文件类型为WAV格式123.wav:输入文件名-esigned-integer:编码格式为有符号整数-b16:位深度为16位(每个采样点用16位表示)-r 22050:采样率为22050Hz(每秒采样22050次)-t raw:输出文件类型为RAW(纯数据,无文件头)123.raw:输出文件名
multimon-ng -t raw -a AFSK1200 123.raw参数解释:
multimon-ng:多模式数字信号解码器-t raw:输入文件类型为RAW格式-a AFSK1200:添加AFSK1200解码器(Audio Frequency Shift Keying,1200波特率)123.raw:输入文件名
解出flag

flag{f4ils4f3c0mms}11.challenge_how_many_Vigenère
恢复出文档中的明文内容,对明文进行谷歌搜索,得到一个作品名。 把作品名改为纯小写,删除字母以外的字符。 将作品名用你得到的keys用题目中的加密方式加密==>your flag,格式为LCTF{xxxxxxx}
词频分析看看
什么也不是
题目名称是Vigenère,维吉尼亚 推荐文章Vigenere维吉尼亚密码加解密_维吉尼亚密码解密公式-CSDN博客
有一个网站可以解出密钥 Vigenere Solver | guballa.de
密钥长度可以长一点
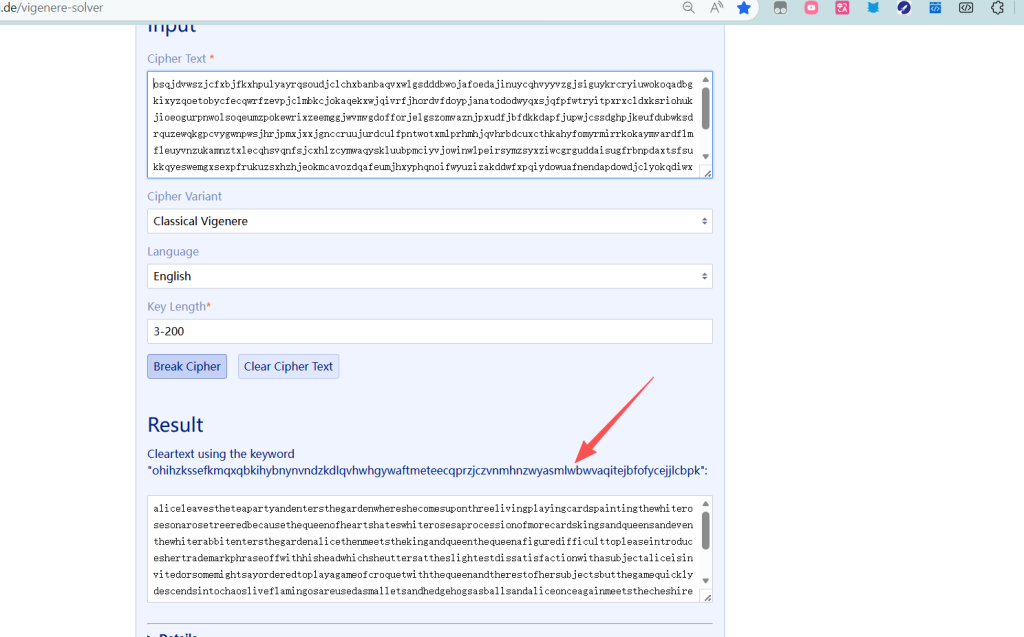
解出密钥
ohihzkssefkmqxqbkihybnynvndzkdlqvhwhgywaftmeteecqprzjczvnmhnzwyasmlwbwvaqitejbfofycejjlcbpk对应的明文
aliceleavestheteapartyandentersthegardenwhereshecomesuponthreelivingplayingcardspaintingthewhiterosesonarosetreeredbecausethequeenofheartshateswhiterosesaprocessionofmorecardskingsandqueensandeventhewhiterabbitentersthegardenalicethenmeetsthekingandqueenthequeenafiguredifficulttopleaseintroduceshertrademarkphraseoffwithhisheadwhichsheuttersattheslightestdissatisfactionwithasubjectaliceisinvitedorsomemightsayorderedtoplayagameofcroquetwiththequeenandtherestofhersubjectsbutthegamequicklydescendsintochaosliveflamingosareusedasmalletsandhedgehogsasballsandaliceonceagainmeetsthecheshirecatthequeenofheartsthenordersthecattobebeheadedonlytohaveherexecutionercomplainthatthisisimpossiblesincetheheadisallthatcanbeseenofhimbecausethecatbelongstotheduchessthequeenispromptedtoreleasetheduchessfromprisontoresolvethematter
使用AI可以得到
这个书叫《爱丽丝梦游仙境》
作品名字Alice’s Adventures in Wonderland
但是根据题目把作品名改为纯小写,删除字母以外的字符
alicesadventuresinwonderland然后把这个书名用我们的密钥进行加密进行加密
osqjdcsvzjxfkoutsvdmoqcegnqc
LCTF{osqjdcsvzjxfkoutsvdmoqcegnqc}12.Miscellaneous-300
是个压缩包,用010打开是真加密
14 00 01 00
根据题目描述

可能文件名字就是密码
发现文件名字就是密码
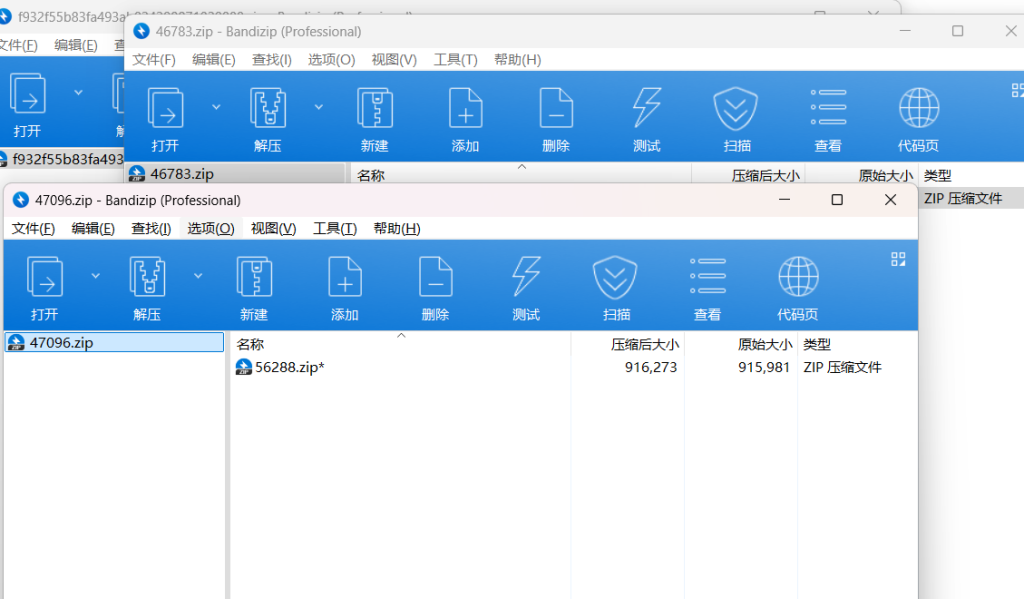
但是非常多的压缩包
所以需要写一个脚本
py3:
import zipfile
import os
import shutil
from pathlib import Path
def extract_nested_zips_with_fallback(start_zip_path, output_dir="extracted_results"):
"""
解压套娃压缩包,当无法解压时保存当前压缩包
:param start_zip_path: 起始压缩包路径
:param output_dir: 输出目录
:return: 无法解压的压缩包路径列表
"""
os.makedirs(output_dir, exist_ok=True)
current_zip = start_zip_path
level = 1
unsolved_zips = []
print(f"开始解压套娃压缩包...")
print(f"起始文件: {os.path.basename(start_zip_path)}")
print(f"输出目录: {output_dir}")
while True:
try:
# 获取当前压缩包的文件名(不含扩展名)
current_zip_name = os.path.splitext(os.path.basename(current_zip))[0]
# 创建当前层的解压目录
level_dir = os.path.join(output_dir, f"level_{level:03d}")
os.makedirs(level_dir, exist_ok=True)
print(f"n{'='*60}")
print(f"第 {level} 层处理:")
print(f"压缩包: {os.path.basename(current_zip)}")
print(f"解压目录: {level_dir}")
# 尝试读取压缩包内容
with zipfile.ZipFile(current_zip, 'r') as zip_ref:
# 获取压缩包内的文件列表
file_list = zip_ref.namelist()
print(f"内部文件: {file_list}")
# 寻找zip文件作为下一层的密码
zip_files = [f for f in file_list if f.lower().endswith('.zip')]
if not zip_files:
print("❌ 内部没有找到压缩包文件,套娃结束")
# 保存当前无法继续解压的压缩包
unsolved_path = save_unsolved_zip(current_zip, output_dir, level)
unsolved_zips.append(unsolved_path)
break
# 使用第一个zip文件名作为密码
next_zip_name = os.path.splitext(zip_files[0])[0]
password = next_zip_name.encode('utf-8')
print(f"尝试密码: {next_zip_name}")
try:
# 尝试用密码解压
zip_ref.extractall(level_dir, pwd=password)
print("✅ 解压成功!")
# 验证解压结果
extracted_files = os.listdir(level_dir)
print(f"解压出的文件: {extracted_files}")
# 寻找下一层的压缩包
next_zip_candidates = []
for root, dirs, files in os.walk(level_dir):
for file in files:
if file.lower().endswith('.zip'):
next_zip_candidates.append(os.path.join(root, file))
if not next_zip_candidates:
print("❌ 解压后未找到新的压缩包")
unsolved_path = save_unsolved_zip(current_zip, output_dir, level)
unsolved_zips.append(unsolved_path)
break
# 使用找到的第一个压缩包作为下一层
current_zip = next_zip_candidates[0]
level += 1
except (RuntimeError, zipfile.BadZipFile) as e:
print(f"❌ 解压失败: {e}")
print("⚠️ 密码可能不正确")
# 保存无法解压的压缩包
unsolved_path = save_unsolved_zip(current_zip, output_dir, level)
unsolved_zips.append(unsolved_path)
break
except FileNotFoundError:
print(f"❌ 文件不存在: {current_zip}")
break
except Exception as e:
print(f"❌ 发生错误: {e}")
# 保存当前有问题的压缩包
unsolved_path = save_unsolved_zip(current_zip, output_dir, level)
unsolved_zips.append(unsolved_path)
break
print(f"n{'='*60}")
print("解压过程结束!")
print(f"总共处理层数: {level}")
print(f"无法解压的压缩包数量: {len(unsolved_zips)}")
if unsolved_zips:
print("n无法解压的压缩包列表:")
for i, zip_path in enumerate(unsolved_zips, 1):
print(f"{i}. {os.path.basename(zip_path)}")
return unsolved_zips
def save_unsolved_zip(zip_path, output_dir, level):
"""
保存无法解压的压缩包到指定目录
"""
unsolved_dir = os.path.join(output_dir, "unsolved_zips")
os.makedirs(unsolved_dir, exist_ok=True)
# 创建新的文件名,包含层级信息
original_name = os.path.basename(zip_path)
new_name = f"level_{level:03d}_{original_name}"
new_path = os.path.join(unsolved_dir, new_name)
# 复制文件
shutil.copy2(zip_path, new_path)
print(f"💾 已保存无法解压的压缩包: {new_name}")
return new_path
def smart_extract_with_multiple_passwords(zip_path, output_dir="smart_extracted"):
"""
智能解压,尝试多种密码可能性
"""
os.makedirs(output_dir, exist_ok=True)
print(f"智能解压: {os.path.basename(zip_path)}")
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
file_list = zip_ref.namelist()
print(f"内部文件: {file_list}")
zip_files = [f for f in file_list if f.lower().endswith('.zip')]
if not zip_files:
print("内部没有压缩包文件")
return []
passwords_to_try = []
for zip_file in zip_files:
base_name = os.path.splitext(zip_file)[0]
passwords_to_try.extend([
base_name, # 原始名称
base_name.lower(), # 小写
base_name.upper(), # 大写
base_name.replace(' ', ''), # 去除空格
base_name.replace('_', ''), # 去除下划线
base_name.replace('-', ''), # 去除横线
])
# 去重
passwords_to_try = list(set(passwords_to_try))
print(f"尝试的密码列表: {passwords_to_try}")
for password in passwords_to_try:
try:
zip_ref.extractall(output_dir, pwd=password.encode('utf-8'))
print(f"✅ 解压成功! 密码: {password}")
return [password] # 返回成功的密码
except:
continue
print("❌ 所有密码尝试失败")
return []
def analyze_zip_structure(zip_path):
"""
分析压缩包结构
"""
print(f"n分析压缩包: {os.path.basename(zip_path)}")
try:
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
# 检查是否加密
for info in zip_ref.infolist():
is_encrypted = info.flag_bits & 0x1
print(f"文件: {info.filename}, 加密: {is_encrypted}")
# 显示文件列表
print(f"总文件数: {len(zip_ref.namelist())}")
for file in zip_ref.namelist():
print(f" - {file}")
except Exception as e:
print(f"分析失败: {e}")
if __name__ == "__main__":
target_zip = "f932f55b83fa493ab024390071020088.zip"
if os.path.exists(target_zip):
print("找到目标文件,开始解压...")
# 方法1: 标准解压(推荐)
unsolved = extract_nested_zips_with_fallback(target_zip, "extraction_results")
# 显示最终结果
if unsolved:
print(f"n💡 提示: 有 {len(unsolved)} 个压缩包无法解压")
print("这些压缩包已保存在 'extraction_results/unsolved_zips/' 目录中")
# 分析第一个无法解压的压缩包
if unsolved:
print(f"n分析第一个无法解压的压缩包:")
analyze_zip_structure(unsolved[0])
else:
print("n🎉 所有压缩包都成功解压!")
else:
print(f"文件 {target_zip} 不存在")
print("请将脚本放在包含目标压缩包的目录中运行")
# 显示当前目录的zip文件
current_zips = [f for f in os.listdir('.') if f.lower().endswith('.zip')]
if current_zips:
print(f"n当前目录找到的zip文件: {current_zips}")
print("您想解压哪个文件?")
for i, zip_file in enumerate(current_zips, 1):
print(f"{i}. {zip_file}")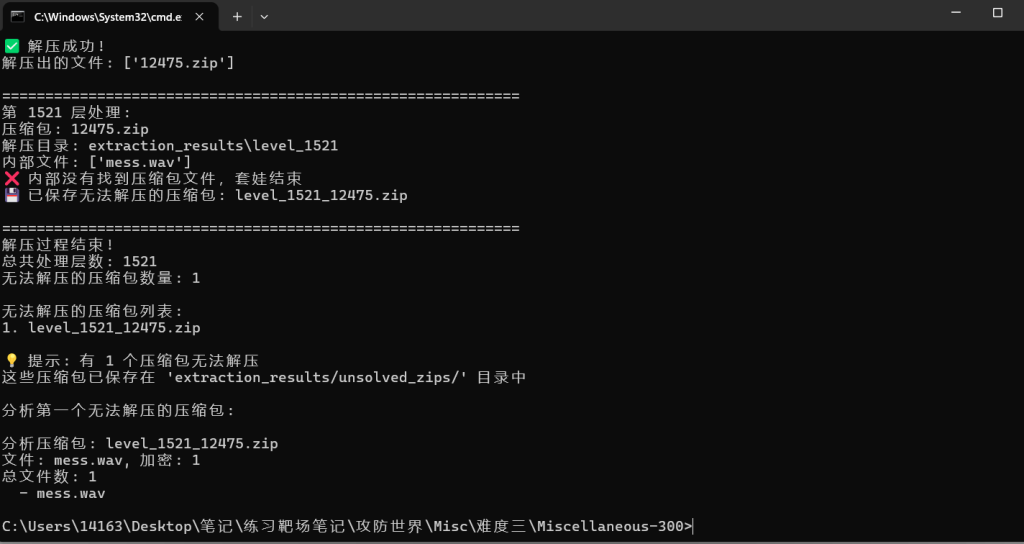
1521层
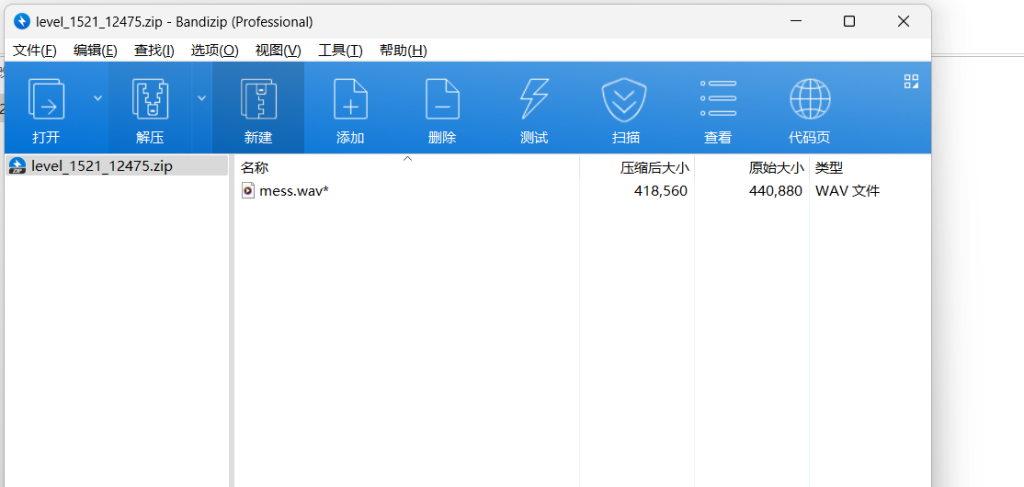
最后一层要爆破
正常CTF爆破不会加太长的密一般都是4-6位数字+大小写字母就行
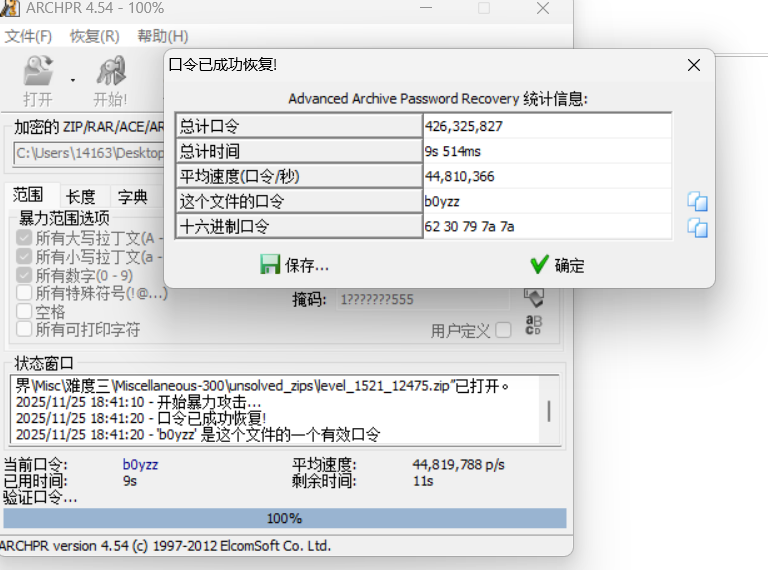
密码:b0yzz
用Audacity分析查看频谱图
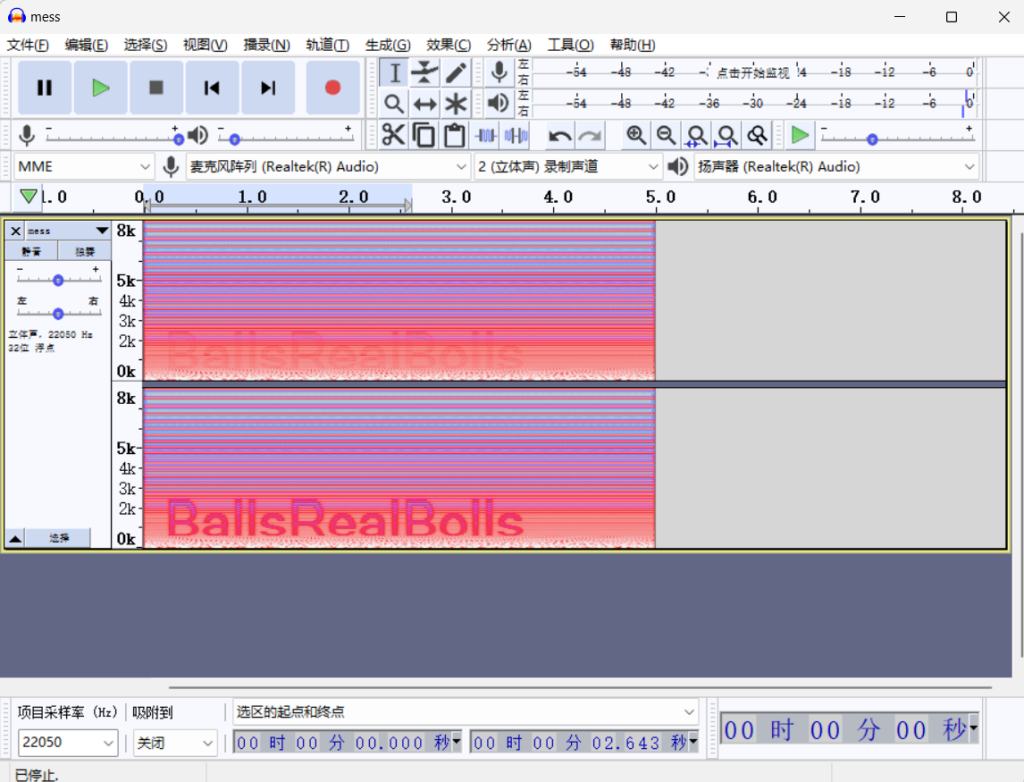
答案就是:BallsRealBolls13.warmup
解压出来是一个图片和压缩包
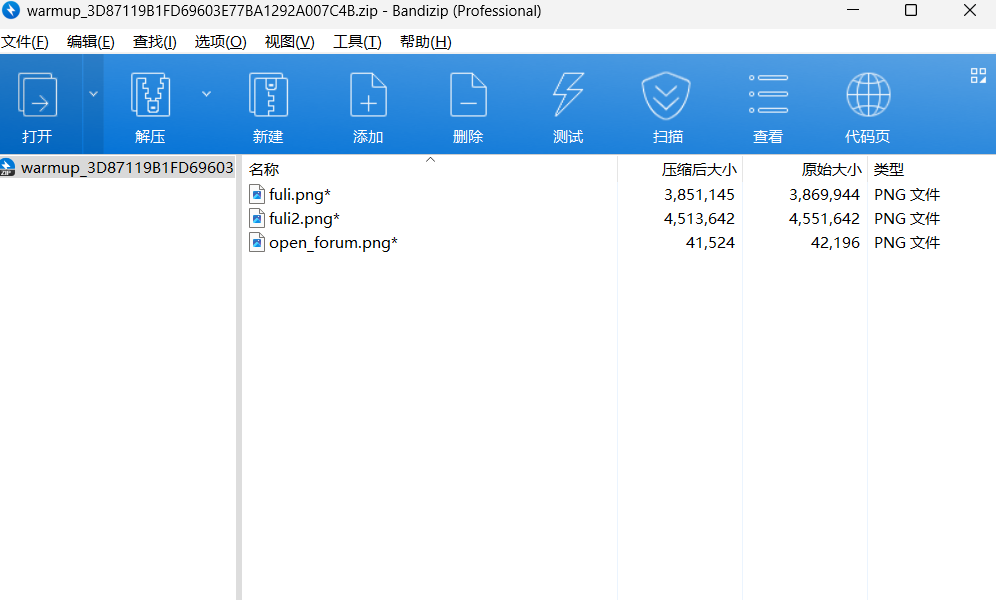
将解压出来的图片,添加.zip压缩包
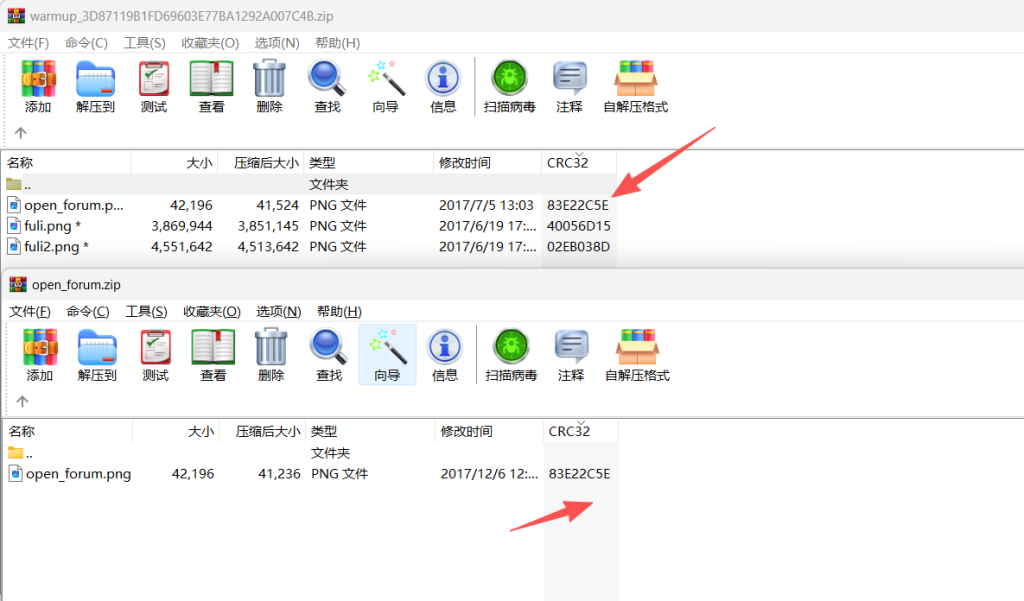
可以发现CRC32是一样可使用明文爆破
使用WinRAR压缩就行
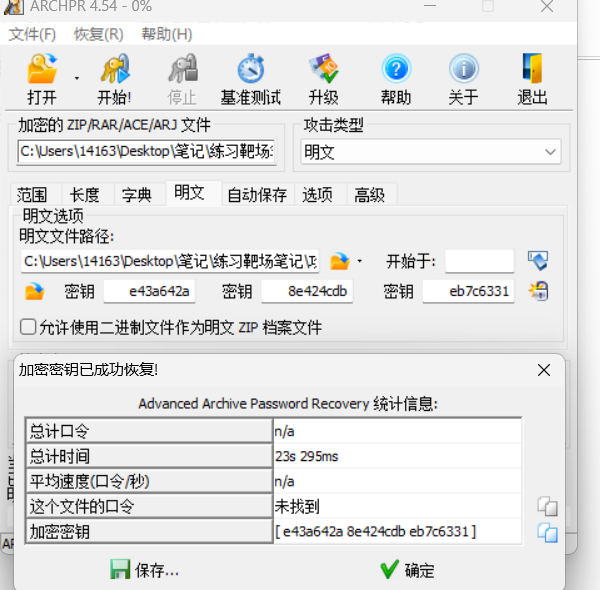
攻击成功

看这个三张图片可以判断是盲水印
>python bwmforpy3.py decode --oldseed fuli.png fuli2.png open_forum.png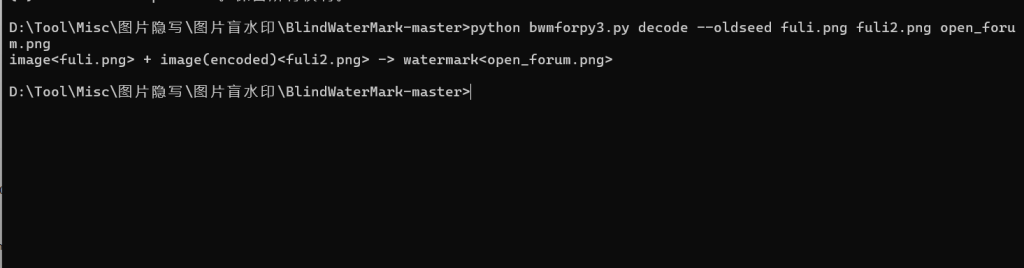

flag{bWm_Are_W0nderfu1}14.传感器1
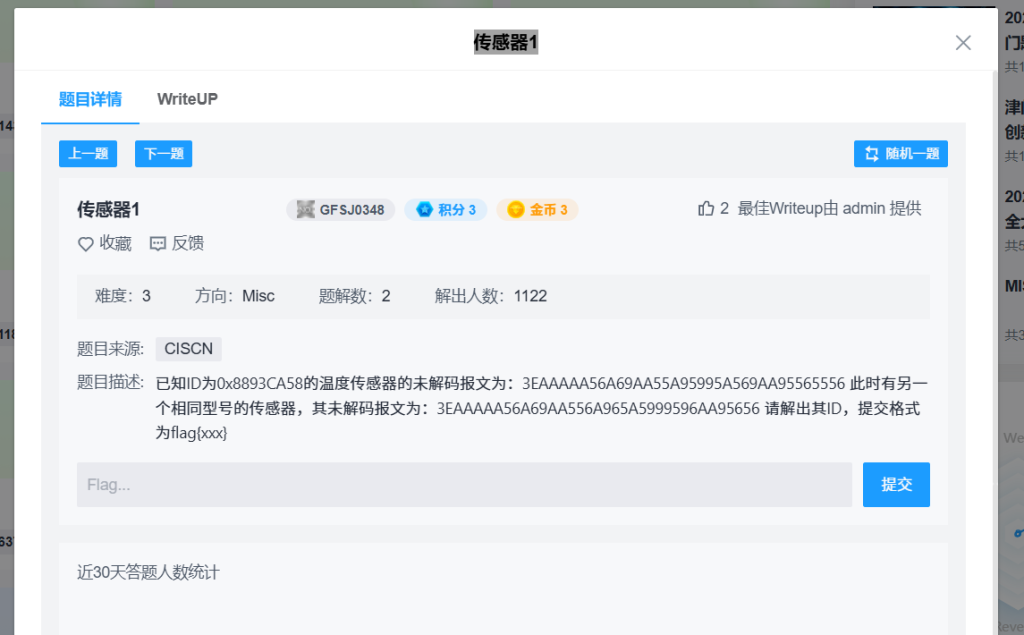
题目描述:
已知ID为0x8893CA58的温度传感器的未解码报文为:3EAAAAA56A69AA55A95995A569AA95565556 此时有另一个相同型号的传感器,其未解码报文为:3EAAAAA56A69AA556A965A5999596AA95656 请解出其ID,提交格式为flag{xxx}先把这个十六进制转成二进制看看
1111101010101010101010101001010110101001101001101010100101010101101010100101100101101001011001100110010101100101101010101010010101011001010110我们发现规律前几位都是1111 后面全都是1010101 这就可以发现这个是曼切斯特编码
曼切斯特编码(Manchester)
曼彻斯特编码也称为相位编码,是一种同步时钟编码技术。通过电平的高低转换来表示“0”或“1”,每一位的中间有一个跳变的动作,这个动作既作时钟信号,又作数据信号,但因为每一个码元都被调成两个电平,所以数据传输速率只有调制速率的1/2,其编码效率为50%。常用于局域网传输!
特征: 01组成
差分曼切斯特编码(Manchester-diff)
差分曼彻斯特编码也是一种双相码,和曼彻斯特码不同的是,这种编码的码元中间的电平转换边只作为定时信号,而不表示数据。数据的表示在与每一位开始处是否有电平转换,有电平转换表示0,无电平转换表示1。差分曼彻斯特码用在令牌环网中
所以把前面1111去掉 就是3E
1010101010101010101001010110101001101001101010100101010101101010100101100101101001011001100110010101100101101010101010010101011001010110AAAAA56A69AA556A965A5999596AA956561010101010101010101001010110101001101001101010100101010110101001010110011001010110100101011010011010101010010101010101100101010101010110AAAAA56A69AA55A95995A569AA95565556因为我们不确定是曼切斯特编码(Manchester)还是差分曼切斯特编码(Manchester-diff)
差分曼彻斯特编码规则:
- 每个比特位开始时,如果电平跳变(与前一比特结束时的电平不同),表示比特”0″
- 每个比特位开始时,如果电平不跳变(与前一比特结束时的电平相同),表示比特”1″
- 通常使用”01″作为初始参考状态
所以都要解
py3
import textwrap
def hex_to_bin(hex_str):
"""将十六进制字符串转换为二进制字符串"""
return bin(int(hex_str, 16))[2:].zfill(len(hex_str) * 4)
def bin_to_hex(bin_str):
"""将二进制字符串转换为十六进制字符串"""
return hex(int(bin_str, 2))[2:].upper()
def differential_manchester_decode(input_bin):
"""差分曼彻斯特码解码"""
if len(input_bin) % 2 != 0:
print("非法差分曼切斯特码,长度不是偶数")
return None
output = ""
# 初始状态设为"01"
last_pair = "01"
for i in range(0, len(input_bin), 2):
current_pair = input_bin[i:i+2]
if current_pair not in ["01", "10"]:
print(f"非法差分曼切斯特码对: {current_pair}")
return None
# 与前面相同为0,不相同为1
if current_pair == last_pair:
output += "0"
else:
output += "1"
last_pair = current_pair
return output
# 已知数据
known_id = "8893CA58"
known_data = "3EAAAAA56A69AA55A95995A569AA95565556"
unknown_data = "3EAAAAA56A69AA556A965A5999596AA95656"
print("已知传感器ID:", known_id)
print("已知传感器原始数据:", known_data)
print("未知传感器原始数据:", unknown_data)
# 移除前导码3E
known_data_no_prefix = known_data[2:]
unknown_data_no_prefix = unknown_data[2:]
print("n移除前导码后的已知数据:", known_data_no_prefix)
print("移除前导码后的未知数据:", unknown_data_no_prefix)
# 转换为二进制
known_bin = hex_to_bin(known_data_no_prefix)
unknown_bin = hex_to_bin(unknown_data_no_prefix)
print("n已知数据二进制长度:", len(known_bin))
print("未知数据二进制长度:", len(unknown_bin))
# 差分曼彻斯特解码
known_decoded = differential_manchester_decode(known_bin)
unknown_decoded = differential_manchester_decode(unknown_bin)
if known_decoded and unknown_decoded:
known_decoded_hex = bin_to_hex(known_decoded)
unknown_decoded_hex = bin_to_hex(unknown_decoded)
print("n已知数据差分曼彻斯特解码:", known_decoded_hex)
print("未知数据差分曼彻斯特解码:", unknown_decoded_hex)
# 查找ID位置
position = known_decoded_hex.find(known_id)
if position != -1:
print(f"n在已知数据中找到ID位置: {position}")
unknown_id = unknown_decoded_hex[position:position+8]
print(f"未知传感器ID: {unknown_id}")
print(f"flag{{{unknown_id}}}")
else:
print("未在已知数据中找到ID")
else:
print("解码失败")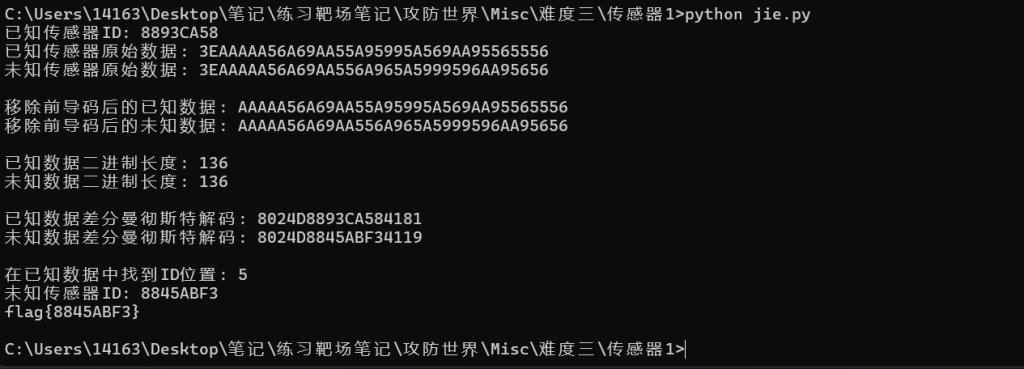
flag{8845ABF3}15.互相伤害!!!
看文件是个.pcapng 是个流量包
里面全是图片,把图片全部提出来
直接foremost
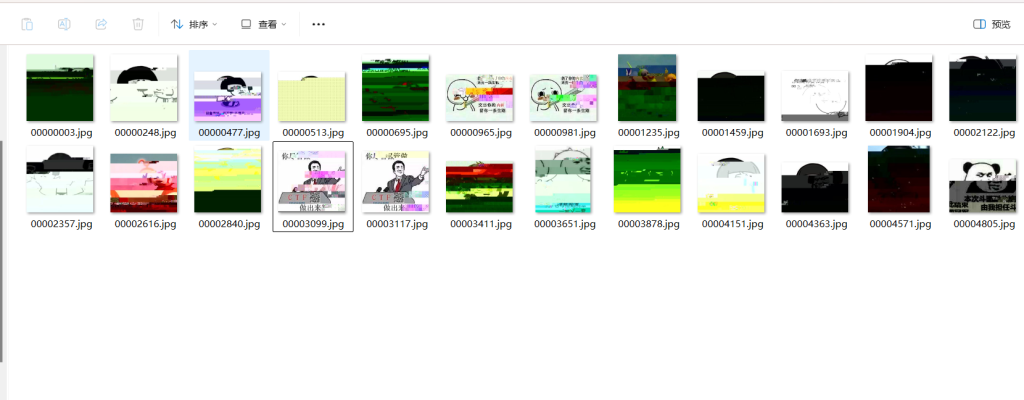

有个二维码看看扫描一下
扫不出来
还是Wireshark导出吧
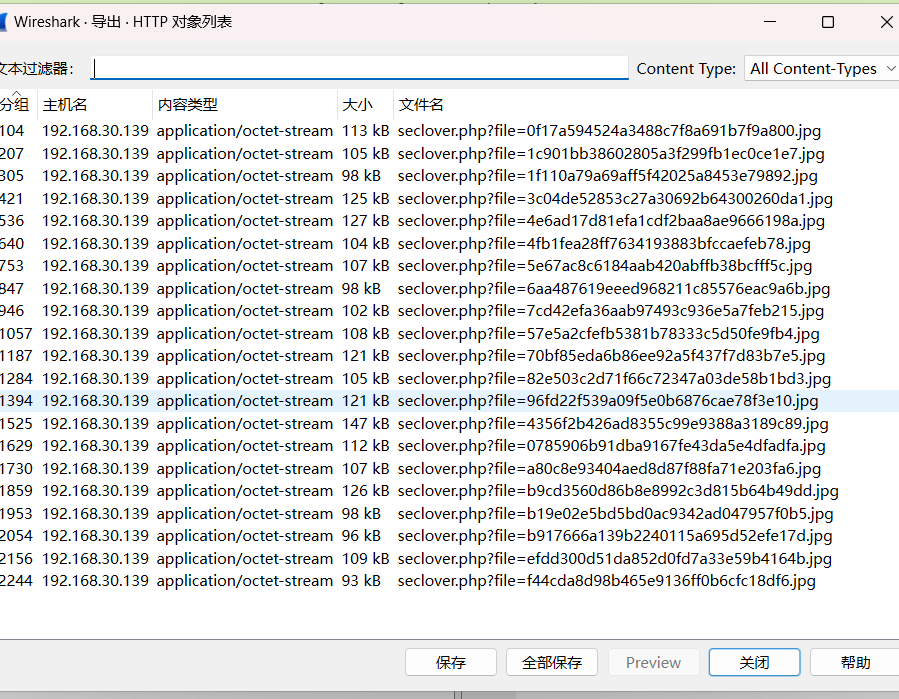

清晰多了
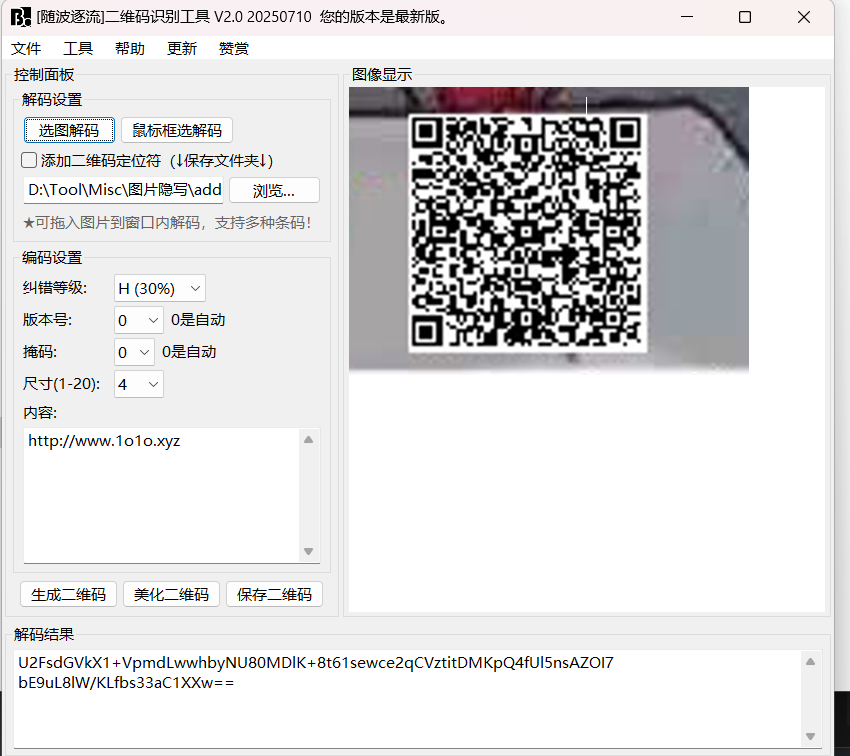
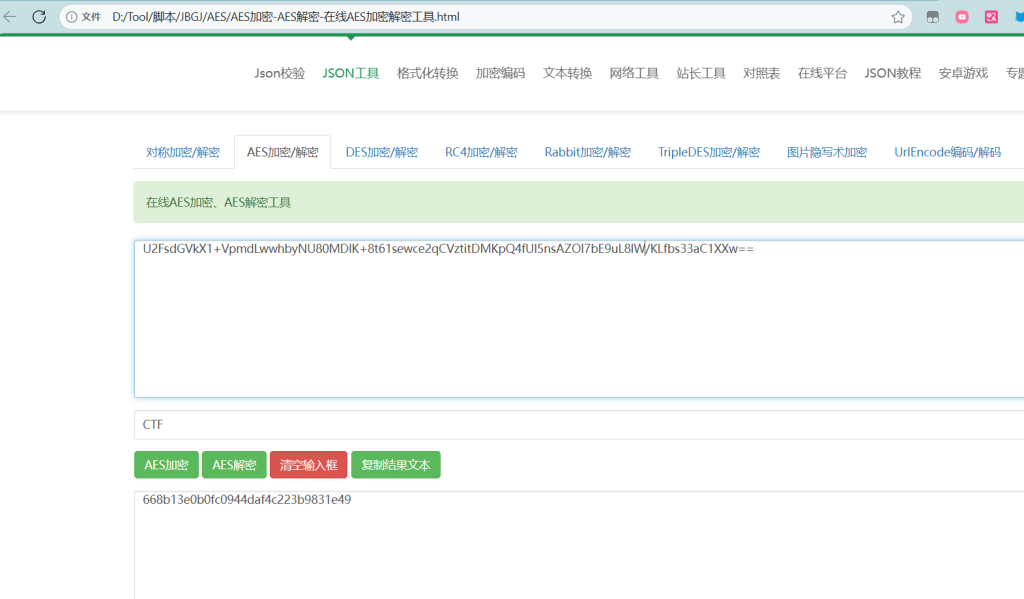
U2FsdGVkX1+VpmdLwwhbyNU80MDlK+8t61sewce2qCVztitDMKpQ4fUl5nsAZOI7
bE9uL8lW/KLfbs33aC1XXw==本发布会由AES独家赞助
说明是AES加密 密码是CTF
668b13e0b0fc0944daf4c223b9831e49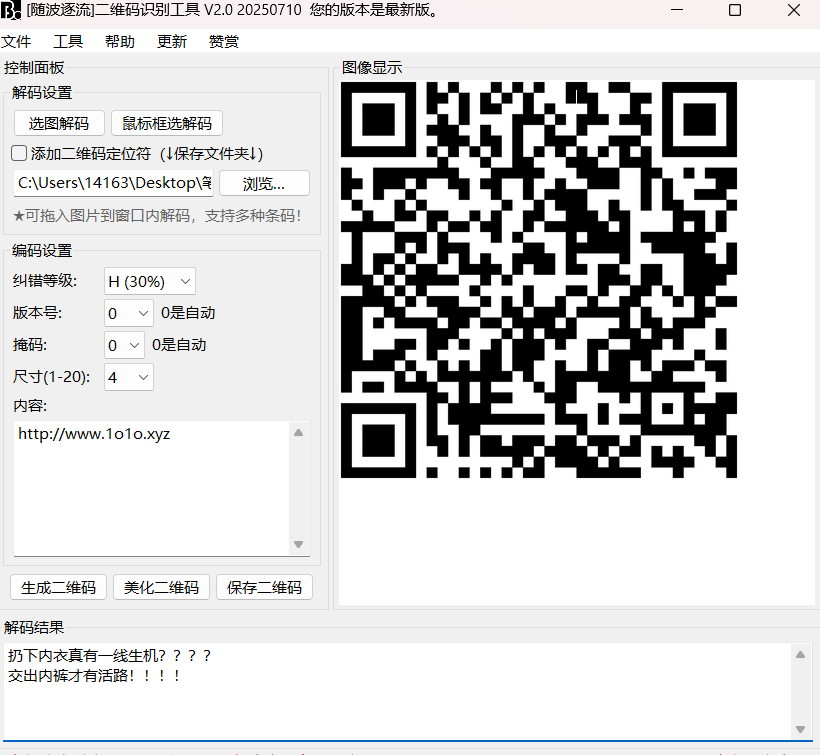
我们发现每一个图片都有一个压缩包,压缩包里面是一个二维码都是一样的,这些图片全部binwalk
然后一个一个看
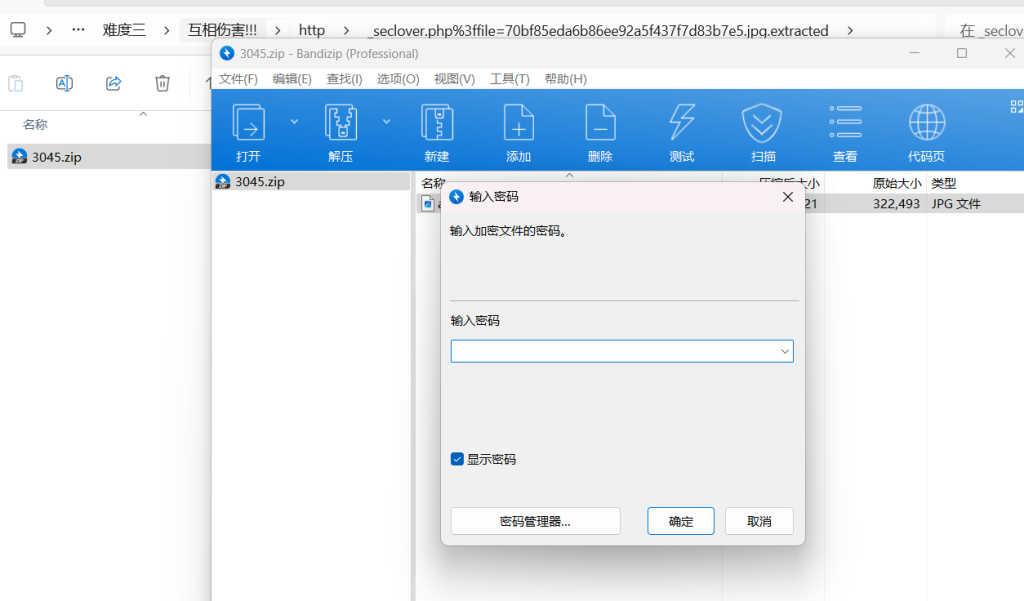
70bf85eda6b86ee92a5f437f7d83b7e5.jpg 这个图片要密码
就是这个图

刚好应对题目名字
密码就是:668b13e0b0fc0944daf4c223b9831e49


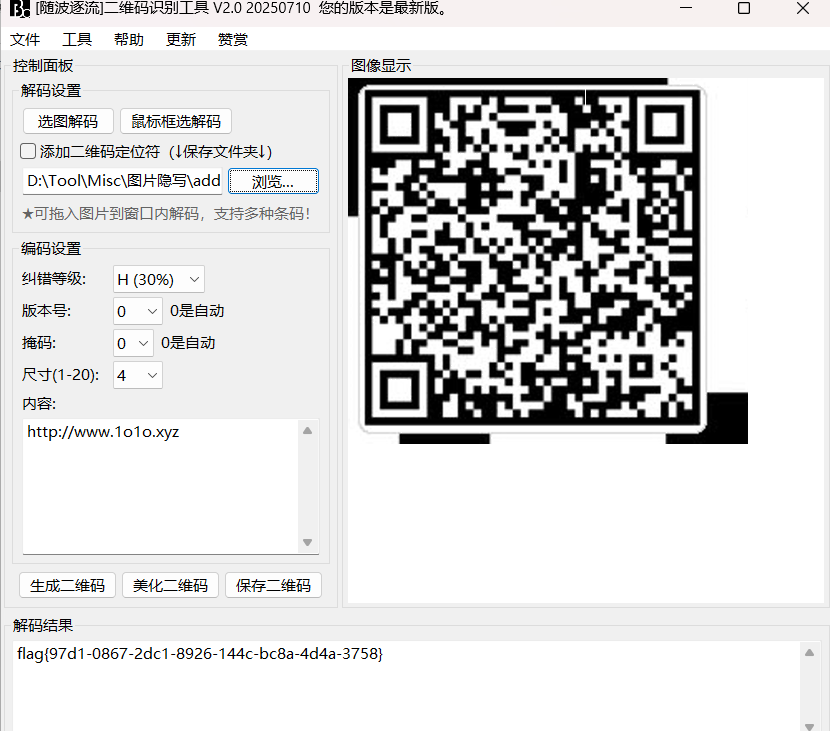
97d1-0867-2dc1-8926-144c-bc8a-4d4a-375816.签到题
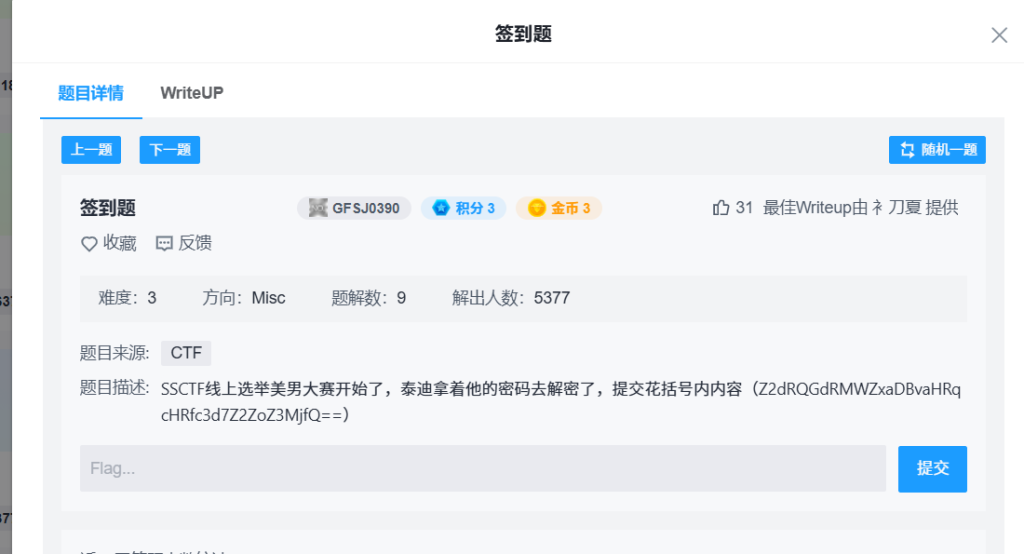
题目描述:
SSCTF线上选举美男大赛开始了,泰迪拿着他的密码去解密了,提交花括号内内容(Z2dRQGdRMWZxaDBvaHRqcHRfc3d7Z2ZoZ3MjfQ==)base64解码

ggQ@gQ1fqh0ohtjpt_sw{gfhgs#}是一个凯撒密码
==================================================
解密结果 (所有位移可能):
==================================================
位移 0: ggQ@gQ1fqh0ohtjpt_sw{gfhgs#}
位移 1: ffP@fP1epg0ngsios_rv{fegfr#}
位移 2: eeO@eO1dof0mfrhnr_qu{edfeq#}
位移 3: ddN@dN1cne0leqgmq_pt{dcedp#}
位移 4: ccM@cM1bmd0kdpflp_os{cbdco#}
位移 5: bbL@bL1alc0jcoeko_nr{bacbn#}
位移 6: aaK@aK1zkb0ibndjn_mq{azbam#}
位移 7: zzJ@zJ1yja0hamcim_lp{zyazl#}
位移 8: yyI@yI1xiz0gzlbhl_ko{yxzyk#}
位移 9: xxH@xH1why0fykagk_jn{xwyxj#}
位移 10: wwG@wG1vgx0exjzfj_im{wvxwi#}
位移 11: vvF@vF1ufw0dwiyei_hl{vuwvh#}
位移 12: uuE@uE1tev0cvhxdh_gk{utvug#}
位移 13: ttD@tD1sdu0bugwcg_fj{tsutf#}
位移 14: ssC@sC1rct0atfvbf_ei{srtse#}
位移 15: rrB@rB1qbs0zseuae_dh{rqsrd#}
位移 16: qqA@qA1par0yrdtzd_cg{qprqc#}
位移 17: ppZ@pZ1ozq0xqcsyc_bf{poqpb#}
位移 18: ooY@oY1nyp0wpbrxb_ae{onpoa#}
位移 19: nnX@nX1mxo0voaqwa_zd{nmonz#}
位移 20: mmW@mW1lwn0unzpvz_yc{mlnmy#}
位移 21: llV@lV1kvm0tmyouy_xb{lkmlx#}
位移 22: kkU@kU1jul0slxntx_wa{kjlkw#}
位移 23: jjT@jT1itk0rkwmsw_vz{jikjv#}
位移 24: iiS@iS1hsj0qjvlrv_uy{ihjiu#}
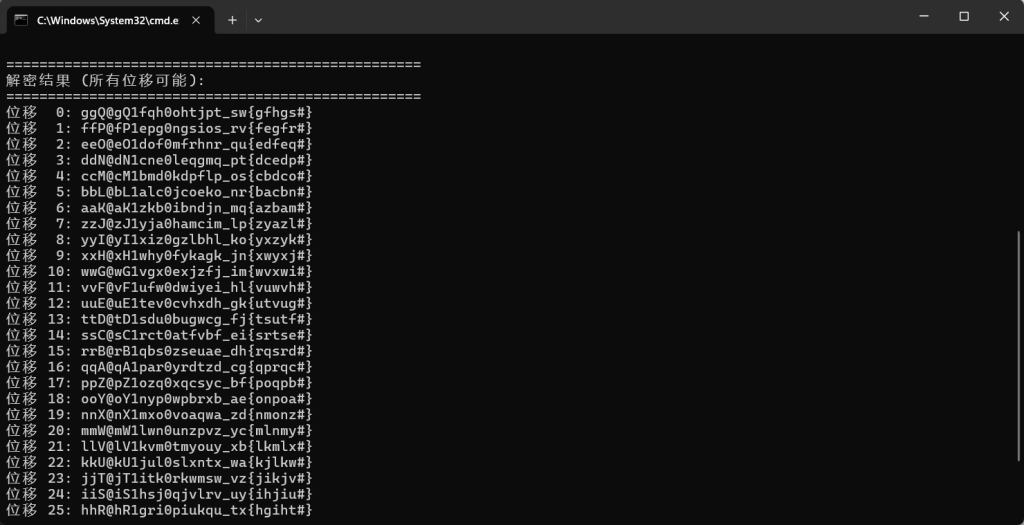
位移 25: hhR@hR1gri0piukqu_tx{hgiht#}我们看这个位移 14: ssC@sC1rct0atfvbf_ei{srtse#} 里面有ctf这几个字符可以进行栅栏密码解密试试
其实也可以暴力
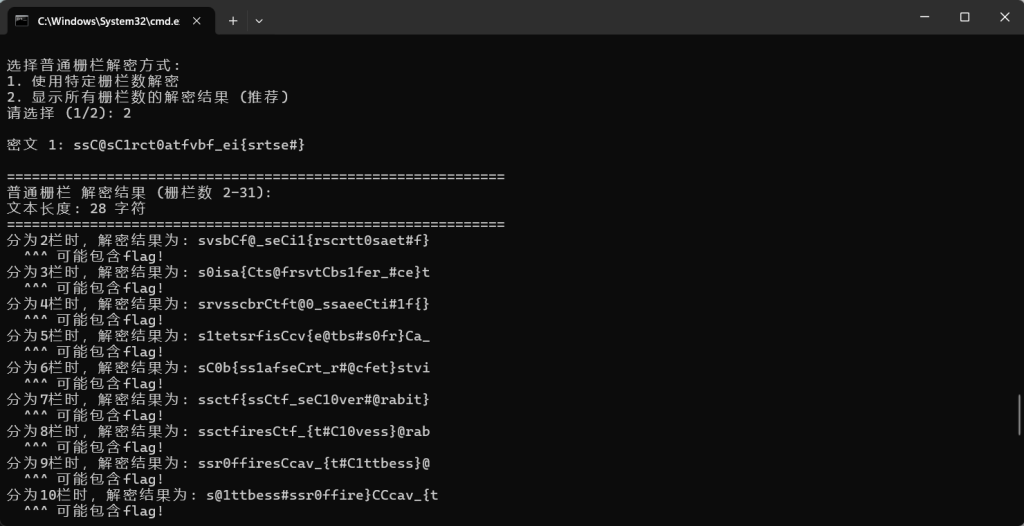
解出flag
ssctf{ssCtf_seC10ver#@rabit}17.pdf
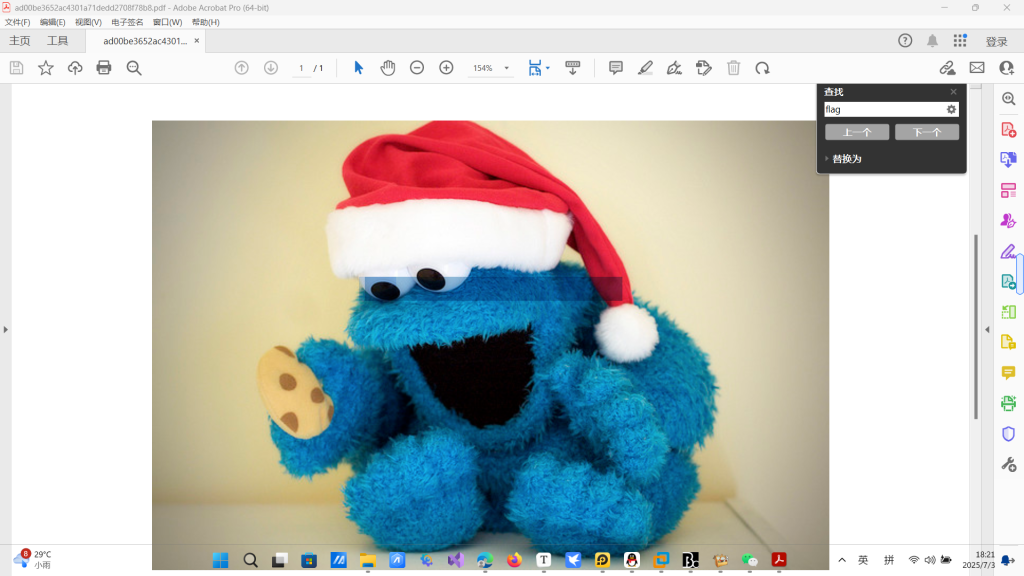
进入pdf搜索 flag就能发现
flag{security_through_obscurity}18.如来十三掌
一眼佛曰
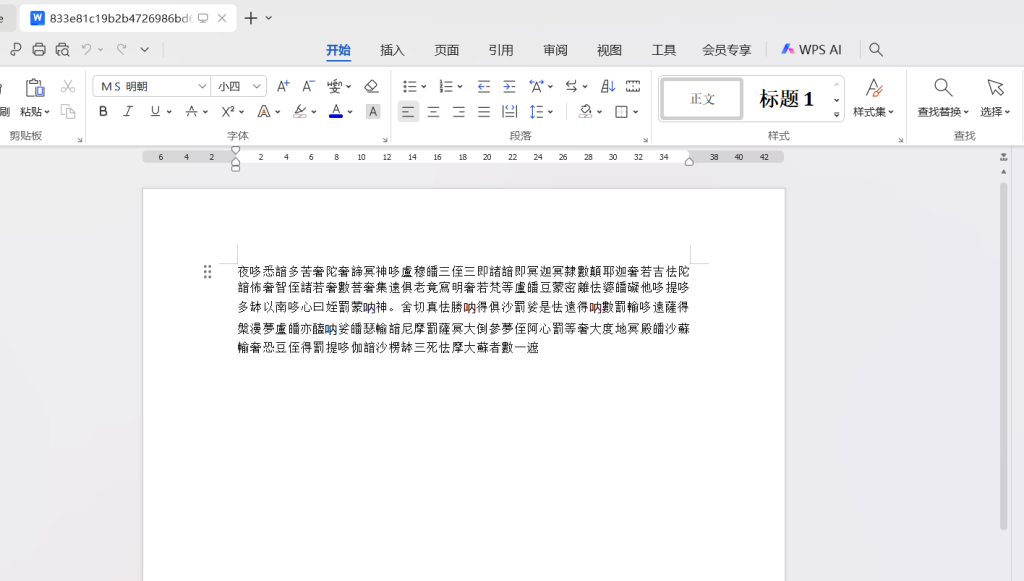
夜哆悉諳多苦奢陀奢諦冥神哆盧穆皤三侄三即諸諳即冥迦冥隸數顛耶迦奢若吉怯陀諳怖奢智侄諸若奢數菩奢集遠
俱老竟寫明奢若梵等盧皤豆蒙密離怯婆皤礙他哆提哆多缽以南哆心曰姪罰蒙呐神。舍切真怯勝呐得俱沙罰娑是怯
遠得呐數罰輸哆遠薩得槃漫夢盧皤亦醯呐娑皤瑟輸諳尼摩罰薩冥大倒參夢侄阿心罰等奢大度地冥殿皤沙蘇輸奢恐
豆侄得罰提哆伽諳沙楞缽三死怯摩大蘇者數一遮----->解码:
MzkuM3gvMUAwnzuvn3cgozMlMTuvqzAenJchMUAeqzWenzEmLJW9--->解码:如来十三掌(rot13解码)
ZmxhZ3tiZHNjamhia3ptbmZyZGhidmNraWpuZHNrdmJramRzYWJ9-->base64解码:
flag{bdscjhbkzmnfrdhbvckijndskvbkjdsab}19.miscmisc
一个图片直接给他binwalk

有两个压缩包

这个图片binwalk发现有个flag.txt但是是个假的

这个假的flag.txt和那个加密的flag.txt可以进行压缩包明文爆破 假的flag.txt直接用WinRAR进行.zip
CRC32一样可以明文爆破
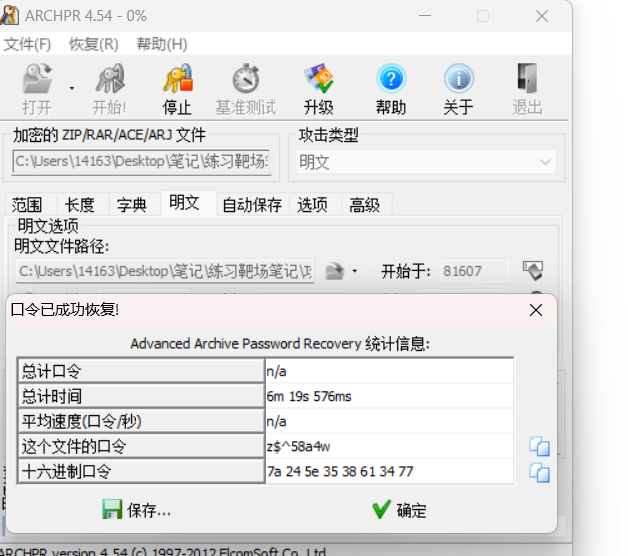
密码:z$^58a4w
压缩包解压是
密码应该在.doc文件里面
直接把隐藏文件直接显示
可以发现
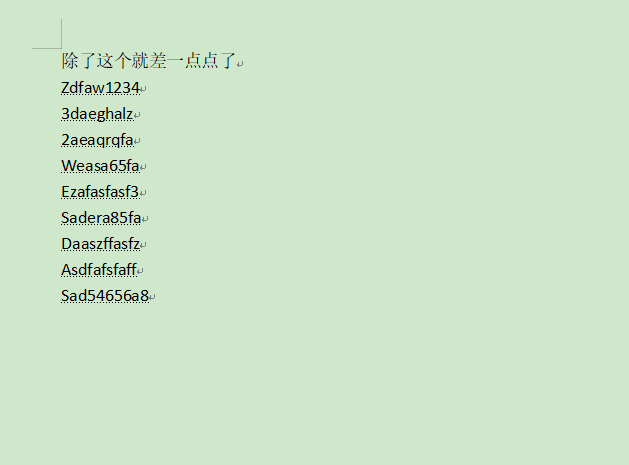
应该是密码
尝试一下
Zdfaw1234
3daeghalz
2aeaqrqfa
Weasa65fa
Ezafasfasf3
Sadera85fa
Daaszffasfz
Asdfafsfaff
Sad54656a8看看那个图片LSB
在BGR通道可以看到
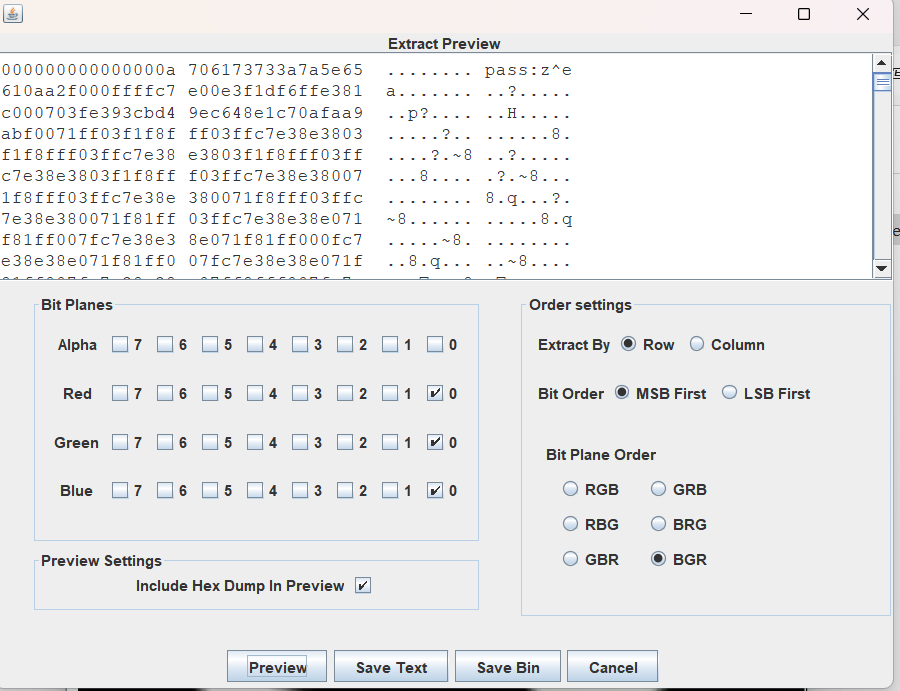
pass:z^ea
然后看了看wp发现密码是
pass内容+world里每行字符串的最后一个字符 666无语了
密码:z^ea4zaa3azf8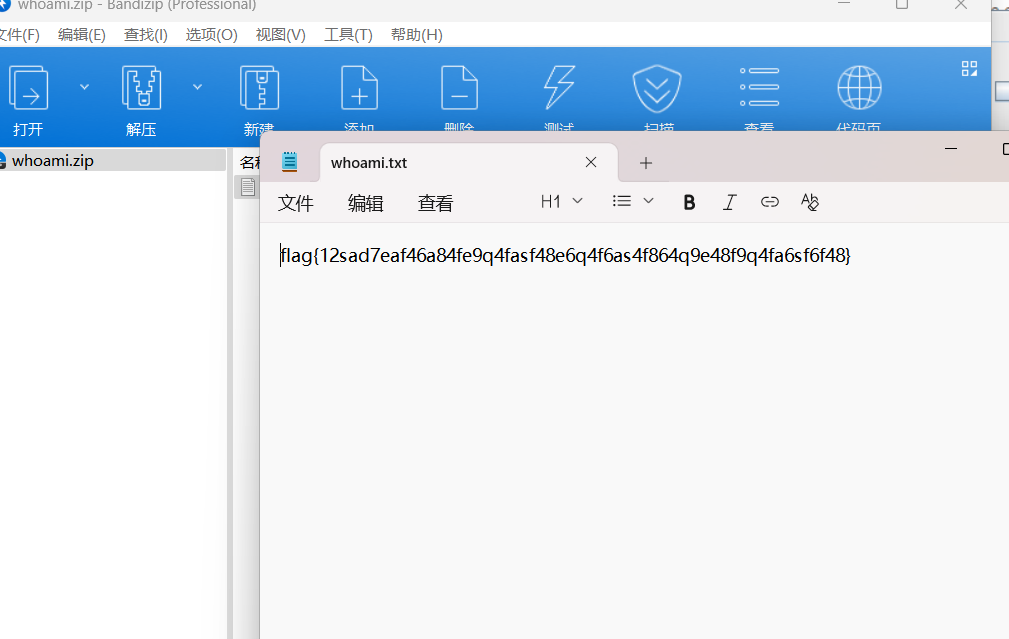
flag{12sad7eaf46a84fe9q4fasf48e6q4f6as4f864q9e48f9q4fa6sf6f48}20.奇怪的TTL字段
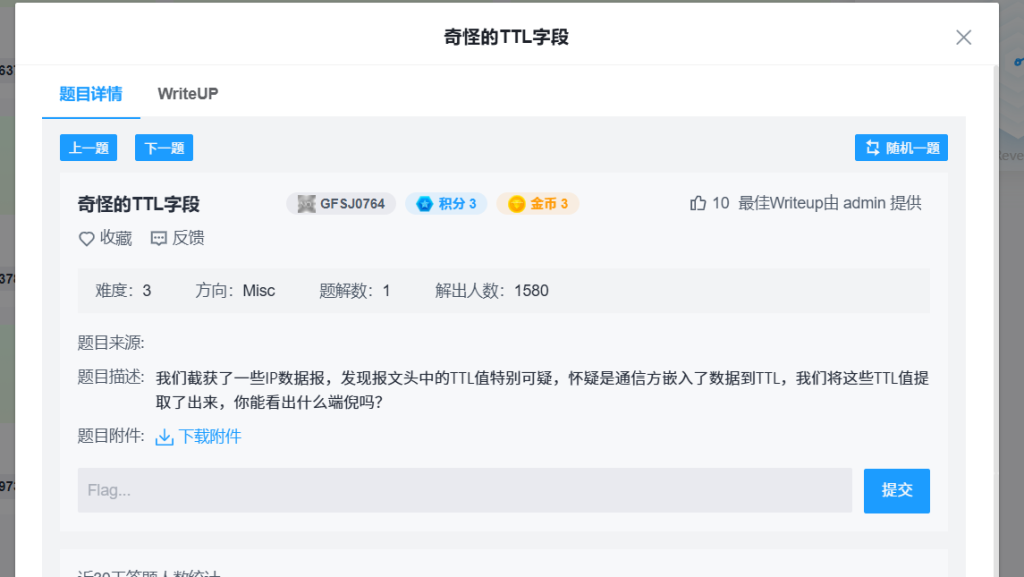
什么是TTL?
TTL是 Time To Live的缩写,中文意思是生存时间。该字段指定IP包被路由器丢弃之前允许通过的最大网段数量。TTL是IPv4报头的一个8 bit字段。
注意:TTL与DNS TTL有区别。二者都是生存时间,前者指ICMP包的转发次数(跳数),后者指域名解析信息在DNS中的存在时间。在IPv4包头中TTL是一个8 bit字段,它位于IPv4包的第9个字节。如下图所示,每
一行表示 32 bit(4字节),位从0开始编号,即0~31。
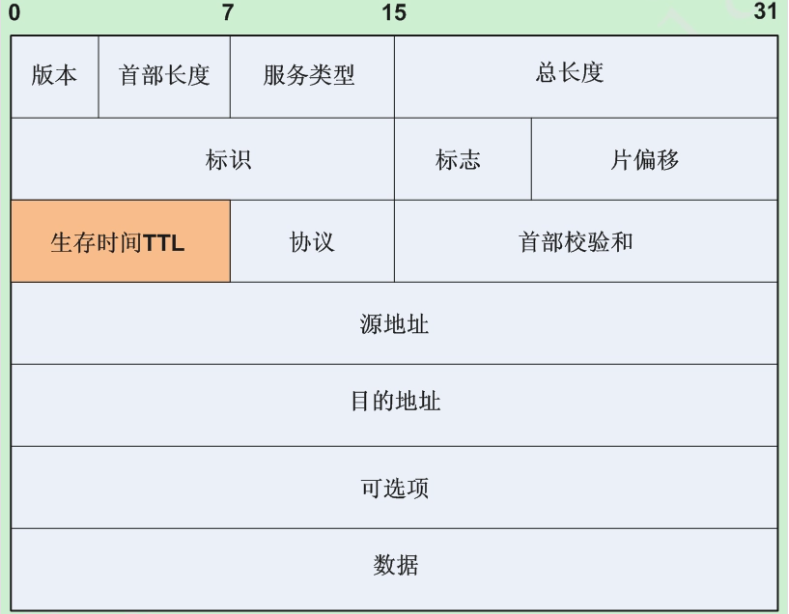
TTL的作用是限制IP数据包在计算机网络中的存在的时间。TTL的最大值是255,TTL的一个推荐值是64。
虽然TTL从字面上翻译,是可以存活的时间,但实际上TTL是IP数据包在计算机网络中可以转发的最大跳数。TTL字段由IP数据包的发送者设置,在IP数据包从源到目的的整个转发路径上,每经过一个路由器,路由器都会修改这个TTL字段值,具体的做法是把该TTL的值减1,然后再将IP包转发出去。如果在IP包到达目的IP之前,TTL减少为0,路由器将会丢弃收到的TTL=0的IP包并向IP包的发送者发送 ICMP time exceeded消息。
TTL的主要作用是避免IP包在网络中的无限循环和收发,节省了网络资源,并能使IP包的发送者能收到告警消息。
TTL 是由发送主机设置的,以防止数据包不断在IP互联网络上永不终止地循环。转发IP数据包时,要求路由器至少将 TTL 减小 1。
TTL值的注册表位置HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesTcpipParameters 其中有个DefaultTTL的DWORD值,其数据就是默认的TTL值了,我们可以修改,但不能大于十进制的255。Windows系统设置后重启才生效。
生存时间,就是一条域名解析记录在DNS服务器中的存留时间。当各地的DNS服务器接受到解析请求时,就会向域名指定的DNS服务器(权威域名服务器)发出解析请求从而获得解析记录;在获得这个记录之后,记录会在DNS服务器(各地的缓存服务器,也叫递归域名服务器)中保存一段时间,这段时间内如果再接到这个域名的解析请求,DNS服务器将不再向NS服务器发出请求,而是直接返回刚才获得的记录;而这个记录在DNS服务器上保留的时间,就是TTL值。主要有2个作用
1、防止数据包无限循环:在网络中,数据包可能会因为不正确的路由表等原因进入环路。
TTL值可以确保数据包在网络中传输一段时间或经过一定数量的路由器后被丢弃,避免数据包无限循环,从而防止网络资源被占用。
2、测量数据包传输路径:通过观察数据包在传输过程中TTL值的变化,可以大致判断出数据包从源到目的地经过的路由器数量,进而了解网络的延迟和稳定性。
工作原理
每当一个数据包经过一个路由器时,TTL的值会减1。
当TTL的值减到0时,路由器会丢弃该数据包,并发送一个“TTL超时”(Time Exceeded)的ICMP消息给数据包的源地址。不同操作系统默认TTL值
Windows:通常为128。
Linux/Unix:通常为64。
macOS:通常为64。
iOS:通常为64。
Android:通常为64。我们观察TTL
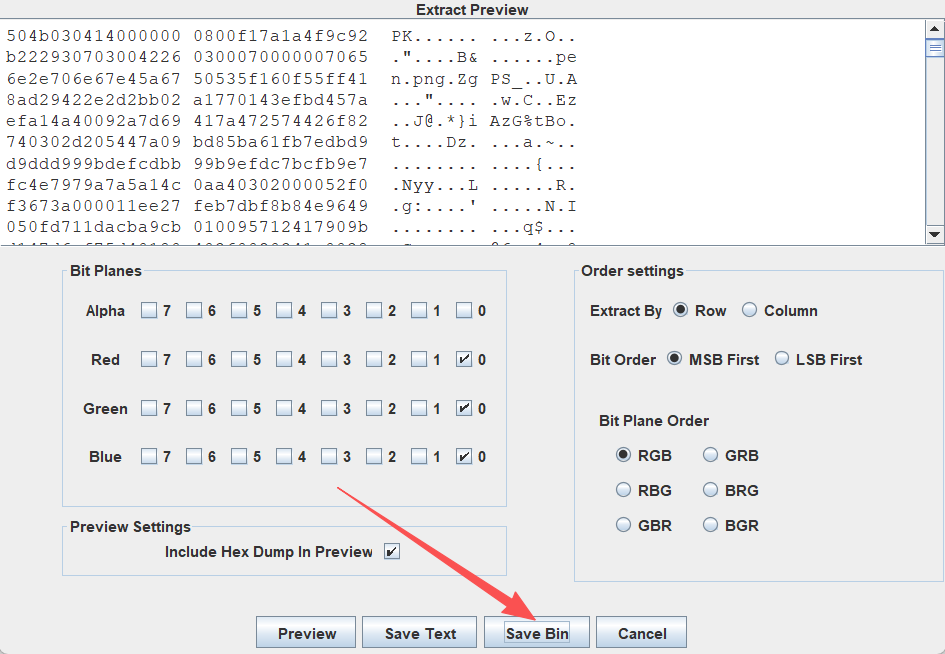
发现一个有295377行
只有255,63,191,127
先将这些十进制转换成二进制
255=11111111
63=00111111
191=10111111
127=01111111我们发现前两个数字不一样,后面6位都是一样的
所以将前两个数字提取出来,只有0和1所以可能是二维码 然后再转化ASCII
让AI写一个py3脚本
import os
# 读取文件内容
with open('ttl.txt', 'r') as file:
content = file.read()
# 提取TTL值
ttl_values = []
for line in content.strip().split('n'):
if line.startswith('TTL='):
ttl_values.append(int(line.split('=')[1]))
print(f"总共找到 {len(ttl_values)} 个TTL值")
# TTL到前两位二进制的映射
ttl_to_bits = {
255: '11', # 11111111 -> 11
63: '00', # 00111111 -> 00
191: '10', # 10111111 -> 10
127: '01' # 01111111 -> 01
}
# 转换为二进制并提取前两位
binary_string = ''
for ttl in ttl_values:
if ttl in ttl_to_bits:
binary_string += ttl_to_bits[ttl]
else:
print(f"警告: 未知的TTL值: {ttl}")
print(f"生成的二进制字符串长度: {len(binary_string)} 位")
# 将二进制字符串转换为十六进制
hex_data = ''
for i in range(0, len(binary_string), 8):
byte = binary_string[i:i+8]
if len(byte) == 8:
hex_byte = hex(int(byte, 2))[2:].zfill(2)
hex_data += hex_byte
print(f"生成的十六进制数据长度: {len(hex_data)//2} 字节")
# 保存结果到文件
with open('output_hex.txt', 'w') as f:
f.write(hex_data)
print(f"十六进制数据已保存到 output_hex.txt")
# 尝试将十六进制数据转换为ASCII
try:
ascii_text = bytes.fromhex(hex_data).decode('ascii', errors='ignore')
print("n尝试转换为ASCII文本:")
print(ascii_text[:500]) # 只显示前500个字符
with open('output_ascii.txt', 'w', encoding='utf-8') as f:
f.write(ascii_text)
print(f"ASCII文本已保存到 output_ascii.txt")
except Exception as e:
print(f"转换为ASCII时出错: {e}")
# 显示前100个字节的十六进制
print(f"n前100个字节的十六进制:")
for i in range(0, min(200, len(hex_data)), 32):
print(hex_data[i:i+32])
print(f"n处理完成!")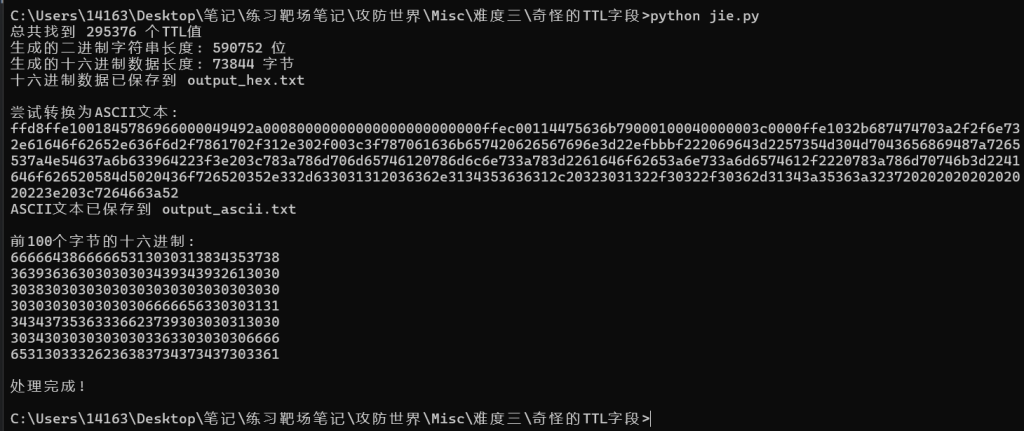
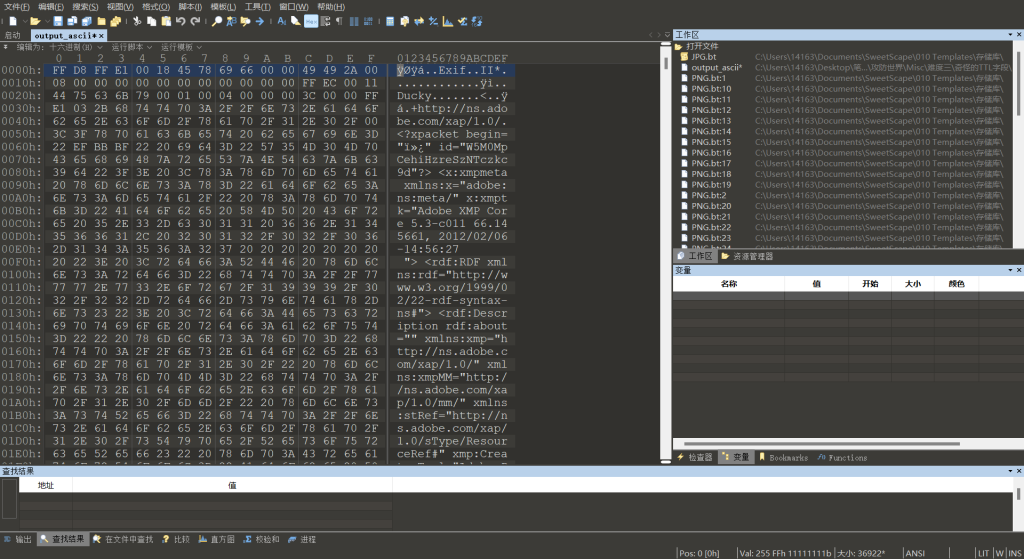
ffd8是jpg图片文件开头
然后010导入十六进制

保存

然后将这个图片进行foremost提取

按照2×3的网格进行拼接手动把图片改个名字好弄
py3代码
from PIL import Image
# 读取6个碎片图片
images = [Image.open(f'{i}.jpg') for i in range(1, 7)]
# 获取单个碎片的尺寸
width, height = images[0].size
# 创建2行3列的画布
result = Image.new('RGB', (width * 3, height * 2))
# 按照顺序拼接
# 第一行:1, 2, 3
result.paste(images[0], (0, 0))
result.paste(images[1], (width, 0))
result.paste(images[2], (width * 2, 0))
# 第二行:4, 5, 6
result.paste(images[3], (0, height))
result.paste(images[4], (width, height))
result.paste(images[5], (width * 2, height))
# 保存结果
result.save('qr_code_combined.jpg')
print('二维码拼接完成:qr_code_combined.jpg')
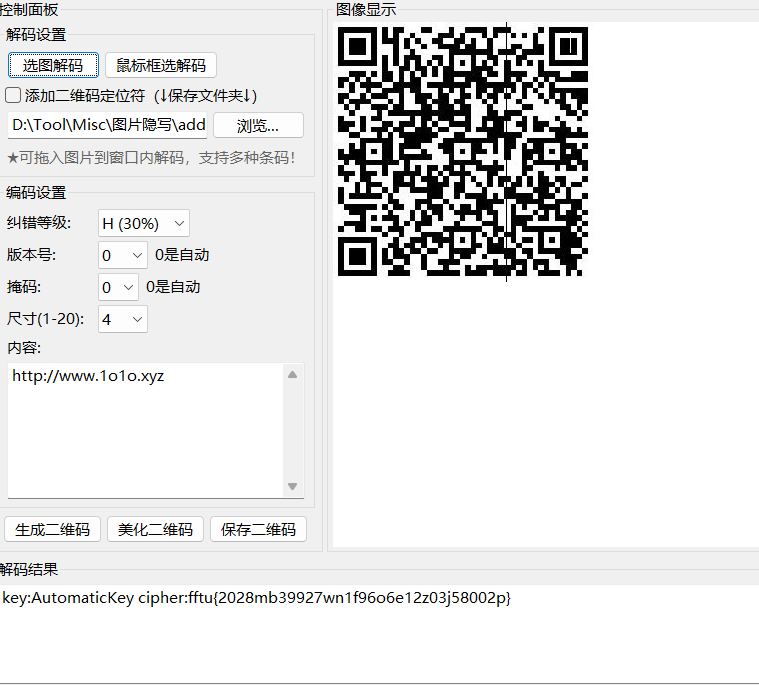
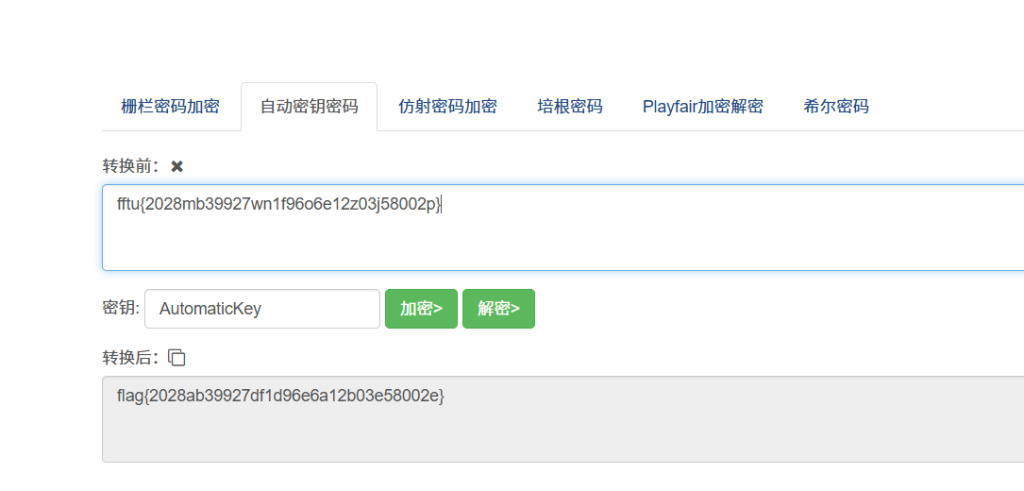
key:AutomaticKey cipher:fftu{2028mb39927wn1f96o6e12z03j58002p}维吉尼亚解密

flag{2028ab39927df1d96e6a12b03j58002v}
?不对
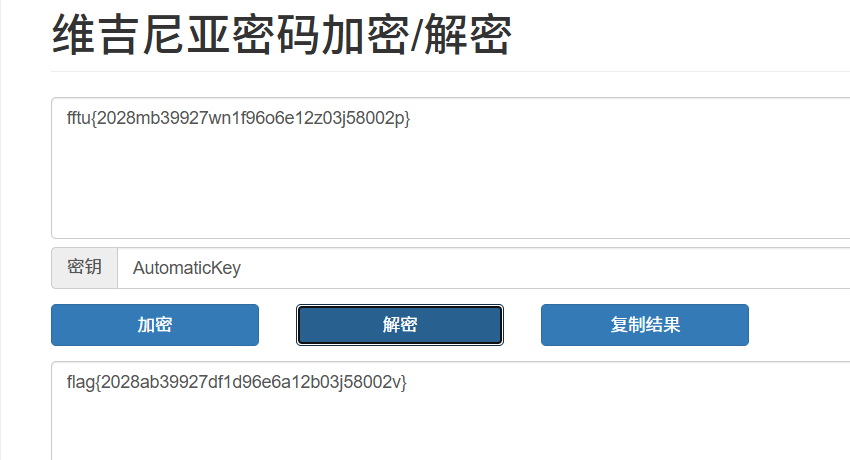
看来不是维吉尼亚,AutomaticKey 是自动密钥密码
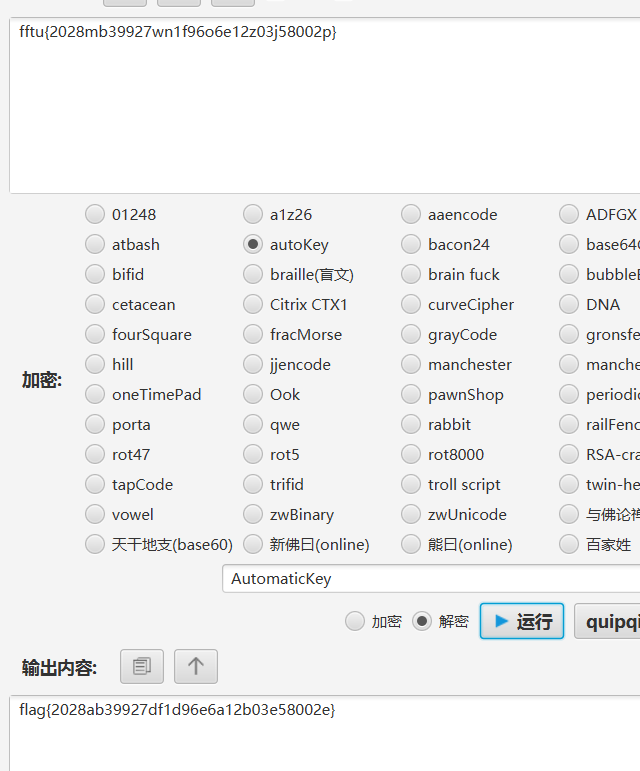
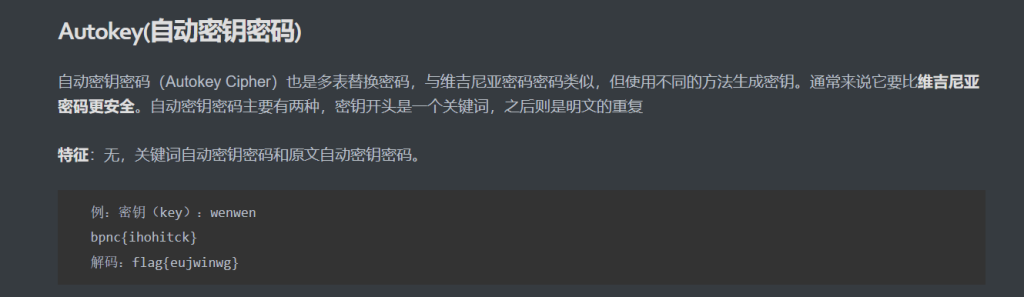
网站自动密钥密码_Autokey Cipher-ME2在线工具
flag{2028ab39927df1d96e6a12b03e58002e} 21.隐藏的信息
题目内容
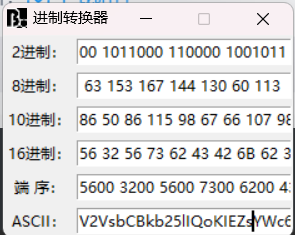
0126 062 0126 0163 0142 0103 0102 0153 0142 062 065 0154 0111 0121 0157 0113 0111 0105 0132 0163 0131 0127 0143 066 0111 0105 0154 0124 0121 060 0116 067 0124 0152 0102 0146 0115 0107 065 0154 0130 062 0116 0150 0142 0154 071 0172 0144 0104 0102 0167 0130 063 0153 0167 0144 0130 060 0113 发现前面都有0把0全部去掉
126 62 126 163 142 103 102 153 142 62 65 154 111 121 157 113 111 105 132 163 131 127 143 66 111 105 154 124 121 60 116 67 124 152 102 146 115 107 65 154 130 62 116 150 142 154 71 172 144 104 102 167 130 63 153 167 144 130 60 113 八进制转成ASCII
V2VsbCBkb25lIQoKIEZsYWc6IElTQ0N7TjBfMG5lX2Nhbl9zdDBwX3kwdX0Kbase64解密
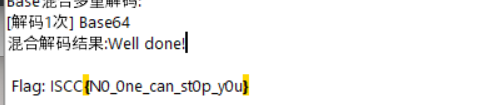
ISCC{N0_0ne_can_st0p_y0u}22.Keyes_secret
RFVGYHNWSXCDEWSXCVWSXCVTGBNMJUY,WSXZAQWDVFRQWERTYTRFVBTGBNMJUYXSWEFTYHNNBVCXSWERFTGBNMJUTYUIOJMWSXCDEMNBVCDRTGHUQWERTYIUYHNBVWSXCDETRFVBTGBNMJUMNBVCDRTGHUWSXTYUIOJMEFVT,QWERTYTRFVBGRDXCVBNBVCXSWERFTYUIOJMTGBNMJUMNBVCDRTGHUWSXCDEQWERTYTYUIOJMRFVGYHNWSXCDEQWERTYTRFVGWSXCVGRDXCVBCVGREDQWERTY(TRFVBTYUIOJMTRFVG),QWERTYGRDXCVBQWERTYTYUIOJMEFVTNBVCXSWERFWSXCDEQWERTYTGBNMJUYTRFVGQWERTYTRFVBMNBVCDRTGHUEFVTNBVCXSWERFTYUIOJMTGBNMJUYIUYHNBVNBVCXSWERFTGBNMJUYMNBVCDRTGHUTYUIOJM,QWERTYWSXIUYHNBVQWERTYGRDXCVBQWERTYTRFVBTGBNMJUYXSWEFTYHNNBVCXSWERFTGBNMJUTYUIOJMWSXCDEMNBVCDRTGHUQWERTYIUYHNBVWSXCDETRFVBTGBNMJUMNBVCDRTGHUWSXTYUIOJMEFVTQWERTYTRFVBTGBNMJUYXSWEFTYHNNBVCXSWERFWSXCDETYUIOJMWSXTYUIOJMWSXTGBNMJUYZAQWDVFR.QWERTYTRFVBTYUIOJMTRFVGQWERTYTRFVBTGBNMJUYZAQWDVFRTYUIOJMWSXCDEIUYHNBVTYUIOJMIUYHNBVQWERTYGRDXCVBMNBVCDRTGHUWSXCDEQWERTYTGBNMJUIUYHNBVTGBNMJUGRDXCVBWSXCVWSXCVEFVTQWERTYWSXCFEWSXCDEIUYHNBVWSXCVGREDZAQWDVFRWSXCDEWSXCFEQWERTYTYUIOJMTGBNMJUYQWERTYIUYHNBVWSXCDEMNBVCDRTGHUEFVGYWSXCDEQWERTYGRDXCVBIUYHNBVQWERTYGRDXCVBZAQWDVFRQWERTYWSXCDEWSXCFETGBNMJUTRFVBGRDXCVBTYUIOJMWSXTGBNMJUYZAQWDVFRGRDXCVBWSXCVQWERTYWSXCDERGNYGCWSXCDEMNBVCDRTGHUTRFVBWSXIUYHNBVWSXCDEQWERTYTYUIOJMTGBNMJUYQWERTYCVGREDWSXEFVGYWSXCDEQWERTYNBVCXSWERFGRDXCVBMNBVCDRTGHUTYUIOJMWSXTRFVBWSXNBVCXSWERFGRDXCVBZAQWDVFRTYUIOJMIUYHNBVQWERTYWSXCDERGNYGCNBVCXSWERFWSXCDEMNBVCDRTGHUWSXWSXCDEZAQWDVFRTRFVBWSXCDEQWERTYWSXZAQWDVFRQWERTYIUYHNBVWSXCDETRFVBTGBNMJUMNBVCDRTGHUWSXZAQWDVFRCVGREDQWERTYGRDXCVBQWERTYXSWEFTYHNGRDXCVBTRFVBRFVGYHNWSXZAQWDVFRWSXCDE,QWERTYGRDXCVBIUYHNBVQWERTYEFVGYWDCFTWSXCDEWSXCVWSXCVQWERTYGRDXCVBIUYHNBVQWERTYTRFVBTGBNMJUYZAQWDVFRWSXCFETGBNMJUTRFVBTYUIOJMWSXZAQWDVFRCVGREDQWERTYGRDXCVBZAQWDVFRWSXCFEQWERTYMNBVCDRTGHUWSXCDEGRDXCVBTRFVBTYUIOJMWSXZAQWDVFRCVGREDQWERTYTYUIOJMTGBNMJUYQWERTYTYUIOJMRFVGYHNWSXCDEQWERTYIUYHNBVTGBNMJUYMNBVCDRTGHUTYUIOJMQWERTYTGBNMJUYTRFVGQWERTYGRDXCVBTYUIOJMTYUIOJMGRDXCVBTRFVBQAZSCEIUYHNBVQWERTYTRFVGTGBNMJUYTGBNMJUZAQWDVFRWSXCFEQWERTYWSXZAQWDVFRQWERTYTYUIOJMRFVGYHNWSXCDEQWERTYMNBVCDRTGHUWSXCDEGRDXCVBWSXCVQWERTYEFVGYWDCFTTGBNMJUYMNBVCDRTGHUWSXCVWSXCFEQWERTY(WSX.WSXCDE.,QWERTYYHNMKJTGBNMJUCVGREDQWERTYYHNMKJTGBNMJUYTGBNMJUZAQWDVFRTYUIOJMEFVTQWERTYNBVCXSWERFMNBVCDRTGHUTGBNMJUYCVGREDMNBVCDRTGHUGRDXCVBXSWEFTYHNIUYHNBVQWERTYWSXZAQWDVFRQWERTYNBVCXSWERFMNBVCDRTGHUTGBNMJUYTRFVGWSXCDEIUYHNBVIUYHNBVWSXTGBNMJUYZAQWDVFRGRDXCVBWSXCVQWERTYIUYHNBVWSXCDETYUIOJMTYUIOJMWSXZAQWDVFRCVGREDIUYHNBV).QWERTYRFVGYHNWSXCDEMNBVCDRTGHUWSXCDEQWERTYGRDXCVBMNBVCDRTGHUWSXCDEQWERTYEFVTTGBNMJUYTGBNMJUMNBVCDRTGHUQWERTYTRFVGWSXCVGRDXCVBCVGRED{WSXIUYHNBVTRFVBTRFVBQWERTYQAZSCEWSXCDEEFVTYHNMKJTGBNMJUYGRDXCVBMNBVCDRTGHUWSXCFEQWERTYTRFVBWSXNBVCXSWERFRFVGYHNWSXCDEMNBVCDRTGHU}QWERTYMNBVCDRTGHUWSXCDEEFVGYWSXCDEMNBVCDRTGHUIUYHNBVWSXCDE-WSXCDEZAQWDVFRCVGREDWSXZAQWDVFRWSXCDEWSXCDEMNBVCDRTGHUWSXZAQWDVFRCVGRED,QWERTYZAQWDVFRWSXCDETYUIOJMEFVGYWDCFTTGBNMJUYMNBVCDRTGHUQAZSCEQWERTYIUYHNBVZAQWDVFRWSXTRFVGTRFVGWSXZAQWDVFRCVGRED,QWERTYNBVCXSWERFMNBVCDRTGHUTGBNMJUYTYUIOJMTGBNMJUYTRFVBTGBNMJUYWSXCVQWERTYGRDXCVBZAQWDVFRGRDXCVBWSXCVEFVTIUYHNBVWSXIUYHNBV,QWERTYIUYHNBVEFVTIUYHNBVTYUIOJMWSXCDEXSWEFTYHNQWERTYGRDXCVBWSXCFEXSWEFTYHNWSXZAQWDVFRWSXIUYHNBVTYUIOJMMNBVCDRTGHUGRDXCVBTYUIOJMWSXTGBNMJUYZAQWDVFR,QWERTYNBVCXSWERFMNBVCDRTGHUTGBNMJUYCVGREDMNBVCDRTGHUGRDXCVBXSWEFTYHNXSWEFTYHNWSXZAQWDVFRCVGRED,QWERTYGRDXCVBZAQWDVFRWSXCFEQWERTYTRFVBMNBVCDRTGHUEFVTNBVCXSWERFTYUIOJMGRDXCVBZAQWDVFRGRDXCVBWSXCVEFVTIUYHNBVWSXIUYHNBVQWERTYGRDXCVBMNBVCDRTGHUWSXCDEQWERTYGRDXCVBWSXCVWSXCVQWERTYIUYHNBVQAZSCEWSXWSXCVWSXCVIUYHNBVQWERTYEFVGYWDCFTRFVGYHNWSXTRFVBRFVGYHNQWERTYRFVGYHNGRDXCVBEFVGYWSXCDEQWERTYYHNMKJWSXCDEWSXCDEZAQWDVFRQWERTYMNBVCDRTGHUWSXCDEQAZXCDEWVTGBNMJUWSXMNBVCDRTGHUWSXCDEWSXCFEQWERTYYHNMKJEFVTQWERTYNBVCXSWERFMNBVCDRTGHUWSXTGBNMJUYMNBVCDRTGHUQWERTYTRFVBTYUIOJMTRFVGQWERTYTRFVBTGBNMJUYZAQWDVFRTYUIOJMWSXCDEIUYHNBVTYUIOJMIUYHNBVQWERTYGRDXCVBTYUIOJMQWERTYWSXCFEWSXCDETRFVGQWERTYTRFVBTGBNMJUYZAQWDVFR.“QWERTY”、“WSX”、“RFVG”等这样的序列逗号隔开是应该是键盘解密
{WSXIUYHNBVTRFVBTRFVBQWERTYQAZSCEWSXCDEEFVTYHNMKJTGBNMJUYGRDXCVBMNBVCDRTGHUWSXCFEQWERTYTRFVBWSXNBVCXSWERFRFVGYHNWSXCDEMNBVCDRTGHU}
这个应该是flag内容
然后摸索字符看键盘
比如WSX在键盘看着像I IUYHNBV 像S或者Z ,然后记录写一个脚本
"RFVGYHN": "h",
"TGBNMJUY": "o",
"NBVCXSWERF": "p",
"TGBNMJU": "u",
"IUYHNBV": "s",
"TRFVB": "c",
"QWERTY": "-",
"QAZSCE": "k",
"WSXCDE": "e",
"WSXCFE": "d",
"EFVT": "y",
"YHNMKJ": "b",
"GRDXCVB": "a",
"MNBVCDRTGHU": "r",
"WSXCV": "l",
"CVGRED": "g",
"WSX": "i",
"TRFVG": "f",
"EFVGYWDCFT": "w",
"ZAQWDVFR": "n",
"TYUIOJM": "t",
"XSWEFTYHN": "m",
"RGNYGC": "x",
"EFVGY": "v",
"QAZXCDEWV": "q"py3脚本
# 读取文件内容
with open("keyes.txt", "r") as file:
ciphertext = file.read()
# 定义键盘映射字典
mapping = {
"RFVGYHN": "h",
"TGBNMJUY": "o",
"NBVCXSWERF": "p",
"TGBNMJU": "u",
"IUYHNBV": "s",
"TRFVB": "c",
"QWERTY": "-",
"QAZSCE": "k",
"WSXCDE": "e",
"WSXCFE": "d",
"EFVT": "y",
"YHNMKJ": "b",
"GRDXCVB": "a",
"MNBVCDRTGHU": "r",
"WSXCV": "l",
"CVGRED": "g",
"WSX": "i",
"TRFVG": "f",
"EFVGYWDCFT": "w",
"ZAQWDVFR": "n",
"TYUIOJM": "t",
"XSWEFTYHN": "m",
"RGNYGC": "x",
"EFVGY": "v",
"QAZXCDEWV": "q"
}
# 按密钥长度从长到短排序,避免替换冲突
sorted_keys = sorted(mapping.keys(), key=len, reverse=True)
# 执行替换
for key in sorted_keys:
ciphertext = ciphertext.replace(key, mapping[key])
# 输出解密结果
print("解密后的文本:")
print(ciphertext)
print("n" + "="*50 + "n")
# 提取并显示flag
import re
flag_match = re.search(r'{([^}]+)}', ciphertext)
if flag_match:
flag = flag_match.group(1)
print(f"提取到的Flag: {flag}")
else:
print("未找到Flag格式的内容")
hello,in-computer-security,-capture-the-flag-(ctf),-a-type-of-cryptosport,-is-a-computer-security-competition.-ctf-contests-are-usually-designed-to-serve-as-an-educational-exercise-to-give-participants-experience-in-securing-a-machine,-as-well-as-conducting-and-reacting-to-the-sort-of-attacks-found-in-the-real-world-(i.e.,-bug-bounty-programs-in-professional-settings).-here-are-your-flag{iscc-keyboard-cipher}-reverse-engineering,-network-sniffing,-protocol-analysis,-system-administration,-programming,-and-cryptanalysis-are-all-skills-which-have-been-required-by-prior-ctf-contests-at-def-con.翻译:
你好,在计算机安全中,Capture The Flag(CTF)是一种密码运动类型,是一种计算机安全竞赛。CTF 竞赛通常被设计为教育练习,旨在让参与者获得保护计算机的经验,以及进行和应对现实世界攻击的能力(例如,专业环境中的漏洞赏金计划)。这里是你的 flag{iscc-keyboard-cipher}。逆向工程、网络嗅探、协议分析、系统管理、编程和密码分析都是以往 DEF CON CTF 比赛中所要求的技能。flag{iscc-keyboard-cipher}
大写:
FLAG{ISCC-KEYBOARD-CIPHER}23.saleae
文件:.logicdata
.logicdata这个文件没有见过网上搜索
.logicdata文件是与Saleae逻辑分析仪相关的数据文件,用于记录和分析数字信号。单片机里面会用到
文件类型和用途
.logicdata文件是Saleae逻辑分析仪生成的文件格式,主要用于记录、查看和测量数字信号。这种文件通常包含采样数据,用户可以使用Saleae软件对其进行分析和解码。下载:Saleae
下载链接https://downloads.saleae.com/logic/1.2.18/Logic+1.2.18+Win+64+Standalone.zip
选择文件
选择spi添加分析器
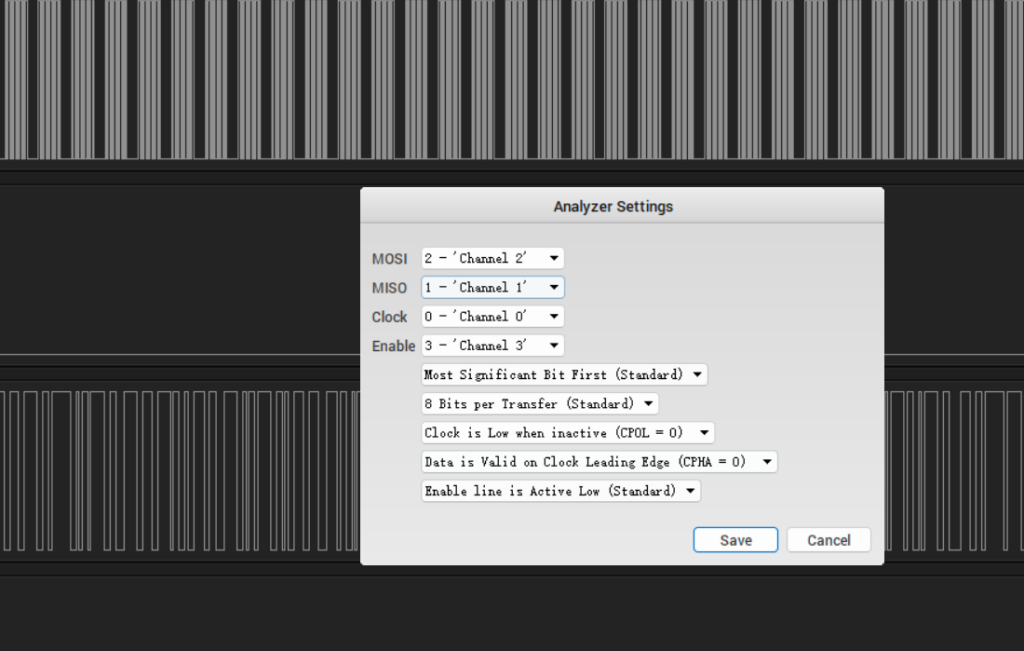
发现flag
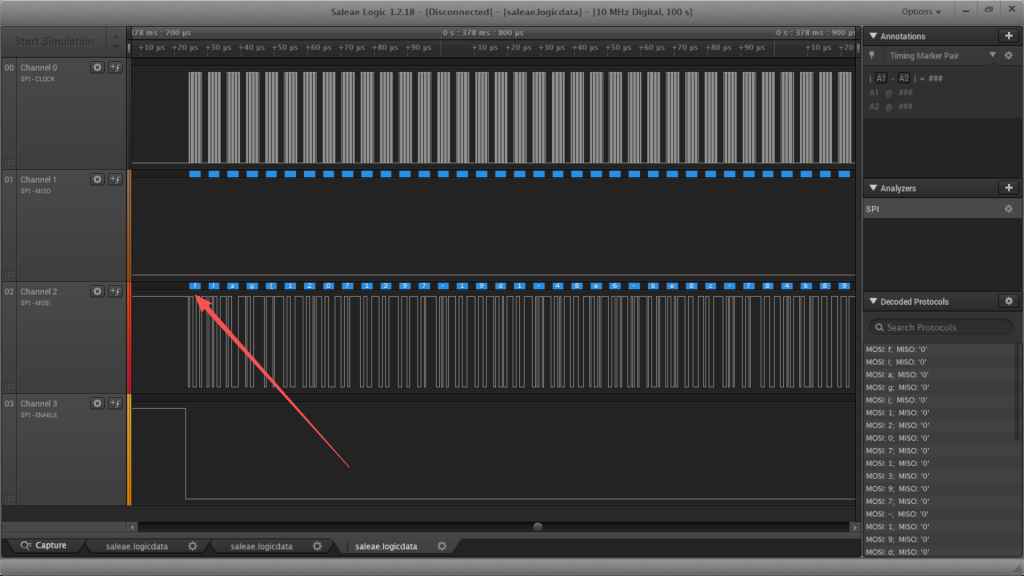
flag{12071397-19d1-48e6-be8c-784b89a95e07}24.信号不好先挂了

是一个图片
LSB分析一下
Stegsolve分析
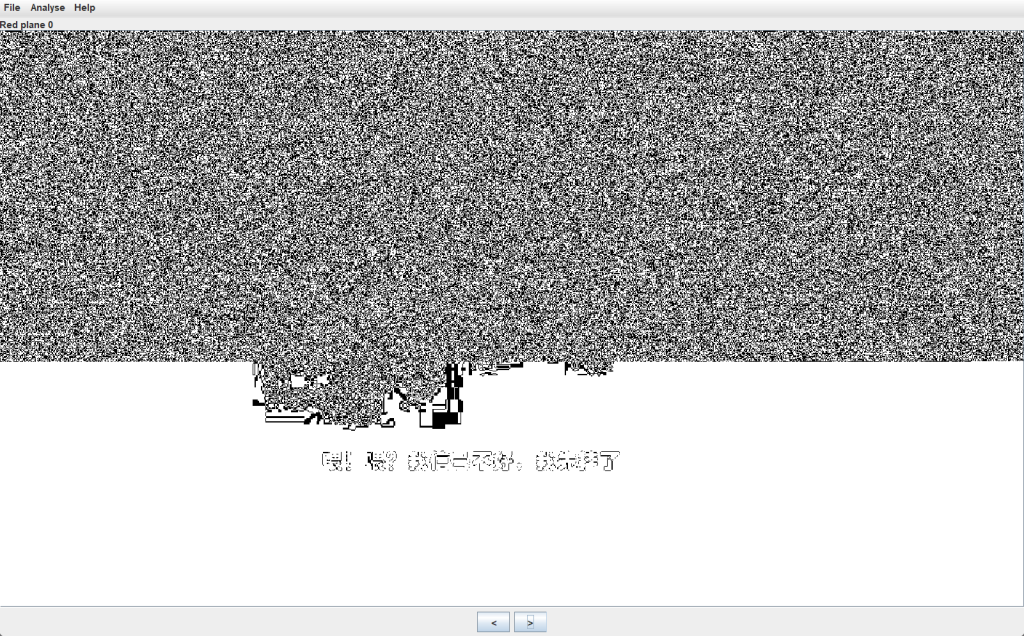
发现0通道有东西
RGB有一个压缩包.zip导出来
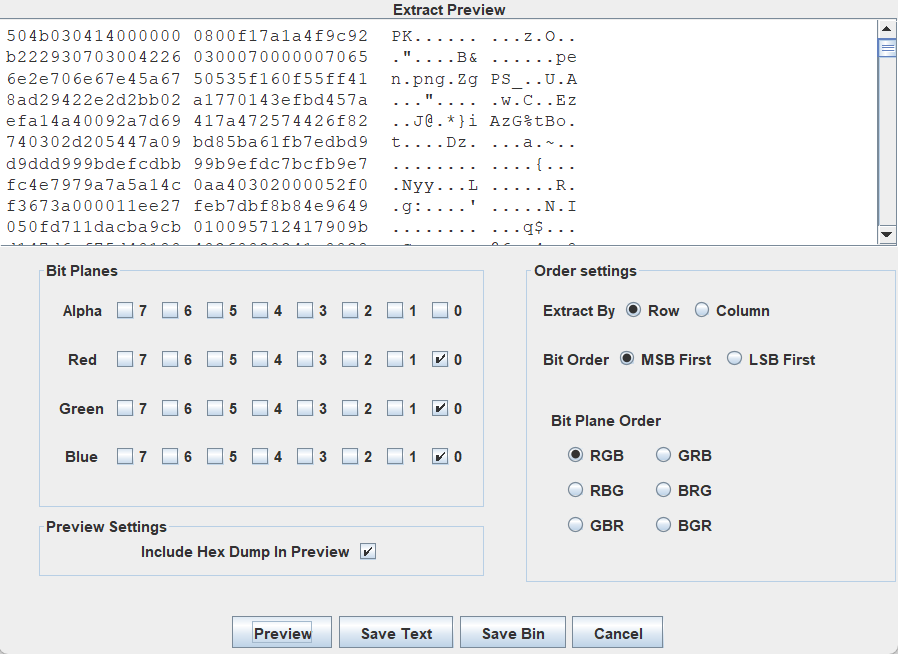

是一个相似的图片所以盲水印

python bwmforpy3.py decode --oldseed apple.png pen.png 1.png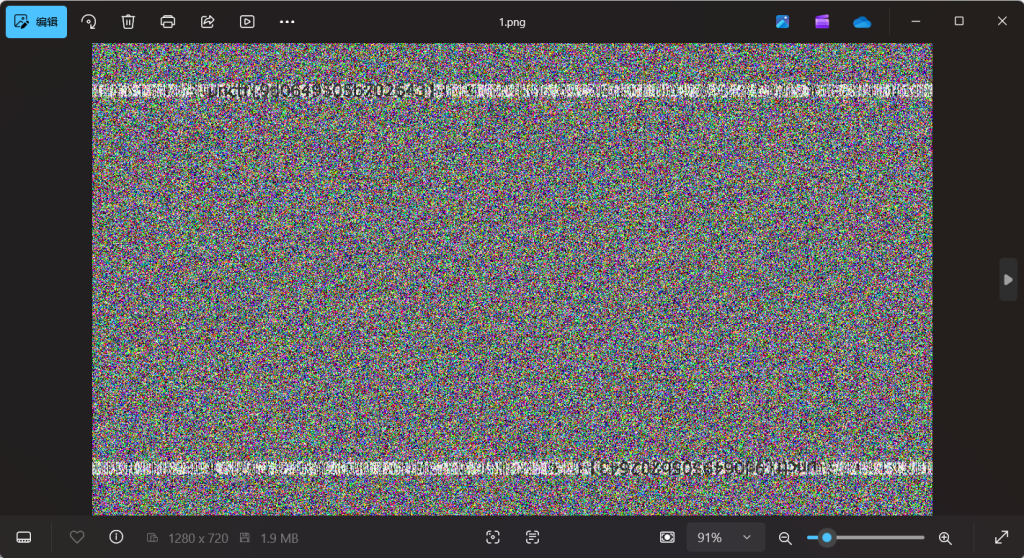
unctf{9d0649505b702643}总结:学到好多其他类型的隐写,但是真的好多盲水印,见到两个图片就是双图片盲水印,有点难度,如果有问题评论区指出,制作不易